chacha20-0.9.1/.cargo_vcs_info.json�����������������������������������������������������������������0000644�����������������00000000146�00000000001�0012415�0����������������������������������������������������������������������������������������������������ustar ��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������{
"git": {
"sha1": "b5d39c45c45df97335f4b6effb853cde97810de1"
},
"path_in_vcs": "chacha20"
}��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/CHANGELOG.md�������������������������������������������������������������������������0000644�0000000�0000000�00000017077�10461020230�0013031�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/)
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## 0.9.1 (2023-04-01)
### Added
- NEON support via `chacha20_force_neon` cfg attribute ([#310], [#317])
[#310]: https://github.com/RustCrypto/stream-ciphers/pull/310
[#317]: https://github.com/RustCrypto/stream-ciphers/pull/317
## 0.9.0 (2022-02-21)
### Added
- `chacha20_force_soft`, `chacha20_force_sse2`, and `chacha20_force_avx2`
configuration flags ([#293])
### Changed
- Bump `cipher` dependency to v0.4 ([#276])
### Fixed
- Minimal versions build ([#290])
### Removed
- `neon`, `force-soft`, `expose-core`, `hchacha`, `legacy`, and `rng` features ([#276], [#293])
[#276]: https://github.com/RustCrypto/stream-ciphers/pull/276
[#290]: https://github.com/RustCrypto/stream-ciphers/pull/290
[#293]: https://github.com/RustCrypto/stream-ciphers/pull/293
## 0.8.2 (2022-07-07)
### Changed
- Unpin `zeroize` dependency ([#301])
[#301]: https://github.com/RustCrypto/stream-ciphers/pull/301
## 0.8.1 (2021-08-30)
### Added
- NEON implementation for aarch64 ([#274])
[#274]: https://github.com/RustCrypto/stream-ciphers/pull/274
## 0.8.0 (2021-08-29)
### Added
- SSE2 autodetection support ([#270])
### Changed
- AVX2 performance improvements ([#267], [#267])
- MSRV 1.51+ ([#267])
- Lock to `zeroize` <1.5 ([#269])
### Removed
- `xchacha` feature: all `XChaCha*` types are now available by-default ([#271])
[#267]: https://github.com/RustCrypto/stream-ciphers/pull/267
[#269]: https://github.com/RustCrypto/stream-ciphers/pull/269
[#270]: https://github.com/RustCrypto/stream-ciphers/pull/270
[#271]: https://github.com/RustCrypto/stream-ciphers/pull/271
## 0.7.3 (2021-08-27)
### Changed
- Improve AVX2 performance ([#261])
- Bump `cpufeatures` to v0.2 ([#265])
[#261]: https://github.com/RustCrypto/stream-ciphers/pull/261
[#265]: https://github.com/RustCrypto/stream-ciphers/pull/265
## 0.7.2 (2021-07-20)
### Changed
- Pin `zeroize` dependency to v1.3 ([#256])
[#256]: https://github.com/RustCrypto/stream-ciphers/pull/256
## 0.7.1 (2021-04-29)
### Added
- `hchacha` feature ([#234])
[#234]: https://github.com/RustCrypto/stream-ciphers/pull/234
## 0.7.0 (2021-04-29) [YANKED]
### Added
- AVX2 detection; MSRV 1.49+ ([#200], [#212])
- `XChaCha8` and `XChaCha12` ([#215])
### Changed
- Full 64-bit counters ([#217])
- Bump `cipher` crate dependency to v0.3 release ([#226])
### Fixed
- `rng` feature on big endian platforms ([#202])
- Stream-length overflow check ([#216])
### Removed
- `Clone` impls on RNGs ([#220])
[#200]: https://github.com/RustCrypto/stream-ciphers/pull/200
[#202]: https://github.com/RustCrypto/stream-ciphers/pull/202
[#212]: https://github.com/RustCrypto/stream-ciphers/pull/212
[#215]: https://github.com/RustCrypto/stream-ciphers/pull/215
[#216]: https://github.com/RustCrypto/stream-ciphers/pull/216
[#217]: https://github.com/RustCrypto/stream-ciphers/pull/217
[#220]: https://github.com/RustCrypto/stream-ciphers/pull/220
[#226]: https://github.com/RustCrypto/stream-ciphers/pull/226
## 0.6.0 (2020-10-16)
### Changed
- Rename `Cipher` to `ChaCha` ([#177])
- Replace `block-cipher`/`stream-cipher` with `cipher` crate ([#177])
[#177]: https://github.com/RustCrypto/stream-ciphers/pull/177
## 0.5.0 (2020-08-25)
### Changed
- Bump `stream-cipher` dependency to v0.7 ([#161], [#164])
[#161]: https://github.com/RustCrypto/stream-ciphers/pull/161
[#164]: https://github.com/RustCrypto/stream-ciphers/pull/164
## 0.4.3 (2020-06-11)
### Changed
- Documentation improvements ([#153], [#154], [#155])
[#153]: https://github.com/RustCrypto/stream-ciphers/pull/155
[#154]: https://github.com/RustCrypto/stream-ciphers/pull/155
[#155]: https://github.com/RustCrypto/stream-ciphers/pull/155
## 0.4.2 (2020-06-11)
### Added
- Documentation improvements ([#149])
- `Key`, `Nonce`, `XNonce`, and `LegacyNonce` type aliases ([#147])
[#149]: https://github.com/RustCrypto/stream-ciphers/pull/149
[#147]: https://github.com/RustCrypto/stream-ciphers/pull/147
## 0.4.1 (2020-06-06)
### Fixed
- Links in documentation ([#142])
[#142]: https://github.com/RustCrypto/stream-ciphers/pull/142
## 0.4.0 (2020-06-06)
### Changed
- Upgrade to the `stream-cipher` v0.4 crate ([#121], [#138])
[#138]: https://github.com/RustCrypto/stream-ciphers/pull/138
[#121]: https://github.com/RustCrypto/stream-ciphers/pull/121
## 0.3.4 (2020-03-02)
### Fixed
- Avoid accidental `alloc` and `std` linking ([#105])
[#105]: https://github.com/RustCrypto/stream-ciphers/pull/105
## 0.3.3 (2020-01-18)
### Changed
- Replace macros with `Rounds` trait + generics ([#100])
### Fixed
- Fix warnings when building with `rng` feature alone ([#99])
[#99]: https://github.com/RustCrypto/stream-ciphers/pull/99
[#100]: https://github.com/RustCrypto/stream-ciphers/pull/100
## 0.3.2 (2020-01-17)
### Added
- `CryptoRng` marker on all `ChaCha*Rng` types ([#91])
[#91]: https://github.com/RustCrypto/stream-ciphers/pull/91
## 0.3.1 (2020-01-16)
### Added
- Parallelize AVX2 backend ([#87])
- Benchmark for `ChaCha20Rng` ([#87])
### Fixed
- Fix broken buffering logic ([#86])
[#86]: https://github.com/RustCrypto/stream-ciphers/pull/86
[#87]: https://github.com/RustCrypto/stream-ciphers/pull/87
## 0.3.0 (2020-01-15) [YANKED]
NOTE: This release was yanked due to a showstopper bug in the newly added
buffering logic which when seeking in the keystream could result in plaintexts
being clobbered with the keystream instead of XOR'd correctly.
The bug was addressed in v0.3.1 ([#86]).
### Added
- AVX2 accelerated implementation ([#83])
- ChaCha8 and ChaCha20 reduced round variants ([#84])
### Changed
- Simplify portable implementation ([#76])
- Make 2018 edition crate; MSRV 1.34+ ([#77])
- Replace `salsa20-core` dependency with `ctr`-derived buffering ([#81])
### Removed
- `byteorder` dependency ([#80])
[#76]: https://github.com/RustCrypto/stream-ciphers/pull/76
[#77]: https://github.com/RustCrypto/stream-ciphers/pull/77
[#80]: https://github.com/RustCrypto/stream-ciphers/pull/80
[#81]: https://github.com/RustCrypto/stream-ciphers/pull/81
[#83]: https://github.com/RustCrypto/stream-ciphers/pull/83
[#84]: https://github.com/RustCrypto/stream-ciphers/pull/84
## 0.2.3 (2019-10-23)
### Security
- Ensure block counter < MAX_BLOCKS ([#68])
[#68]: https://github.com/RustCrypto/stream-ciphers/pull/68
## 0.2.2 (2019-10-22)
### Added
- SSE2 accelerated implementation ([#61])
[#61]: https://github.com/RustCrypto/stream-ciphers/pull/61
## 0.2.1 (2019-08-19)
### Added
- Add `MAX_BLOCKS` and `BLOCK_SIZE` constants ([#47])
[#47]: https://github.com/RustCrypto/stream-ciphers/pull/47
## 0.2.0 (2019-08-18)
### Added
- `impl SyncStreamCipher` ([#39])
- `XChaCha20` ([#36])
- Support for 12-byte nonces ala RFC 8439 ([#19])
### Changed
- Refactor around a `ctr`-like type ([#44])
- Extract and encapsulate `Cipher` type ([#43])
- Switch tests to use `new_sync_test!` ([#42])
- Refactor into `ChaCha20` and `ChaCha20Legacy` ([#25])
### Fixed
- Fix `zeroize` cargo feature ([#21])
- Fix broken Cargo feature attributes ([#21])
[#44]: https://github.com/RustCrypto/stream-ciphers/pull/44
[#43]: https://github.com/RustCrypto/stream-ciphers/pull/43
[#42]: https://github.com/RustCrypto/stream-ciphers/pull/42
[#39]: https://github.com/RustCrypto/stream-ciphers/pull/39
[#36]: https://github.com/RustCrypto/stream-ciphers/pull/36
[#25]: https://github.com/RustCrypto/stream-ciphers/pull/25
[#21]: https://github.com/RustCrypto/stream-ciphers/pull/21
[#19]: https://github.com/RustCrypto/stream-ciphers/pull/19
## 0.1.0 (2019-06-24)
- Initial release
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/Cargo.toml���������������������������������������������������������������������������0000644�����������������00000003306�00000000001�0010414�0����������������������������������������������������������������������������������������������������ustar ��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������# THIS FILE IS AUTOMATICALLY GENERATED BY CARGO
#
# When uploading crates to the registry Cargo will automatically
# "normalize" Cargo.toml files for maximal compatibility
# with all versions of Cargo and also rewrite `path` dependencies
# to registry (e.g., crates.io) dependencies.
#
# If you are reading this file be aware that the original Cargo.toml
# will likely look very different (and much more reasonable).
# See Cargo.toml.orig for the original contents.
[package]
edition = "2021"
rust-version = "1.56"
name = "chacha20"
version = "0.9.1"
authors = ["RustCrypto Developers"]
description = """
The ChaCha20 stream cipher (RFC 8439) implemented in pure Rust using traits
from the RustCrypto `cipher` crate, with optional architecture-specific
hardware acceleration (AVX2, SSE2). Additionally provides the ChaCha8, ChaCha12,
XChaCha20, XChaCha12 and XChaCha8 stream ciphers, and also optional
rand_core-compatible RNGs based on those ciphers.
"""
documentation = "https://docs.rs/chacha20"
readme = "README.md"
keywords = [
"crypto",
"stream-cipher",
"chacha8",
"chacha12",
"xchacha20",
]
categories = [
"cryptography",
"no-std",
]
license = "Apache-2.0 OR MIT"
repository = "https://github.com/RustCrypto/stream-ciphers"
resolver = "1"
[package.metadata.docs.rs]
all-features = true
rustdoc-args = [
"--cfg",
"docsrs",
]
[dependencies.cfg-if]
version = "1"
[dependencies.cipher]
version = "0.4.4"
[dev-dependencies.cipher]
version = "0.4.4"
features = ["dev"]
[dev-dependencies.hex-literal]
version = "0.3.3"
[features]
std = ["cipher/std"]
zeroize = ["cipher/zeroize"]
[target."cfg(any(target_arch = \"x86_64\", target_arch = \"x86\"))".dependencies.cpufeatures]
version = "0.2"
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/Cargo.toml.orig����������������������������������������������������������������������0000644�0000000�0000000�00000002166�10461020230�0014100�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������[package]
name = "chacha20"
version = "0.9.1"
description = """
The ChaCha20 stream cipher (RFC 8439) implemented in pure Rust using traits
from the RustCrypto `cipher` crate, with optional architecture-specific
hardware acceleration (AVX2, SSE2). Additionally provides the ChaCha8, ChaCha12,
XChaCha20, XChaCha12 and XChaCha8 stream ciphers, and also optional
rand_core-compatible RNGs based on those ciphers.
"""
authors = ["RustCrypto Developers"]
license = "Apache-2.0 OR MIT"
edition = "2021"
rust-version = "1.56"
readme = "README.md"
documentation = "https://docs.rs/chacha20"
repository = "https://github.com/RustCrypto/stream-ciphers"
keywords = ["crypto", "stream-cipher", "chacha8", "chacha12", "xchacha20"]
categories = ["cryptography", "no-std"]
[dependencies]
cfg-if = "1"
cipher = "0.4.4"
[target.'cfg(any(target_arch = "x86_64", target_arch = "x86"))'.dependencies]
cpufeatures = "0.2"
[dev-dependencies]
cipher = { version = "0.4.4", features = ["dev"] }
hex-literal = "0.3.3"
[features]
std = ["cipher/std"]
zeroize = ["cipher/zeroize"]
[package.metadata.docs.rs]
all-features = true
rustdoc-args = ["--cfg", "docsrs"]
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/LICENSE-APACHE�����������������������������������������������������������������������0000644�0000000�0000000�00000025141�10461020230�0013133�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������ Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/LICENSE-MIT��������������������������������������������������������������������������0000644�0000000�0000000�00000002072�10461020230�0012641�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Copyright (c) 2019-2023 The RustCrypto Project Developers
Permission is hereby granted, free of charge, to any
person obtaining a copy of this software and associated
documentation files (the "Software"), to deal in the
Software without restriction, including without
limitation the rights to use, copy, modify, merge,
publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software
is furnished to do so, subject to the following
conditions:
The above copyright notice and this permission notice
shall be included in all copies or substantial portions
of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF
ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED
TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT
SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR
IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
DEALINGS IN THE SOFTWARE.
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/README.md����������������������������������������������������������������������������0000644�0000000�0000000�00000010315�10461020230�0012463�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# RustCrypto: ChaCha20
[![Crate][crate-image]][crate-link]
[![Docs][docs-image]][docs-link]
![Apache2/MIT licensed][license-image]
![Rust Version][rustc-image]
[![Project Chat][chat-image]][chat-link]
[![Build Status][build-image]][build-link]
[![HAZMAT][hazmat-image]][hazmat-link]
Pure Rust implementation of the [ChaCha20 Stream Cipher][1].
[Documentation][docs-link]
 ## About
[ChaCha20][1] is a [stream cipher][2] which is designed to support
high-performance software implementations.
It improves upon the previous [Salsa20][3] stream cipher with increased
per-round diffusion at no cost to performance.
This crate also contains an implementation of [XChaCha20][4]: a variant
of ChaCha20 with an extended 192-bit (24-byte) nonce, gated under the
`chacha20` Cargo feature (on-by-default).
## Implementations
This crate contains the following implementations of ChaCha20, all of which
work on stable Rust with the following `RUSTFLAGS`:
- `x86` / `x86_64`
- `avx2`: (~1.4cpb) `-Ctarget-cpu=haswell -Ctarget-feature=+avx2`
- `sse2`: (~2.5cpb) `-Ctarget-feature=+sse2` (on by default on x86 CPUs)
- `aarch64`
- `neon` (~2-3x faster than `soft`) requires Rust 1.61+ and the `neon` feature enabled
- Portable
- `soft`: (~5 cpb on x86/x86_64)
NOTE: cpb = cycles per byte (smaller is better)
## Security
### ⚠️ Warning: [Hazmat!][hazmat-link]
This crate does not ensure ciphertexts are authentic (i.e. by using a MAC to
verify ciphertext integrity), which can lead to serious vulnerabilities
if used incorrectly!
To avoid this, use an [AEAD][5] mode based on ChaCha20, i.e. [ChaCha20Poly1305][6].
See the [RustCrypto/AEADs][7] repository for more information.
USE AT YOUR OWN RISK!
### Notes
This crate has received one [security audit by NCC Group][8], with no significant
findings. We would like to thank [MobileCoin][9] for funding the audit.
All implementations contained in the crate (along with the underlying ChaCha20
stream cipher itself) are designed to execute in constant time.
## Minimum Supported Rust Version
Rust **1.56** or higher.
Minimum supported Rust version can be changed in the future, but it will be
done with a minor version bump.
## SemVer Policy
- All on-by-default features of this library are covered by SemVer
- MSRV is considered exempt from SemVer as noted above
## License
Licensed under either of:
- [Apache License, Version 2.0](http://www.apache.org/licenses/LICENSE-2.0)
- [MIT license](http://opensource.org/licenses/MIT)
at your option.
### Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted
for inclusion in the work by you, as defined in the Apache-2.0 license, shall be
dual licensed as above, without any additional terms or conditions.
[//]: # (badges)
[crate-image]: https://img.shields.io/crates/v/chacha20.svg
[crate-link]: https://crates.io/crates/chacha20
[docs-image]: https://docs.rs/chacha20/badge.svg
[docs-link]: https://docs.rs/chacha20/
[license-image]: https://img.shields.io/badge/license-Apache2.0/MIT-blue.svg
[rustc-image]: https://img.shields.io/badge/rustc-1.56+-blue.svg
[chat-image]: https://img.shields.io/badge/zulip-join_chat-blue.svg
[chat-link]: https://rustcrypto.zulipchat.com/#narrow/stream/260049-stream-ciphers
[build-image]: https://github.com/RustCrypto/stream-ciphers/workflows/chacha20/badge.svg?branch=master&event=push
[build-link]: https://github.com/RustCrypto/stream-ciphers/actions?query=workflow%3Achacha20
[hazmat-image]: https://img.shields.io/badge/crypto-hazmat%E2%9A%A0-red.svg
[hazmat-link]: https://github.com/RustCrypto/meta/blob/master/HAZMAT.md
[//]: # (footnotes)
[1]: https://en.wikipedia.org/wiki/Salsa20#ChaCha_variant
[2]: https://en.wikipedia.org/wiki/Stream_cipher
[3]: https://en.wikipedia.org/wiki/Salsa20
[4]: https://tools.ietf.org/html/draft-arciszewski-xchacha-02
[5]: https://en.wikipedia.org/wiki/Authenticated_encryption
[6]: https://github.com/RustCrypto/AEADs/tree/master/chacha20poly1305
[7]: https://github.com/RustCrypto/AEADs
[8]: https://research.nccgroup.com/2020/02/26/public-report-rustcrypto-aes-gcm-and-chacha20poly1305-implementation-review/
[9]: https://www.mobilecoin.com/
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/benches/mod.rs�����������������������������������������������������������������������0000644�0000000�0000000�00000001074�10461020230�0013742�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#![feature(test)]
extern crate test;
cipher::stream_cipher_bench!(
chacha20::ChaCha8;
chacha8_bench1_16b 16;
chacha8_bench2_256b 256;
chacha8_bench3_1kib 1024;
chacha8_bench4_16kib 16384;
);
cipher::stream_cipher_bench!(
chacha20::ChaCha12;
chacha12_bench1_16b 16;
chacha12_bench2_256b 256;
chacha12_bench3_1kib 1024;
chacha12_bench4_16kib 16384;
);
cipher::stream_cipher_bench!(
chacha20::ChaCha20;
chacha20_bench1_16b 16;
chacha20_bench2_256b 256;
chacha20_bench3_1kib 1024;
chacha20_bench4_16kib 16384;
);
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/backends/avx2.rs�����������������������������������������������������������������0000644�0000000�0000000�00000017646�10461020230�0015011�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use crate::{Block, StreamClosure, Unsigned, STATE_WORDS};
use cipher::{
consts::{U4, U64},
BlockSizeUser, ParBlocks, ParBlocksSizeUser, StreamBackend,
};
use core::marker::PhantomData;
#[cfg(target_arch = "x86")]
use core::arch::x86::*;
#[cfg(target_arch = "x86_64")]
use core::arch::x86_64::*;
/// Number of blocks processed in parallel.
const PAR_BLOCKS: usize = 4;
/// Number of `__m256i` to store parallel blocks.
const N: usize = PAR_BLOCKS / 2;
#[inline]
#[target_feature(enable = "avx2")]
pub(crate) unsafe fn inner(state: &mut [u32; STATE_WORDS], f: F)
where
R: Unsigned,
F: StreamClosure,
{
let state_ptr = state.as_ptr() as *const __m128i;
let v = [
_mm256_broadcastsi128_si256(_mm_loadu_si128(state_ptr.add(0))),
_mm256_broadcastsi128_si256(_mm_loadu_si128(state_ptr.add(1))),
_mm256_broadcastsi128_si256(_mm_loadu_si128(state_ptr.add(2))),
];
let mut c = _mm256_broadcastsi128_si256(_mm_loadu_si128(state_ptr.add(3)));
c = _mm256_add_epi32(c, _mm256_set_epi32(0, 0, 0, 1, 0, 0, 0, 0));
let mut ctr = [c; N];
for i in 0..N {
ctr[i] = c;
c = _mm256_add_epi32(c, _mm256_set_epi32(0, 0, 0, 2, 0, 0, 0, 2));
}
let mut backend = Backend:: {
v,
ctr,
_pd: PhantomData,
};
f.call(&mut backend);
state[12] = _mm256_extract_epi32(backend.ctr[0], 0) as u32;
}
struct Backend {
v: [__m256i; 3],
ctr: [__m256i; N],
_pd: PhantomData,
}
impl BlockSizeUser for Backend {
type BlockSize = U64;
}
impl ParBlocksSizeUser for Backend {
type ParBlocksSize = U4;
}
impl StreamBackend for Backend {
#[inline(always)]
fn gen_ks_block(&mut self, block: &mut Block) {
unsafe {
let res = rounds::(&self.v, &self.ctr);
for c in self.ctr.iter_mut() {
*c = _mm256_add_epi32(*c, _mm256_set_epi32(0, 0, 0, 1, 0, 0, 0, 1));
}
let res0: [__m128i; 8] = core::mem::transmute(res[0]);
let block_ptr = block.as_mut_ptr() as *mut __m128i;
for i in 0..4 {
_mm_storeu_si128(block_ptr.add(i), res0[2 * i]);
}
}
}
#[inline(always)]
fn gen_par_ks_blocks(&mut self, blocks: &mut ParBlocks) {
unsafe {
let vs = rounds::(&self.v, &self.ctr);
let pb = PAR_BLOCKS as i32;
for c in self.ctr.iter_mut() {
*c = _mm256_add_epi32(*c, _mm256_set_epi32(0, 0, 0, pb, 0, 0, 0, pb));
}
let mut block_ptr = blocks.as_mut_ptr() as *mut __m128i;
for v in vs {
let t: [__m128i; 8] = core::mem::transmute(v);
for i in 0..4 {
_mm_storeu_si128(block_ptr.add(i), t[2 * i]);
_mm_storeu_si128(block_ptr.add(4 + i), t[2 * i + 1]);
}
block_ptr = block_ptr.add(8);
}
}
}
}
#[inline]
#[target_feature(enable = "avx2")]
unsafe fn rounds(v: &[__m256i; 3], c: &[__m256i; N]) -> [[__m256i; 4]; N] {
let mut vs: [[__m256i; 4]; N] = [[_mm256_setzero_si256(); 4]; N];
for i in 0..N {
vs[i] = [v[0], v[1], v[2], c[i]];
}
for _ in 0..R::USIZE {
double_quarter_round(&mut vs);
}
for i in 0..N {
for j in 0..3 {
vs[i][j] = _mm256_add_epi32(vs[i][j], v[j]);
}
vs[i][3] = _mm256_add_epi32(vs[i][3], c[i]);
}
vs
}
#[inline]
#[target_feature(enable = "avx2")]
unsafe fn double_quarter_round(v: &mut [[__m256i; 4]; N]) {
add_xor_rot(v);
rows_to_cols(v);
add_xor_rot(v);
cols_to_rows(v);
}
/// The goal of this function is to transform the state words from:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c0, c1, c2, c3] [ 8, 9, 10, 11]
/// [d0, d1, d2, d3] [12, 13, 14, 15]
/// ```
///
/// to:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b1, b2, b3, b0] == [ 5, 6, 7, 4]
/// [c2, c3, c0, c1] [10, 11, 8, 9]
/// [d3, d0, d1, d2] [15, 12, 13, 14]
/// ```
///
/// so that we can apply [`add_xor_rot`] to the resulting columns, and have it compute the
/// "diagonal rounds" (as defined in RFC 7539) in parallel. In practice, this shuffle is
/// non-optimal: the last state word to be altered in `add_xor_rot` is `b`, so the shuffle
/// blocks on the result of `b` being calculated.
///
/// We can optimize this by observing that the four quarter rounds in `add_xor_rot` are
/// data-independent: they only access a single column of the state, and thus the order of
/// the columns does not matter. We therefore instead shuffle the other three state words,
/// to obtain the following equivalent layout:
/// ```text
/// [a3, a0, a1, a2] [ 3, 0, 1, 2]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c1, c2, c3, c0] [ 9, 10, 11, 8]
/// [d2, d3, d0, d1] [14, 15, 12, 13]
/// ```
///
/// See https://github.com/sneves/blake2-avx2/pull/4 for additional details. The earliest
/// known occurrence of this optimization is in floodyberry's SSE4 ChaCha code from 2014:
/// - https://github.com/floodyberry/chacha-opt/blob/0ab65cb99f5016633b652edebaf3691ceb4ff753/chacha_blocks_ssse3-64.S#L639-L643
#[inline]
#[target_feature(enable = "avx2")]
unsafe fn rows_to_cols(vs: &mut [[__m256i; 4]; N]) {
// c >>>= 32; d >>>= 64; a >>>= 96;
for [a, _, c, d] in vs {
*c = _mm256_shuffle_epi32(*c, 0b_00_11_10_01); // _MM_SHUFFLE(0, 3, 2, 1)
*d = _mm256_shuffle_epi32(*d, 0b_01_00_11_10); // _MM_SHUFFLE(1, 0, 3, 2)
*a = _mm256_shuffle_epi32(*a, 0b_10_01_00_11); // _MM_SHUFFLE(2, 1, 0, 3)
}
}
/// The goal of this function is to transform the state words from:
/// ```text
/// [a3, a0, a1, a2] [ 3, 0, 1, 2]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c1, c2, c3, c0] [ 9, 10, 11, 8]
/// [d2, d3, d0, d1] [14, 15, 12, 13]
/// ```
///
/// to:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c0, c1, c2, c3] [ 8, 9, 10, 11]
/// [d0, d1, d2, d3] [12, 13, 14, 15]
/// ```
///
/// reversing the transformation of [`rows_to_cols`].
#[inline]
#[target_feature(enable = "avx2")]
unsafe fn cols_to_rows(vs: &mut [[__m256i; 4]; N]) {
// c <<<= 32; d <<<= 64; a <<<= 96;
for [a, _, c, d] in vs {
*c = _mm256_shuffle_epi32(*c, 0b_10_01_00_11); // _MM_SHUFFLE(2, 1, 0, 3)
*d = _mm256_shuffle_epi32(*d, 0b_01_00_11_10); // _MM_SHUFFLE(1, 0, 3, 2)
*a = _mm256_shuffle_epi32(*a, 0b_00_11_10_01); // _MM_SHUFFLE(0, 3, 2, 1)
}
}
#[inline]
#[target_feature(enable = "avx2")]
unsafe fn add_xor_rot(vs: &mut [[__m256i; 4]; N]) {
let rol16_mask = _mm256_set_epi64x(
0x0d0c_0f0e_0908_0b0a,
0x0504_0706_0100_0302,
0x0d0c_0f0e_0908_0b0a,
0x0504_0706_0100_0302,
);
let rol8_mask = _mm256_set_epi64x(
0x0e0d_0c0f_0a09_080b,
0x0605_0407_0201_0003,
0x0e0d_0c0f_0a09_080b,
0x0605_0407_0201_0003,
);
// a += b; d ^= a; d <<<= (16, 16, 16, 16);
for [a, b, _, d] in vs.iter_mut() {
*a = _mm256_add_epi32(*a, *b);
*d = _mm256_xor_si256(*d, *a);
*d = _mm256_shuffle_epi8(*d, rol16_mask);
}
// c += d; b ^= c; b <<<= (12, 12, 12, 12);
for [_, b, c, d] in vs.iter_mut() {
*c = _mm256_add_epi32(*c, *d);
*b = _mm256_xor_si256(*b, *c);
*b = _mm256_xor_si256(_mm256_slli_epi32(*b, 12), _mm256_srli_epi32(*b, 20));
}
// a += b; d ^= a; d <<<= (8, 8, 8, 8);
for [a, b, _, d] in vs.iter_mut() {
*a = _mm256_add_epi32(*a, *b);
*d = _mm256_xor_si256(*d, *a);
*d = _mm256_shuffle_epi8(*d, rol8_mask);
}
// c += d; b ^= c; b <<<= (7, 7, 7, 7);
for [_, b, c, d] in vs.iter_mut() {
*c = _mm256_add_epi32(*c, *d);
*b = _mm256_xor_si256(*b, *c);
*b = _mm256_xor_si256(_mm256_slli_epi32(*b, 7), _mm256_srli_epi32(*b, 25));
}
}
������������������������������������������������������������������������������������������chacha20-0.9.1/src/backends/neon.rs�����������������������������������������������������������������0000644�0000000�0000000�00000027402�10461020230�0015057�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! NEON-optimized implementation for aarch64 CPUs.
//!
//! Adapted from the Crypto++ `chacha_simd` implementation by Jack Lloyd and
//! Jeffrey Walton (public domain).
use crate::{Block, StreamClosure, Unsigned, STATE_WORDS};
use cipher::{
consts::{U4, U64},
BlockSizeUser, ParBlocks, ParBlocksSizeUser, StreamBackend,
};
use core::{arch::aarch64::*, marker::PhantomData};
#[inline]
#[target_feature(enable = "neon")]
pub(crate) unsafe fn inner(state: &mut [u32; STATE_WORDS], f: F)
where
R: Unsigned,
F: StreamClosure,
{
let mut backend = Backend:: {
state: [
vld1q_u32(state.as_ptr().offset(0)),
vld1q_u32(state.as_ptr().offset(4)),
vld1q_u32(state.as_ptr().offset(8)),
vld1q_u32(state.as_ptr().offset(12)),
],
_pd: PhantomData,
};
f.call(&mut backend);
vst1q_u32(state.as_mut_ptr().offset(12), backend.state[3]);
}
struct Backend {
state: [uint32x4_t; 4],
_pd: PhantomData,
}
impl BlockSizeUser for Backend {
type BlockSize = U64;
}
impl ParBlocksSizeUser for Backend {
type ParBlocksSize = U4;
}
macro_rules! add64 {
($a:expr, $b:expr) => {
vreinterpretq_u32_u64(vaddq_u64(
vreinterpretq_u64_u32($a),
vreinterpretq_u64_u32($b),
))
};
}
impl StreamBackend for Backend {
#[inline(always)]
fn gen_ks_block(&mut self, block: &mut Block) {
let state3 = self.state[3];
let mut par = ParBlocks::::default();
self.gen_par_ks_blocks(&mut par);
*block = par[0];
unsafe {
self.state[3] = add64!(state3, vld1q_u32([1, 0, 0, 0].as_ptr()));
}
}
#[inline(always)]
fn gen_par_ks_blocks(&mut self, blocks: &mut ParBlocks) {
macro_rules! rotate_left {
($v:ident, 8) => {{
let maskb = [3u8, 0, 1, 2, 7, 4, 5, 6, 11, 8, 9, 10, 15, 12, 13, 14];
let mask = vld1q_u8(maskb.as_ptr());
vreinterpretq_u32_u8(vqtbl1q_u8(vreinterpretq_u8_u32($v), mask))
}};
($v:ident, 16) => {
vreinterpretq_u32_u16(vrev32q_u16(vreinterpretq_u16_u32($v)))
};
($v:ident, $r:literal) => {
vorrq_u32(vshlq_n_u32($v, $r), vshrq_n_u32($v, 32 - $r))
};
}
macro_rules! extract {
($v:ident, $s:literal) => {
vextq_u32($v, $v, $s)
};
}
unsafe {
let ctrs = [
vld1q_u32([1, 0, 0, 0].as_ptr()),
vld1q_u32([2, 0, 0, 0].as_ptr()),
vld1q_u32([3, 0, 0, 0].as_ptr()),
vld1q_u32([4, 0, 0, 0].as_ptr()),
];
let mut r0_0 = self.state[0];
let mut r0_1 = self.state[1];
let mut r0_2 = self.state[2];
let mut r0_3 = self.state[3];
let mut r1_0 = self.state[0];
let mut r1_1 = self.state[1];
let mut r1_2 = self.state[2];
let mut r1_3 = add64!(r0_3, ctrs[0]);
let mut r2_0 = self.state[0];
let mut r2_1 = self.state[1];
let mut r2_2 = self.state[2];
let mut r2_3 = add64!(r0_3, ctrs[1]);
let mut r3_0 = self.state[0];
let mut r3_1 = self.state[1];
let mut r3_2 = self.state[2];
let mut r3_3 = add64!(r0_3, ctrs[2]);
for _ in 0..R::USIZE {
r0_0 = vaddq_u32(r0_0, r0_1);
r1_0 = vaddq_u32(r1_0, r1_1);
r2_0 = vaddq_u32(r2_0, r2_1);
r3_0 = vaddq_u32(r3_0, r3_1);
r0_3 = veorq_u32(r0_3, r0_0);
r1_3 = veorq_u32(r1_3, r1_0);
r2_3 = veorq_u32(r2_3, r2_0);
r3_3 = veorq_u32(r3_3, r3_0);
r0_3 = rotate_left!(r0_3, 16);
r1_3 = rotate_left!(r1_3, 16);
r2_3 = rotate_left!(r2_3, 16);
r3_3 = rotate_left!(r3_3, 16);
r0_2 = vaddq_u32(r0_2, r0_3);
r1_2 = vaddq_u32(r1_2, r1_3);
r2_2 = vaddq_u32(r2_2, r2_3);
r3_2 = vaddq_u32(r3_2, r3_3);
r0_1 = veorq_u32(r0_1, r0_2);
r1_1 = veorq_u32(r1_1, r1_2);
r2_1 = veorq_u32(r2_1, r2_2);
r3_1 = veorq_u32(r3_1, r3_2);
r0_1 = rotate_left!(r0_1, 12);
r1_1 = rotate_left!(r1_1, 12);
r2_1 = rotate_left!(r2_1, 12);
r3_1 = rotate_left!(r3_1, 12);
r0_0 = vaddq_u32(r0_0, r0_1);
r1_0 = vaddq_u32(r1_0, r1_1);
r2_0 = vaddq_u32(r2_0, r2_1);
r3_0 = vaddq_u32(r3_0, r3_1);
r0_3 = veorq_u32(r0_3, r0_0);
r1_3 = veorq_u32(r1_3, r1_0);
r2_3 = veorq_u32(r2_3, r2_0);
r3_3 = veorq_u32(r3_3, r3_0);
r0_3 = rotate_left!(r0_3, 8);
r1_3 = rotate_left!(r1_3, 8);
r2_3 = rotate_left!(r2_3, 8);
r3_3 = rotate_left!(r3_3, 8);
r0_2 = vaddq_u32(r0_2, r0_3);
r1_2 = vaddq_u32(r1_2, r1_3);
r2_2 = vaddq_u32(r2_2, r2_3);
r3_2 = vaddq_u32(r3_2, r3_3);
r0_1 = veorq_u32(r0_1, r0_2);
r1_1 = veorq_u32(r1_1, r1_2);
r2_1 = veorq_u32(r2_1, r2_2);
r3_1 = veorq_u32(r3_1, r3_2);
r0_1 = rotate_left!(r0_1, 7);
r1_1 = rotate_left!(r1_1, 7);
r2_1 = rotate_left!(r2_1, 7);
r3_1 = rotate_left!(r3_1, 7);
r0_1 = extract!(r0_1, 1);
r0_2 = extract!(r0_2, 2);
r0_3 = extract!(r0_3, 3);
r1_1 = extract!(r1_1, 1);
r1_2 = extract!(r1_2, 2);
r1_3 = extract!(r1_3, 3);
r2_1 = extract!(r2_1, 1);
r2_2 = extract!(r2_2, 2);
r2_3 = extract!(r2_3, 3);
r3_1 = extract!(r3_1, 1);
r3_2 = extract!(r3_2, 2);
r3_3 = extract!(r3_3, 3);
r0_0 = vaddq_u32(r0_0, r0_1);
r1_0 = vaddq_u32(r1_0, r1_1);
r2_0 = vaddq_u32(r2_0, r2_1);
r3_0 = vaddq_u32(r3_0, r3_1);
r0_3 = veorq_u32(r0_3, r0_0);
r1_3 = veorq_u32(r1_3, r1_0);
r2_3 = veorq_u32(r2_3, r2_0);
r3_3 = veorq_u32(r3_3, r3_0);
r0_3 = rotate_left!(r0_3, 16);
r1_3 = rotate_left!(r1_3, 16);
r2_3 = rotate_left!(r2_3, 16);
r3_3 = rotate_left!(r3_3, 16);
r0_2 = vaddq_u32(r0_2, r0_3);
r1_2 = vaddq_u32(r1_2, r1_3);
r2_2 = vaddq_u32(r2_2, r2_3);
r3_2 = vaddq_u32(r3_2, r3_3);
r0_1 = veorq_u32(r0_1, r0_2);
r1_1 = veorq_u32(r1_1, r1_2);
r2_1 = veorq_u32(r2_1, r2_2);
r3_1 = veorq_u32(r3_1, r3_2);
r0_1 = rotate_left!(r0_1, 12);
r1_1 = rotate_left!(r1_1, 12);
r2_1 = rotate_left!(r2_1, 12);
r3_1 = rotate_left!(r3_1, 12);
r0_0 = vaddq_u32(r0_0, r0_1);
r1_0 = vaddq_u32(r1_0, r1_1);
r2_0 = vaddq_u32(r2_0, r2_1);
r3_0 = vaddq_u32(r3_0, r3_1);
r0_3 = veorq_u32(r0_3, r0_0);
r1_3 = veorq_u32(r1_3, r1_0);
r2_3 = veorq_u32(r2_3, r2_0);
r3_3 = veorq_u32(r3_3, r3_0);
r0_3 = rotate_left!(r0_3, 8);
r1_3 = rotate_left!(r1_3, 8);
r2_3 = rotate_left!(r2_3, 8);
r3_3 = rotate_left!(r3_3, 8);
r0_2 = vaddq_u32(r0_2, r0_3);
r1_2 = vaddq_u32(r1_2, r1_3);
r2_2 = vaddq_u32(r2_2, r2_3);
r3_2 = vaddq_u32(r3_2, r3_3);
r0_1 = veorq_u32(r0_1, r0_2);
r1_1 = veorq_u32(r1_1, r1_2);
r2_1 = veorq_u32(r2_1, r2_2);
r3_1 = veorq_u32(r3_1, r3_2);
r0_1 = rotate_left!(r0_1, 7);
r1_1 = rotate_left!(r1_1, 7);
r2_1 = rotate_left!(r2_1, 7);
r3_1 = rotate_left!(r3_1, 7);
r0_1 = extract!(r0_1, 3);
r0_2 = extract!(r0_2, 2);
r0_3 = extract!(r0_3, 1);
r1_1 = extract!(r1_1, 3);
r1_2 = extract!(r1_2, 2);
r1_3 = extract!(r1_3, 1);
r2_1 = extract!(r2_1, 3);
r2_2 = extract!(r2_2, 2);
r2_3 = extract!(r2_3, 1);
r3_1 = extract!(r3_1, 3);
r3_2 = extract!(r3_2, 2);
r3_3 = extract!(r3_3, 1);
}
r0_0 = vaddq_u32(r0_0, self.state[0]);
r0_1 = vaddq_u32(r0_1, self.state[1]);
r0_2 = vaddq_u32(r0_2, self.state[2]);
r0_3 = vaddq_u32(r0_3, self.state[3]);
r1_0 = vaddq_u32(r1_0, self.state[0]);
r1_1 = vaddq_u32(r1_1, self.state[1]);
r1_2 = vaddq_u32(r1_2, self.state[2]);
r1_3 = vaddq_u32(r1_3, self.state[3]);
r1_3 = add64!(r1_3, ctrs[0]);
r2_0 = vaddq_u32(r2_0, self.state[0]);
r2_1 = vaddq_u32(r2_1, self.state[1]);
r2_2 = vaddq_u32(r2_2, self.state[2]);
r2_3 = vaddq_u32(r2_3, self.state[3]);
r2_3 = add64!(r2_3, ctrs[1]);
r3_0 = vaddq_u32(r3_0, self.state[0]);
r3_1 = vaddq_u32(r3_1, self.state[1]);
r3_2 = vaddq_u32(r3_2, self.state[2]);
r3_3 = vaddq_u32(r3_3, self.state[3]);
r3_3 = add64!(r3_3, ctrs[2]);
vst1q_u8(blocks[0].as_mut_ptr().offset(0), vreinterpretq_u8_u32(r0_0));
vst1q_u8(
blocks[0].as_mut_ptr().offset(16),
vreinterpretq_u8_u32(r0_1),
);
vst1q_u8(
blocks[0].as_mut_ptr().offset(2 * 16),
vreinterpretq_u8_u32(r0_2),
);
vst1q_u8(
blocks[0].as_mut_ptr().offset(3 * 16),
vreinterpretq_u8_u32(r0_3),
);
vst1q_u8(blocks[1].as_mut_ptr().offset(0), vreinterpretq_u8_u32(r1_0));
vst1q_u8(
blocks[1].as_mut_ptr().offset(16),
vreinterpretq_u8_u32(r1_1),
);
vst1q_u8(
blocks[1].as_mut_ptr().offset(2 * 16),
vreinterpretq_u8_u32(r1_2),
);
vst1q_u8(
blocks[1].as_mut_ptr().offset(3 * 16),
vreinterpretq_u8_u32(r1_3),
);
vst1q_u8(blocks[2].as_mut_ptr().offset(0), vreinterpretq_u8_u32(r2_0));
vst1q_u8(
blocks[2].as_mut_ptr().offset(16),
vreinterpretq_u8_u32(r2_1),
);
vst1q_u8(
blocks[2].as_mut_ptr().offset(2 * 16),
vreinterpretq_u8_u32(r2_2),
);
vst1q_u8(
blocks[2].as_mut_ptr().offset(3 * 16),
vreinterpretq_u8_u32(r2_3),
);
vst1q_u8(blocks[3].as_mut_ptr().offset(0), vreinterpretq_u8_u32(r3_0));
vst1q_u8(
blocks[3].as_mut_ptr().offset(16),
vreinterpretq_u8_u32(r3_1),
);
vst1q_u8(
blocks[3].as_mut_ptr().offset(2 * 16),
vreinterpretq_u8_u32(r3_2),
);
vst1q_u8(
blocks[3].as_mut_ptr().offset(3 * 16),
vreinterpretq_u8_u32(r3_3),
);
self.state[3] = add64!(self.state[3], ctrs[3]);
}
}
}
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/backends/soft.rs�����������������������������������������������������������������0000644�0000000�0000000�00000004173�10461020230�0015073�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! Portable implementation which does not rely on architecture-specific
//! intrinsics.
use crate::{Block, ChaChaCore, Unsigned, STATE_WORDS};
use cipher::{
consts::{U1, U64},
BlockSizeUser, ParBlocksSizeUser, StreamBackend,
};
pub(crate) struct Backend<'a, R: Unsigned>(pub(crate) &'a mut ChaChaCore);
impl<'a, R: Unsigned> BlockSizeUser for Backend<'a, R> {
type BlockSize = U64;
}
impl<'a, R: Unsigned> ParBlocksSizeUser for Backend<'a, R> {
type ParBlocksSize = U1;
}
impl<'a, R: Unsigned> StreamBackend for Backend<'a, R> {
#[inline(always)]
fn gen_ks_block(&mut self, block: &mut Block) {
let res = run_rounds::(&self.0.state);
self.0.state[12] = self.0.state[12].wrapping_add(1);
for (chunk, val) in block.chunks_exact_mut(4).zip(res.iter()) {
chunk.copy_from_slice(&val.to_le_bytes());
}
}
}
#[inline(always)]
fn run_rounds(state: &[u32; STATE_WORDS]) -> [u32; STATE_WORDS] {
let mut res = *state;
for _ in 0..R::USIZE {
// column rounds
quarter_round(0, 4, 8, 12, &mut res);
quarter_round(1, 5, 9, 13, &mut res);
quarter_round(2, 6, 10, 14, &mut res);
quarter_round(3, 7, 11, 15, &mut res);
// diagonal rounds
quarter_round(0, 5, 10, 15, &mut res);
quarter_round(1, 6, 11, 12, &mut res);
quarter_round(2, 7, 8, 13, &mut res);
quarter_round(3, 4, 9, 14, &mut res);
}
for (s1, s0) in res.iter_mut().zip(state.iter()) {
*s1 = s1.wrapping_add(*s0);
}
res
}
/// The ChaCha20 quarter round function
fn quarter_round(a: usize, b: usize, c: usize, d: usize, state: &mut [u32; STATE_WORDS]) {
state[a] = state[a].wrapping_add(state[b]);
state[d] ^= state[a];
state[d] = state[d].rotate_left(16);
state[c] = state[c].wrapping_add(state[d]);
state[b] ^= state[c];
state[b] = state[b].rotate_left(12);
state[a] = state[a].wrapping_add(state[b]);
state[d] ^= state[a];
state[d] = state[d].rotate_left(8);
state[c] = state[c].wrapping_add(state[d]);
state[b] ^= state[c];
state[b] = state[b].rotate_left(7);
}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/backends/sse2.rs�����������������������������������������������������������������0000644�0000000�0000000�00000013146�10461020230�0014774�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use crate::{Block, StreamClosure, Unsigned, STATE_WORDS};
use cipher::{
consts::{U1, U64},
BlockSizeUser, ParBlocksSizeUser, StreamBackend,
};
use core::marker::PhantomData;
#[cfg(target_arch = "x86")]
use core::arch::x86::*;
#[cfg(target_arch = "x86_64")]
use core::arch::x86_64::*;
#[inline]
#[target_feature(enable = "sse2")]
pub(crate) unsafe fn inner(state: &mut [u32; STATE_WORDS], f: F)
where
R: Unsigned,
F: StreamClosure,
{
let state_ptr = state.as_ptr() as *const __m128i;
let mut backend = Backend:: {
v: [
_mm_loadu_si128(state_ptr.add(0)),
_mm_loadu_si128(state_ptr.add(1)),
_mm_loadu_si128(state_ptr.add(2)),
_mm_loadu_si128(state_ptr.add(3)),
],
_pd: PhantomData,
};
f.call(&mut backend);
state[12] = _mm_cvtsi128_si32(backend.v[3]) as u32;
}
struct Backend {
v: [__m128i; 4],
_pd: PhantomData,
}
impl BlockSizeUser for Backend {
type BlockSize = U64;
}
impl ParBlocksSizeUser for Backend {
type ParBlocksSize = U1;
}
impl StreamBackend for Backend {
#[inline(always)]
fn gen_ks_block(&mut self, block: &mut Block) {
unsafe {
let res = rounds::(&self.v);
self.v[3] = _mm_add_epi32(self.v[3], _mm_set_epi32(0, 0, 0, 1));
let block_ptr = block.as_mut_ptr() as *mut __m128i;
for i in 0..4 {
_mm_storeu_si128(block_ptr.add(i), res[i]);
}
}
}
}
#[inline]
#[target_feature(enable = "sse2")]
unsafe fn rounds(v: &[__m128i; 4]) -> [__m128i; 4] {
let mut res = *v;
for _ in 0..R::USIZE {
double_quarter_round(&mut res);
}
for i in 0..4 {
res[i] = _mm_add_epi32(res[i], v[i]);
}
res
}
#[inline]
#[target_feature(enable = "sse2")]
unsafe fn double_quarter_round(v: &mut [__m128i; 4]) {
add_xor_rot(v);
rows_to_cols(v);
add_xor_rot(v);
cols_to_rows(v);
}
/// The goal of this function is to transform the state words from:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c0, c1, c2, c3] [ 8, 9, 10, 11]
/// [d0, d1, d2, d3] [12, 13, 14, 15]
/// ```
///
/// to:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b1, b2, b3, b0] == [ 5, 6, 7, 4]
/// [c2, c3, c0, c1] [10, 11, 8, 9]
/// [d3, d0, d1, d2] [15, 12, 13, 14]
/// ```
///
/// so that we can apply [`add_xor_rot`] to the resulting columns, and have it compute the
/// "diagonal rounds" (as defined in RFC 7539) in parallel. In practice, this shuffle is
/// non-optimal: the last state word to be altered in `add_xor_rot` is `b`, so the shuffle
/// blocks on the result of `b` being calculated.
///
/// We can optimize this by observing that the four quarter rounds in `add_xor_rot` are
/// data-independent: they only access a single column of the state, and thus the order of
/// the columns does not matter. We therefore instead shuffle the other three state words,
/// to obtain the following equivalent layout:
/// ```text
/// [a3, a0, a1, a2] [ 3, 0, 1, 2]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c1, c2, c3, c0] [ 9, 10, 11, 8]
/// [d2, d3, d0, d1] [14, 15, 12, 13]
/// ```
///
/// See https://github.com/sneves/blake2-avx2/pull/4 for additional details. The earliest
/// known occurrence of this optimization is in floodyberry's SSE4 ChaCha code from 2014:
/// - https://github.com/floodyberry/chacha-opt/blob/0ab65cb99f5016633b652edebaf3691ceb4ff753/chacha_blocks_ssse3-64.S#L639-L643
#[inline]
#[target_feature(enable = "sse2")]
unsafe fn rows_to_cols([a, _, c, d]: &mut [__m128i; 4]) {
// c >>>= 32; d >>>= 64; a >>>= 96;
*c = _mm_shuffle_epi32(*c, 0b_00_11_10_01); // _MM_SHUFFLE(0, 3, 2, 1)
*d = _mm_shuffle_epi32(*d, 0b_01_00_11_10); // _MM_SHUFFLE(1, 0, 3, 2)
*a = _mm_shuffle_epi32(*a, 0b_10_01_00_11); // _MM_SHUFFLE(2, 1, 0, 3)
}
/// The goal of this function is to transform the state words from:
/// ```text
/// [a3, a0, a1, a2] [ 3, 0, 1, 2]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c1, c2, c3, c0] [ 9, 10, 11, 8]
/// [d2, d3, d0, d1] [14, 15, 12, 13]
/// ```
///
/// to:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c0, c1, c2, c3] [ 8, 9, 10, 11]
/// [d0, d1, d2, d3] [12, 13, 14, 15]
/// ```
///
/// reversing the transformation of [`rows_to_cols`].
#[inline]
#[target_feature(enable = "sse2")]
unsafe fn cols_to_rows([a, _, c, d]: &mut [__m128i; 4]) {
// c <<<= 32; d <<<= 64; a <<<= 96;
*c = _mm_shuffle_epi32(*c, 0b_10_01_00_11); // _MM_SHUFFLE(2, 1, 0, 3)
*d = _mm_shuffle_epi32(*d, 0b_01_00_11_10); // _MM_SHUFFLE(1, 0, 3, 2)
*a = _mm_shuffle_epi32(*a, 0b_00_11_10_01); // _MM_SHUFFLE(0, 3, 2, 1)
}
#[inline]
#[target_feature(enable = "sse2")]
unsafe fn add_xor_rot([a, b, c, d]: &mut [__m128i; 4]) {
// a += b; d ^= a; d <<<= (16, 16, 16, 16);
*a = _mm_add_epi32(*a, *b);
*d = _mm_xor_si128(*d, *a);
*d = _mm_xor_si128(_mm_slli_epi32(*d, 16), _mm_srli_epi32(*d, 16));
// c += d; b ^= c; b <<<= (12, 12, 12, 12);
*c = _mm_add_epi32(*c, *d);
*b = _mm_xor_si128(*b, *c);
*b = _mm_xor_si128(_mm_slli_epi32(*b, 12), _mm_srli_epi32(*b, 20));
// a += b; d ^= a; d <<<= (8, 8, 8, 8);
*a = _mm_add_epi32(*a, *b);
*d = _mm_xor_si128(*d, *a);
*d = _mm_xor_si128(_mm_slli_epi32(*d, 8), _mm_srli_epi32(*d, 24));
// c += d; b ^= c; b <<<= (7, 7, 7, 7);
*c = _mm_add_epi32(*c, *d);
*b = _mm_xor_si128(*b, *c);
*b = _mm_xor_si128(_mm_slli_epi32(*b, 7), _mm_srli_epi32(*b, 25));
}
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/backends.rs����������������������������������������������������������������������0000644�0000000�0000000�00000001265�10461020230�0014117�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use cfg_if::cfg_if;
cfg_if! {
if #[cfg(chacha20_force_soft)] {
pub(crate) mod soft;
} else if #[cfg(any(target_arch = "x86", target_arch = "x86_64"))] {
cfg_if! {
if #[cfg(chacha20_force_avx2)] {
pub(crate) mod avx2;
} else if #[cfg(chacha20_force_sse2)] {
pub(crate) mod sse2;
} else {
pub(crate) mod soft;
pub(crate) mod avx2;
pub(crate) mod sse2;
}
}
} else if #[cfg(all(chacha20_force_neon, target_arch = "aarch64", target_feature = "neon"))] {
pub(crate) mod neon;
} else {
pub(crate) mod soft;
}
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/legacy.rs������������������������������������������������������������������������0000644�0000000�0000000�00000004152�10461020230�0013607�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! Legacy version of ChaCha20 with a 64-bit nonce
use super::{ChaChaCore, Key, Nonce};
use cipher::{
consts::{U10, U32, U64, U8},
generic_array::GenericArray,
BlockSizeUser, IvSizeUser, KeyIvInit, KeySizeUser, StreamCipherCore, StreamCipherCoreWrapper,
StreamCipherSeekCore, StreamClosure,
};
#[cfg(feature = "zeroize")]
use cipher::zeroize::ZeroizeOnDrop;
/// Nonce type used by [`ChaCha20Legacy`].
pub type LegacyNonce = GenericArray;
/// The ChaCha20 stream cipher (legacy "djb" construction with 64-bit nonce).
///
/// **WARNING:** this implementation uses 32-bit counter, while the original
/// implementation uses 64-bit counter. In other words, it does
/// not allow encrypting of more than 256 GiB of data.
pub type ChaCha20Legacy = StreamCipherCoreWrapper;
/// The ChaCha20 stream cipher (legacy "djb" construction with 64-bit nonce).
pub struct ChaCha20LegacyCore(ChaChaCore);
impl KeySizeUser for ChaCha20LegacyCore {
type KeySize = U32;
}
impl IvSizeUser for ChaCha20LegacyCore {
type IvSize = U8;
}
impl BlockSizeUser for ChaCha20LegacyCore {
type BlockSize = U64;
}
impl KeyIvInit for ChaCha20LegacyCore {
#[inline(always)]
fn new(key: &Key, iv: &LegacyNonce) -> Self {
let mut padded_iv = Nonce::default();
padded_iv[4..].copy_from_slice(iv);
ChaCha20LegacyCore(ChaChaCore::new(key, &padded_iv))
}
}
impl StreamCipherCore for ChaCha20LegacyCore {
#[inline(always)]
fn remaining_blocks(&self) -> Option {
self.0.remaining_blocks()
}
#[inline(always)]
fn process_with_backend(&mut self, f: impl StreamClosure) {
self.0.process_with_backend(f);
}
}
impl StreamCipherSeekCore for ChaCha20LegacyCore {
type Counter = u32;
#[inline(always)]
fn get_block_pos(&self) -> u32 {
self.0.get_block_pos()
}
#[inline(always)]
fn set_block_pos(&mut self, pos: u32) {
self.0.set_block_pos(pos);
}
}
#[cfg(feature = "zeroize")]
#[cfg_attr(docsrs, doc(cfg(feature = "zeroize")))]
impl ZeroizeOnDrop for ChaCha20LegacyCore {}
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/lib.rs���������������������������������������������������������������������������0000644�0000000�0000000�00000025400�10461020230�0013110�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! Implementation of the [ChaCha] family of stream ciphers.
//!
//! Cipher functionality is accessed using traits from re-exported [`cipher`] crate.
//!
//! ChaCha stream ciphers are lightweight and amenable to fast, constant-time
//! implementations in software. It improves upon the previous [Salsa] design,
//! providing increased per-round diffusion with no cost to performance.
//!
//! This crate contains the following variants of the ChaCha20 core algorithm:
//!
//! - [`ChaCha20`]: standard IETF variant with 96-bit nonce
//! - [`ChaCha8`] / [`ChaCha12`]: reduced round variants of ChaCha20
//! - [`XChaCha20`]: 192-bit extended nonce variant
//! - [`XChaCha8`] / [`XChaCha12`]: reduced round variants of XChaCha20
//! - [`ChaCha20Legacy`]: "djb" variant with 64-bit nonce.
//! **WARNING:** This implementation internally uses 32-bit counter,
//! while the original implementation uses 64-bit counter. In other words,
//! it does not allow encryption of more than 256 GiB of data.
//!
//! # ⚠️ Security Warning: Hazmat!
//!
//! This crate does not ensure ciphertexts are authentic, which can lead to
//! serious vulnerabilities if used incorrectly!
//!
//! If in doubt, use the [`chacha20poly1305`] crate instead, which provides
//! an authenticated mode on top of ChaCha20.
//!
//! **USE AT YOUR OWN RISK!**
//!
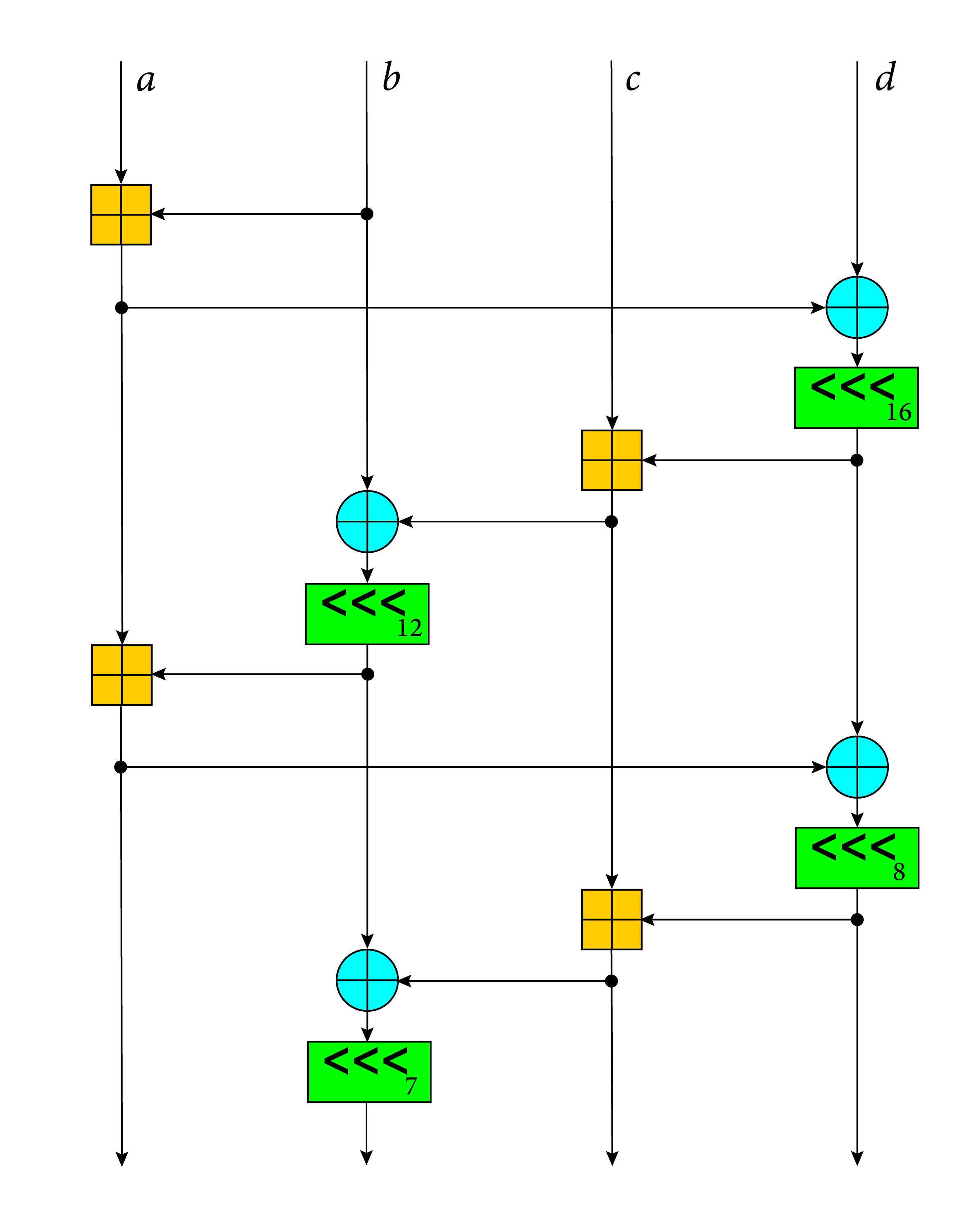
//! # Diagram
//!
//! This diagram illustrates the ChaCha quarter round function.
//! Each round consists of four quarter-rounds:
//!
//!
## About
[ChaCha20][1] is a [stream cipher][2] which is designed to support
high-performance software implementations.
It improves upon the previous [Salsa20][3] stream cipher with increased
per-round diffusion at no cost to performance.
This crate also contains an implementation of [XChaCha20][4]: a variant
of ChaCha20 with an extended 192-bit (24-byte) nonce, gated under the
`chacha20` Cargo feature (on-by-default).
## Implementations
This crate contains the following implementations of ChaCha20, all of which
work on stable Rust with the following `RUSTFLAGS`:
- `x86` / `x86_64`
- `avx2`: (~1.4cpb) `-Ctarget-cpu=haswell -Ctarget-feature=+avx2`
- `sse2`: (~2.5cpb) `-Ctarget-feature=+sse2` (on by default on x86 CPUs)
- `aarch64`
- `neon` (~2-3x faster than `soft`) requires Rust 1.61+ and the `neon` feature enabled
- Portable
- `soft`: (~5 cpb on x86/x86_64)
NOTE: cpb = cycles per byte (smaller is better)
## Security
### ⚠️ Warning: [Hazmat!][hazmat-link]
This crate does not ensure ciphertexts are authentic (i.e. by using a MAC to
verify ciphertext integrity), which can lead to serious vulnerabilities
if used incorrectly!
To avoid this, use an [AEAD][5] mode based on ChaCha20, i.e. [ChaCha20Poly1305][6].
See the [RustCrypto/AEADs][7] repository for more information.
USE AT YOUR OWN RISK!
### Notes
This crate has received one [security audit by NCC Group][8], with no significant
findings. We would like to thank [MobileCoin][9] for funding the audit.
All implementations contained in the crate (along with the underlying ChaCha20
stream cipher itself) are designed to execute in constant time.
## Minimum Supported Rust Version
Rust **1.56** or higher.
Minimum supported Rust version can be changed in the future, but it will be
done with a minor version bump.
## SemVer Policy
- All on-by-default features of this library are covered by SemVer
- MSRV is considered exempt from SemVer as noted above
## License
Licensed under either of:
- [Apache License, Version 2.0](http://www.apache.org/licenses/LICENSE-2.0)
- [MIT license](http://opensource.org/licenses/MIT)
at your option.
### Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted
for inclusion in the work by you, as defined in the Apache-2.0 license, shall be
dual licensed as above, without any additional terms or conditions.
[//]: # (badges)
[crate-image]: https://img.shields.io/crates/v/chacha20.svg
[crate-link]: https://crates.io/crates/chacha20
[docs-image]: https://docs.rs/chacha20/badge.svg
[docs-link]: https://docs.rs/chacha20/
[license-image]: https://img.shields.io/badge/license-Apache2.0/MIT-blue.svg
[rustc-image]: https://img.shields.io/badge/rustc-1.56+-blue.svg
[chat-image]: https://img.shields.io/badge/zulip-join_chat-blue.svg
[chat-link]: https://rustcrypto.zulipchat.com/#narrow/stream/260049-stream-ciphers
[build-image]: https://github.com/RustCrypto/stream-ciphers/workflows/chacha20/badge.svg?branch=master&event=push
[build-link]: https://github.com/RustCrypto/stream-ciphers/actions?query=workflow%3Achacha20
[hazmat-image]: https://img.shields.io/badge/crypto-hazmat%E2%9A%A0-red.svg
[hazmat-link]: https://github.com/RustCrypto/meta/blob/master/HAZMAT.md
[//]: # (footnotes)
[1]: https://en.wikipedia.org/wiki/Salsa20#ChaCha_variant
[2]: https://en.wikipedia.org/wiki/Stream_cipher
[3]: https://en.wikipedia.org/wiki/Salsa20
[4]: https://tools.ietf.org/html/draft-arciszewski-xchacha-02
[5]: https://en.wikipedia.org/wiki/Authenticated_encryption
[6]: https://github.com/RustCrypto/AEADs/tree/master/chacha20poly1305
[7]: https://github.com/RustCrypto/AEADs
[8]: https://research.nccgroup.com/2020/02/26/public-report-rustcrypto-aes-gcm-and-chacha20poly1305-implementation-review/
[9]: https://www.mobilecoin.com/
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/benches/mod.rs�����������������������������������������������������������������������0000644�0000000�0000000�00000001074�10461020230�0013742�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#![feature(test)]
extern crate test;
cipher::stream_cipher_bench!(
chacha20::ChaCha8;
chacha8_bench1_16b 16;
chacha8_bench2_256b 256;
chacha8_bench3_1kib 1024;
chacha8_bench4_16kib 16384;
);
cipher::stream_cipher_bench!(
chacha20::ChaCha12;
chacha12_bench1_16b 16;
chacha12_bench2_256b 256;
chacha12_bench3_1kib 1024;
chacha12_bench4_16kib 16384;
);
cipher::stream_cipher_bench!(
chacha20::ChaCha20;
chacha20_bench1_16b 16;
chacha20_bench2_256b 256;
chacha20_bench3_1kib 1024;
chacha20_bench4_16kib 16384;
);
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/backends/avx2.rs�����������������������������������������������������������������0000644�0000000�0000000�00000017646�10461020230�0015011�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use crate::{Block, StreamClosure, Unsigned, STATE_WORDS};
use cipher::{
consts::{U4, U64},
BlockSizeUser, ParBlocks, ParBlocksSizeUser, StreamBackend,
};
use core::marker::PhantomData;
#[cfg(target_arch = "x86")]
use core::arch::x86::*;
#[cfg(target_arch = "x86_64")]
use core::arch::x86_64::*;
/// Number of blocks processed in parallel.
const PAR_BLOCKS: usize = 4;
/// Number of `__m256i` to store parallel blocks.
const N: usize = PAR_BLOCKS / 2;
#[inline]
#[target_feature(enable = "avx2")]
pub(crate) unsafe fn inner(state: &mut [u32; STATE_WORDS], f: F)
where
R: Unsigned,
F: StreamClosure,
{
let state_ptr = state.as_ptr() as *const __m128i;
let v = [
_mm256_broadcastsi128_si256(_mm_loadu_si128(state_ptr.add(0))),
_mm256_broadcastsi128_si256(_mm_loadu_si128(state_ptr.add(1))),
_mm256_broadcastsi128_si256(_mm_loadu_si128(state_ptr.add(2))),
];
let mut c = _mm256_broadcastsi128_si256(_mm_loadu_si128(state_ptr.add(3)));
c = _mm256_add_epi32(c, _mm256_set_epi32(0, 0, 0, 1, 0, 0, 0, 0));
let mut ctr = [c; N];
for i in 0..N {
ctr[i] = c;
c = _mm256_add_epi32(c, _mm256_set_epi32(0, 0, 0, 2, 0, 0, 0, 2));
}
let mut backend = Backend:: {
v,
ctr,
_pd: PhantomData,
};
f.call(&mut backend);
state[12] = _mm256_extract_epi32(backend.ctr[0], 0) as u32;
}
struct Backend {
v: [__m256i; 3],
ctr: [__m256i; N],
_pd: PhantomData,
}
impl BlockSizeUser for Backend {
type BlockSize = U64;
}
impl ParBlocksSizeUser for Backend {
type ParBlocksSize = U4;
}
impl StreamBackend for Backend {
#[inline(always)]
fn gen_ks_block(&mut self, block: &mut Block) {
unsafe {
let res = rounds::(&self.v, &self.ctr);
for c in self.ctr.iter_mut() {
*c = _mm256_add_epi32(*c, _mm256_set_epi32(0, 0, 0, 1, 0, 0, 0, 1));
}
let res0: [__m128i; 8] = core::mem::transmute(res[0]);
let block_ptr = block.as_mut_ptr() as *mut __m128i;
for i in 0..4 {
_mm_storeu_si128(block_ptr.add(i), res0[2 * i]);
}
}
}
#[inline(always)]
fn gen_par_ks_blocks(&mut self, blocks: &mut ParBlocks) {
unsafe {
let vs = rounds::(&self.v, &self.ctr);
let pb = PAR_BLOCKS as i32;
for c in self.ctr.iter_mut() {
*c = _mm256_add_epi32(*c, _mm256_set_epi32(0, 0, 0, pb, 0, 0, 0, pb));
}
let mut block_ptr = blocks.as_mut_ptr() as *mut __m128i;
for v in vs {
let t: [__m128i; 8] = core::mem::transmute(v);
for i in 0..4 {
_mm_storeu_si128(block_ptr.add(i), t[2 * i]);
_mm_storeu_si128(block_ptr.add(4 + i), t[2 * i + 1]);
}
block_ptr = block_ptr.add(8);
}
}
}
}
#[inline]
#[target_feature(enable = "avx2")]
unsafe fn rounds(v: &[__m256i; 3], c: &[__m256i; N]) -> [[__m256i; 4]; N] {
let mut vs: [[__m256i; 4]; N] = [[_mm256_setzero_si256(); 4]; N];
for i in 0..N {
vs[i] = [v[0], v[1], v[2], c[i]];
}
for _ in 0..R::USIZE {
double_quarter_round(&mut vs);
}
for i in 0..N {
for j in 0..3 {
vs[i][j] = _mm256_add_epi32(vs[i][j], v[j]);
}
vs[i][3] = _mm256_add_epi32(vs[i][3], c[i]);
}
vs
}
#[inline]
#[target_feature(enable = "avx2")]
unsafe fn double_quarter_round(v: &mut [[__m256i; 4]; N]) {
add_xor_rot(v);
rows_to_cols(v);
add_xor_rot(v);
cols_to_rows(v);
}
/// The goal of this function is to transform the state words from:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c0, c1, c2, c3] [ 8, 9, 10, 11]
/// [d0, d1, d2, d3] [12, 13, 14, 15]
/// ```
///
/// to:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b1, b2, b3, b0] == [ 5, 6, 7, 4]
/// [c2, c3, c0, c1] [10, 11, 8, 9]
/// [d3, d0, d1, d2] [15, 12, 13, 14]
/// ```
///
/// so that we can apply [`add_xor_rot`] to the resulting columns, and have it compute the
/// "diagonal rounds" (as defined in RFC 7539) in parallel. In practice, this shuffle is
/// non-optimal: the last state word to be altered in `add_xor_rot` is `b`, so the shuffle
/// blocks on the result of `b` being calculated.
///
/// We can optimize this by observing that the four quarter rounds in `add_xor_rot` are
/// data-independent: they only access a single column of the state, and thus the order of
/// the columns does not matter. We therefore instead shuffle the other three state words,
/// to obtain the following equivalent layout:
/// ```text
/// [a3, a0, a1, a2] [ 3, 0, 1, 2]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c1, c2, c3, c0] [ 9, 10, 11, 8]
/// [d2, d3, d0, d1] [14, 15, 12, 13]
/// ```
///
/// See https://github.com/sneves/blake2-avx2/pull/4 for additional details. The earliest
/// known occurrence of this optimization is in floodyberry's SSE4 ChaCha code from 2014:
/// - https://github.com/floodyberry/chacha-opt/blob/0ab65cb99f5016633b652edebaf3691ceb4ff753/chacha_blocks_ssse3-64.S#L639-L643
#[inline]
#[target_feature(enable = "avx2")]
unsafe fn rows_to_cols(vs: &mut [[__m256i; 4]; N]) {
// c >>>= 32; d >>>= 64; a >>>= 96;
for [a, _, c, d] in vs {
*c = _mm256_shuffle_epi32(*c, 0b_00_11_10_01); // _MM_SHUFFLE(0, 3, 2, 1)
*d = _mm256_shuffle_epi32(*d, 0b_01_00_11_10); // _MM_SHUFFLE(1, 0, 3, 2)
*a = _mm256_shuffle_epi32(*a, 0b_10_01_00_11); // _MM_SHUFFLE(2, 1, 0, 3)
}
}
/// The goal of this function is to transform the state words from:
/// ```text
/// [a3, a0, a1, a2] [ 3, 0, 1, 2]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c1, c2, c3, c0] [ 9, 10, 11, 8]
/// [d2, d3, d0, d1] [14, 15, 12, 13]
/// ```
///
/// to:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c0, c1, c2, c3] [ 8, 9, 10, 11]
/// [d0, d1, d2, d3] [12, 13, 14, 15]
/// ```
///
/// reversing the transformation of [`rows_to_cols`].
#[inline]
#[target_feature(enable = "avx2")]
unsafe fn cols_to_rows(vs: &mut [[__m256i; 4]; N]) {
// c <<<= 32; d <<<= 64; a <<<= 96;
for [a, _, c, d] in vs {
*c = _mm256_shuffle_epi32(*c, 0b_10_01_00_11); // _MM_SHUFFLE(2, 1, 0, 3)
*d = _mm256_shuffle_epi32(*d, 0b_01_00_11_10); // _MM_SHUFFLE(1, 0, 3, 2)
*a = _mm256_shuffle_epi32(*a, 0b_00_11_10_01); // _MM_SHUFFLE(0, 3, 2, 1)
}
}
#[inline]
#[target_feature(enable = "avx2")]
unsafe fn add_xor_rot(vs: &mut [[__m256i; 4]; N]) {
let rol16_mask = _mm256_set_epi64x(
0x0d0c_0f0e_0908_0b0a,
0x0504_0706_0100_0302,
0x0d0c_0f0e_0908_0b0a,
0x0504_0706_0100_0302,
);
let rol8_mask = _mm256_set_epi64x(
0x0e0d_0c0f_0a09_080b,
0x0605_0407_0201_0003,
0x0e0d_0c0f_0a09_080b,
0x0605_0407_0201_0003,
);
// a += b; d ^= a; d <<<= (16, 16, 16, 16);
for [a, b, _, d] in vs.iter_mut() {
*a = _mm256_add_epi32(*a, *b);
*d = _mm256_xor_si256(*d, *a);
*d = _mm256_shuffle_epi8(*d, rol16_mask);
}
// c += d; b ^= c; b <<<= (12, 12, 12, 12);
for [_, b, c, d] in vs.iter_mut() {
*c = _mm256_add_epi32(*c, *d);
*b = _mm256_xor_si256(*b, *c);
*b = _mm256_xor_si256(_mm256_slli_epi32(*b, 12), _mm256_srli_epi32(*b, 20));
}
// a += b; d ^= a; d <<<= (8, 8, 8, 8);
for [a, b, _, d] in vs.iter_mut() {
*a = _mm256_add_epi32(*a, *b);
*d = _mm256_xor_si256(*d, *a);
*d = _mm256_shuffle_epi8(*d, rol8_mask);
}
// c += d; b ^= c; b <<<= (7, 7, 7, 7);
for [_, b, c, d] in vs.iter_mut() {
*c = _mm256_add_epi32(*c, *d);
*b = _mm256_xor_si256(*b, *c);
*b = _mm256_xor_si256(_mm256_slli_epi32(*b, 7), _mm256_srli_epi32(*b, 25));
}
}
������������������������������������������������������������������������������������������chacha20-0.9.1/src/backends/neon.rs�����������������������������������������������������������������0000644�0000000�0000000�00000027402�10461020230�0015057�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! NEON-optimized implementation for aarch64 CPUs.
//!
//! Adapted from the Crypto++ `chacha_simd` implementation by Jack Lloyd and
//! Jeffrey Walton (public domain).
use crate::{Block, StreamClosure, Unsigned, STATE_WORDS};
use cipher::{
consts::{U4, U64},
BlockSizeUser, ParBlocks, ParBlocksSizeUser, StreamBackend,
};
use core::{arch::aarch64::*, marker::PhantomData};
#[inline]
#[target_feature(enable = "neon")]
pub(crate) unsafe fn inner(state: &mut [u32; STATE_WORDS], f: F)
where
R: Unsigned,
F: StreamClosure,
{
let mut backend = Backend:: {
state: [
vld1q_u32(state.as_ptr().offset(0)),
vld1q_u32(state.as_ptr().offset(4)),
vld1q_u32(state.as_ptr().offset(8)),
vld1q_u32(state.as_ptr().offset(12)),
],
_pd: PhantomData,
};
f.call(&mut backend);
vst1q_u32(state.as_mut_ptr().offset(12), backend.state[3]);
}
struct Backend {
state: [uint32x4_t; 4],
_pd: PhantomData,
}
impl BlockSizeUser for Backend {
type BlockSize = U64;
}
impl ParBlocksSizeUser for Backend {
type ParBlocksSize = U4;
}
macro_rules! add64 {
($a:expr, $b:expr) => {
vreinterpretq_u32_u64(vaddq_u64(
vreinterpretq_u64_u32($a),
vreinterpretq_u64_u32($b),
))
};
}
impl StreamBackend for Backend {
#[inline(always)]
fn gen_ks_block(&mut self, block: &mut Block) {
let state3 = self.state[3];
let mut par = ParBlocks::::default();
self.gen_par_ks_blocks(&mut par);
*block = par[0];
unsafe {
self.state[3] = add64!(state3, vld1q_u32([1, 0, 0, 0].as_ptr()));
}
}
#[inline(always)]
fn gen_par_ks_blocks(&mut self, blocks: &mut ParBlocks) {
macro_rules! rotate_left {
($v:ident, 8) => {{
let maskb = [3u8, 0, 1, 2, 7, 4, 5, 6, 11, 8, 9, 10, 15, 12, 13, 14];
let mask = vld1q_u8(maskb.as_ptr());
vreinterpretq_u32_u8(vqtbl1q_u8(vreinterpretq_u8_u32($v), mask))
}};
($v:ident, 16) => {
vreinterpretq_u32_u16(vrev32q_u16(vreinterpretq_u16_u32($v)))
};
($v:ident, $r:literal) => {
vorrq_u32(vshlq_n_u32($v, $r), vshrq_n_u32($v, 32 - $r))
};
}
macro_rules! extract {
($v:ident, $s:literal) => {
vextq_u32($v, $v, $s)
};
}
unsafe {
let ctrs = [
vld1q_u32([1, 0, 0, 0].as_ptr()),
vld1q_u32([2, 0, 0, 0].as_ptr()),
vld1q_u32([3, 0, 0, 0].as_ptr()),
vld1q_u32([4, 0, 0, 0].as_ptr()),
];
let mut r0_0 = self.state[0];
let mut r0_1 = self.state[1];
let mut r0_2 = self.state[2];
let mut r0_3 = self.state[3];
let mut r1_0 = self.state[0];
let mut r1_1 = self.state[1];
let mut r1_2 = self.state[2];
let mut r1_3 = add64!(r0_3, ctrs[0]);
let mut r2_0 = self.state[0];
let mut r2_1 = self.state[1];
let mut r2_2 = self.state[2];
let mut r2_3 = add64!(r0_3, ctrs[1]);
let mut r3_0 = self.state[0];
let mut r3_1 = self.state[1];
let mut r3_2 = self.state[2];
let mut r3_3 = add64!(r0_3, ctrs[2]);
for _ in 0..R::USIZE {
r0_0 = vaddq_u32(r0_0, r0_1);
r1_0 = vaddq_u32(r1_0, r1_1);
r2_0 = vaddq_u32(r2_0, r2_1);
r3_0 = vaddq_u32(r3_0, r3_1);
r0_3 = veorq_u32(r0_3, r0_0);
r1_3 = veorq_u32(r1_3, r1_0);
r2_3 = veorq_u32(r2_3, r2_0);
r3_3 = veorq_u32(r3_3, r3_0);
r0_3 = rotate_left!(r0_3, 16);
r1_3 = rotate_left!(r1_3, 16);
r2_3 = rotate_left!(r2_3, 16);
r3_3 = rotate_left!(r3_3, 16);
r0_2 = vaddq_u32(r0_2, r0_3);
r1_2 = vaddq_u32(r1_2, r1_3);
r2_2 = vaddq_u32(r2_2, r2_3);
r3_2 = vaddq_u32(r3_2, r3_3);
r0_1 = veorq_u32(r0_1, r0_2);
r1_1 = veorq_u32(r1_1, r1_2);
r2_1 = veorq_u32(r2_1, r2_2);
r3_1 = veorq_u32(r3_1, r3_2);
r0_1 = rotate_left!(r0_1, 12);
r1_1 = rotate_left!(r1_1, 12);
r2_1 = rotate_left!(r2_1, 12);
r3_1 = rotate_left!(r3_1, 12);
r0_0 = vaddq_u32(r0_0, r0_1);
r1_0 = vaddq_u32(r1_0, r1_1);
r2_0 = vaddq_u32(r2_0, r2_1);
r3_0 = vaddq_u32(r3_0, r3_1);
r0_3 = veorq_u32(r0_3, r0_0);
r1_3 = veorq_u32(r1_3, r1_0);
r2_3 = veorq_u32(r2_3, r2_0);
r3_3 = veorq_u32(r3_3, r3_0);
r0_3 = rotate_left!(r0_3, 8);
r1_3 = rotate_left!(r1_3, 8);
r2_3 = rotate_left!(r2_3, 8);
r3_3 = rotate_left!(r3_3, 8);
r0_2 = vaddq_u32(r0_2, r0_3);
r1_2 = vaddq_u32(r1_2, r1_3);
r2_2 = vaddq_u32(r2_2, r2_3);
r3_2 = vaddq_u32(r3_2, r3_3);
r0_1 = veorq_u32(r0_1, r0_2);
r1_1 = veorq_u32(r1_1, r1_2);
r2_1 = veorq_u32(r2_1, r2_2);
r3_1 = veorq_u32(r3_1, r3_2);
r0_1 = rotate_left!(r0_1, 7);
r1_1 = rotate_left!(r1_1, 7);
r2_1 = rotate_left!(r2_1, 7);
r3_1 = rotate_left!(r3_1, 7);
r0_1 = extract!(r0_1, 1);
r0_2 = extract!(r0_2, 2);
r0_3 = extract!(r0_3, 3);
r1_1 = extract!(r1_1, 1);
r1_2 = extract!(r1_2, 2);
r1_3 = extract!(r1_3, 3);
r2_1 = extract!(r2_1, 1);
r2_2 = extract!(r2_2, 2);
r2_3 = extract!(r2_3, 3);
r3_1 = extract!(r3_1, 1);
r3_2 = extract!(r3_2, 2);
r3_3 = extract!(r3_3, 3);
r0_0 = vaddq_u32(r0_0, r0_1);
r1_0 = vaddq_u32(r1_0, r1_1);
r2_0 = vaddq_u32(r2_0, r2_1);
r3_0 = vaddq_u32(r3_0, r3_1);
r0_3 = veorq_u32(r0_3, r0_0);
r1_3 = veorq_u32(r1_3, r1_0);
r2_3 = veorq_u32(r2_3, r2_0);
r3_3 = veorq_u32(r3_3, r3_0);
r0_3 = rotate_left!(r0_3, 16);
r1_3 = rotate_left!(r1_3, 16);
r2_3 = rotate_left!(r2_3, 16);
r3_3 = rotate_left!(r3_3, 16);
r0_2 = vaddq_u32(r0_2, r0_3);
r1_2 = vaddq_u32(r1_2, r1_3);
r2_2 = vaddq_u32(r2_2, r2_3);
r3_2 = vaddq_u32(r3_2, r3_3);
r0_1 = veorq_u32(r0_1, r0_2);
r1_1 = veorq_u32(r1_1, r1_2);
r2_1 = veorq_u32(r2_1, r2_2);
r3_1 = veorq_u32(r3_1, r3_2);
r0_1 = rotate_left!(r0_1, 12);
r1_1 = rotate_left!(r1_1, 12);
r2_1 = rotate_left!(r2_1, 12);
r3_1 = rotate_left!(r3_1, 12);
r0_0 = vaddq_u32(r0_0, r0_1);
r1_0 = vaddq_u32(r1_0, r1_1);
r2_0 = vaddq_u32(r2_0, r2_1);
r3_0 = vaddq_u32(r3_0, r3_1);
r0_3 = veorq_u32(r0_3, r0_0);
r1_3 = veorq_u32(r1_3, r1_0);
r2_3 = veorq_u32(r2_3, r2_0);
r3_3 = veorq_u32(r3_3, r3_0);
r0_3 = rotate_left!(r0_3, 8);
r1_3 = rotate_left!(r1_3, 8);
r2_3 = rotate_left!(r2_3, 8);
r3_3 = rotate_left!(r3_3, 8);
r0_2 = vaddq_u32(r0_2, r0_3);
r1_2 = vaddq_u32(r1_2, r1_3);
r2_2 = vaddq_u32(r2_2, r2_3);
r3_2 = vaddq_u32(r3_2, r3_3);
r0_1 = veorq_u32(r0_1, r0_2);
r1_1 = veorq_u32(r1_1, r1_2);
r2_1 = veorq_u32(r2_1, r2_2);
r3_1 = veorq_u32(r3_1, r3_2);
r0_1 = rotate_left!(r0_1, 7);
r1_1 = rotate_left!(r1_1, 7);
r2_1 = rotate_left!(r2_1, 7);
r3_1 = rotate_left!(r3_1, 7);
r0_1 = extract!(r0_1, 3);
r0_2 = extract!(r0_2, 2);
r0_3 = extract!(r0_3, 1);
r1_1 = extract!(r1_1, 3);
r1_2 = extract!(r1_2, 2);
r1_3 = extract!(r1_3, 1);
r2_1 = extract!(r2_1, 3);
r2_2 = extract!(r2_2, 2);
r2_3 = extract!(r2_3, 1);
r3_1 = extract!(r3_1, 3);
r3_2 = extract!(r3_2, 2);
r3_3 = extract!(r3_3, 1);
}
r0_0 = vaddq_u32(r0_0, self.state[0]);
r0_1 = vaddq_u32(r0_1, self.state[1]);
r0_2 = vaddq_u32(r0_2, self.state[2]);
r0_3 = vaddq_u32(r0_3, self.state[3]);
r1_0 = vaddq_u32(r1_0, self.state[0]);
r1_1 = vaddq_u32(r1_1, self.state[1]);
r1_2 = vaddq_u32(r1_2, self.state[2]);
r1_3 = vaddq_u32(r1_3, self.state[3]);
r1_3 = add64!(r1_3, ctrs[0]);
r2_0 = vaddq_u32(r2_0, self.state[0]);
r2_1 = vaddq_u32(r2_1, self.state[1]);
r2_2 = vaddq_u32(r2_2, self.state[2]);
r2_3 = vaddq_u32(r2_3, self.state[3]);
r2_3 = add64!(r2_3, ctrs[1]);
r3_0 = vaddq_u32(r3_0, self.state[0]);
r3_1 = vaddq_u32(r3_1, self.state[1]);
r3_2 = vaddq_u32(r3_2, self.state[2]);
r3_3 = vaddq_u32(r3_3, self.state[3]);
r3_3 = add64!(r3_3, ctrs[2]);
vst1q_u8(blocks[0].as_mut_ptr().offset(0), vreinterpretq_u8_u32(r0_0));
vst1q_u8(
blocks[0].as_mut_ptr().offset(16),
vreinterpretq_u8_u32(r0_1),
);
vst1q_u8(
blocks[0].as_mut_ptr().offset(2 * 16),
vreinterpretq_u8_u32(r0_2),
);
vst1q_u8(
blocks[0].as_mut_ptr().offset(3 * 16),
vreinterpretq_u8_u32(r0_3),
);
vst1q_u8(blocks[1].as_mut_ptr().offset(0), vreinterpretq_u8_u32(r1_0));
vst1q_u8(
blocks[1].as_mut_ptr().offset(16),
vreinterpretq_u8_u32(r1_1),
);
vst1q_u8(
blocks[1].as_mut_ptr().offset(2 * 16),
vreinterpretq_u8_u32(r1_2),
);
vst1q_u8(
blocks[1].as_mut_ptr().offset(3 * 16),
vreinterpretq_u8_u32(r1_3),
);
vst1q_u8(blocks[2].as_mut_ptr().offset(0), vreinterpretq_u8_u32(r2_0));
vst1q_u8(
blocks[2].as_mut_ptr().offset(16),
vreinterpretq_u8_u32(r2_1),
);
vst1q_u8(
blocks[2].as_mut_ptr().offset(2 * 16),
vreinterpretq_u8_u32(r2_2),
);
vst1q_u8(
blocks[2].as_mut_ptr().offset(3 * 16),
vreinterpretq_u8_u32(r2_3),
);
vst1q_u8(blocks[3].as_mut_ptr().offset(0), vreinterpretq_u8_u32(r3_0));
vst1q_u8(
blocks[3].as_mut_ptr().offset(16),
vreinterpretq_u8_u32(r3_1),
);
vst1q_u8(
blocks[3].as_mut_ptr().offset(2 * 16),
vreinterpretq_u8_u32(r3_2),
);
vst1q_u8(
blocks[3].as_mut_ptr().offset(3 * 16),
vreinterpretq_u8_u32(r3_3),
);
self.state[3] = add64!(self.state[3], ctrs[3]);
}
}
}
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/backends/soft.rs�����������������������������������������������������������������0000644�0000000�0000000�00000004173�10461020230�0015073�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! Portable implementation which does not rely on architecture-specific
//! intrinsics.
use crate::{Block, ChaChaCore, Unsigned, STATE_WORDS};
use cipher::{
consts::{U1, U64},
BlockSizeUser, ParBlocksSizeUser, StreamBackend,
};
pub(crate) struct Backend<'a, R: Unsigned>(pub(crate) &'a mut ChaChaCore);
impl<'a, R: Unsigned> BlockSizeUser for Backend<'a, R> {
type BlockSize = U64;
}
impl<'a, R: Unsigned> ParBlocksSizeUser for Backend<'a, R> {
type ParBlocksSize = U1;
}
impl<'a, R: Unsigned> StreamBackend for Backend<'a, R> {
#[inline(always)]
fn gen_ks_block(&mut self, block: &mut Block) {
let res = run_rounds::(&self.0.state);
self.0.state[12] = self.0.state[12].wrapping_add(1);
for (chunk, val) in block.chunks_exact_mut(4).zip(res.iter()) {
chunk.copy_from_slice(&val.to_le_bytes());
}
}
}
#[inline(always)]
fn run_rounds(state: &[u32; STATE_WORDS]) -> [u32; STATE_WORDS] {
let mut res = *state;
for _ in 0..R::USIZE {
// column rounds
quarter_round(0, 4, 8, 12, &mut res);
quarter_round(1, 5, 9, 13, &mut res);
quarter_round(2, 6, 10, 14, &mut res);
quarter_round(3, 7, 11, 15, &mut res);
// diagonal rounds
quarter_round(0, 5, 10, 15, &mut res);
quarter_round(1, 6, 11, 12, &mut res);
quarter_round(2, 7, 8, 13, &mut res);
quarter_round(3, 4, 9, 14, &mut res);
}
for (s1, s0) in res.iter_mut().zip(state.iter()) {
*s1 = s1.wrapping_add(*s0);
}
res
}
/// The ChaCha20 quarter round function
fn quarter_round(a: usize, b: usize, c: usize, d: usize, state: &mut [u32; STATE_WORDS]) {
state[a] = state[a].wrapping_add(state[b]);
state[d] ^= state[a];
state[d] = state[d].rotate_left(16);
state[c] = state[c].wrapping_add(state[d]);
state[b] ^= state[c];
state[b] = state[b].rotate_left(12);
state[a] = state[a].wrapping_add(state[b]);
state[d] ^= state[a];
state[d] = state[d].rotate_left(8);
state[c] = state[c].wrapping_add(state[d]);
state[b] ^= state[c];
state[b] = state[b].rotate_left(7);
}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/backends/sse2.rs�����������������������������������������������������������������0000644�0000000�0000000�00000013146�10461020230�0014774�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use crate::{Block, StreamClosure, Unsigned, STATE_WORDS};
use cipher::{
consts::{U1, U64},
BlockSizeUser, ParBlocksSizeUser, StreamBackend,
};
use core::marker::PhantomData;
#[cfg(target_arch = "x86")]
use core::arch::x86::*;
#[cfg(target_arch = "x86_64")]
use core::arch::x86_64::*;
#[inline]
#[target_feature(enable = "sse2")]
pub(crate) unsafe fn inner(state: &mut [u32; STATE_WORDS], f: F)
where
R: Unsigned,
F: StreamClosure,
{
let state_ptr = state.as_ptr() as *const __m128i;
let mut backend = Backend:: {
v: [
_mm_loadu_si128(state_ptr.add(0)),
_mm_loadu_si128(state_ptr.add(1)),
_mm_loadu_si128(state_ptr.add(2)),
_mm_loadu_si128(state_ptr.add(3)),
],
_pd: PhantomData,
};
f.call(&mut backend);
state[12] = _mm_cvtsi128_si32(backend.v[3]) as u32;
}
struct Backend {
v: [__m128i; 4],
_pd: PhantomData,
}
impl BlockSizeUser for Backend {
type BlockSize = U64;
}
impl ParBlocksSizeUser for Backend {
type ParBlocksSize = U1;
}
impl StreamBackend for Backend {
#[inline(always)]
fn gen_ks_block(&mut self, block: &mut Block) {
unsafe {
let res = rounds::(&self.v);
self.v[3] = _mm_add_epi32(self.v[3], _mm_set_epi32(0, 0, 0, 1));
let block_ptr = block.as_mut_ptr() as *mut __m128i;
for i in 0..4 {
_mm_storeu_si128(block_ptr.add(i), res[i]);
}
}
}
}
#[inline]
#[target_feature(enable = "sse2")]
unsafe fn rounds(v: &[__m128i; 4]) -> [__m128i; 4] {
let mut res = *v;
for _ in 0..R::USIZE {
double_quarter_round(&mut res);
}
for i in 0..4 {
res[i] = _mm_add_epi32(res[i], v[i]);
}
res
}
#[inline]
#[target_feature(enable = "sse2")]
unsafe fn double_quarter_round(v: &mut [__m128i; 4]) {
add_xor_rot(v);
rows_to_cols(v);
add_xor_rot(v);
cols_to_rows(v);
}
/// The goal of this function is to transform the state words from:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c0, c1, c2, c3] [ 8, 9, 10, 11]
/// [d0, d1, d2, d3] [12, 13, 14, 15]
/// ```
///
/// to:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b1, b2, b3, b0] == [ 5, 6, 7, 4]
/// [c2, c3, c0, c1] [10, 11, 8, 9]
/// [d3, d0, d1, d2] [15, 12, 13, 14]
/// ```
///
/// so that we can apply [`add_xor_rot`] to the resulting columns, and have it compute the
/// "diagonal rounds" (as defined in RFC 7539) in parallel. In practice, this shuffle is
/// non-optimal: the last state word to be altered in `add_xor_rot` is `b`, so the shuffle
/// blocks on the result of `b` being calculated.
///
/// We can optimize this by observing that the four quarter rounds in `add_xor_rot` are
/// data-independent: they only access a single column of the state, and thus the order of
/// the columns does not matter. We therefore instead shuffle the other three state words,
/// to obtain the following equivalent layout:
/// ```text
/// [a3, a0, a1, a2] [ 3, 0, 1, 2]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c1, c2, c3, c0] [ 9, 10, 11, 8]
/// [d2, d3, d0, d1] [14, 15, 12, 13]
/// ```
///
/// See https://github.com/sneves/blake2-avx2/pull/4 for additional details. The earliest
/// known occurrence of this optimization is in floodyberry's SSE4 ChaCha code from 2014:
/// - https://github.com/floodyberry/chacha-opt/blob/0ab65cb99f5016633b652edebaf3691ceb4ff753/chacha_blocks_ssse3-64.S#L639-L643
#[inline]
#[target_feature(enable = "sse2")]
unsafe fn rows_to_cols([a, _, c, d]: &mut [__m128i; 4]) {
// c >>>= 32; d >>>= 64; a >>>= 96;
*c = _mm_shuffle_epi32(*c, 0b_00_11_10_01); // _MM_SHUFFLE(0, 3, 2, 1)
*d = _mm_shuffle_epi32(*d, 0b_01_00_11_10); // _MM_SHUFFLE(1, 0, 3, 2)
*a = _mm_shuffle_epi32(*a, 0b_10_01_00_11); // _MM_SHUFFLE(2, 1, 0, 3)
}
/// The goal of this function is to transform the state words from:
/// ```text
/// [a3, a0, a1, a2] [ 3, 0, 1, 2]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c1, c2, c3, c0] [ 9, 10, 11, 8]
/// [d2, d3, d0, d1] [14, 15, 12, 13]
/// ```
///
/// to:
/// ```text
/// [a0, a1, a2, a3] [ 0, 1, 2, 3]
/// [b0, b1, b2, b3] == [ 4, 5, 6, 7]
/// [c0, c1, c2, c3] [ 8, 9, 10, 11]
/// [d0, d1, d2, d3] [12, 13, 14, 15]
/// ```
///
/// reversing the transformation of [`rows_to_cols`].
#[inline]
#[target_feature(enable = "sse2")]
unsafe fn cols_to_rows([a, _, c, d]: &mut [__m128i; 4]) {
// c <<<= 32; d <<<= 64; a <<<= 96;
*c = _mm_shuffle_epi32(*c, 0b_10_01_00_11); // _MM_SHUFFLE(2, 1, 0, 3)
*d = _mm_shuffle_epi32(*d, 0b_01_00_11_10); // _MM_SHUFFLE(1, 0, 3, 2)
*a = _mm_shuffle_epi32(*a, 0b_00_11_10_01); // _MM_SHUFFLE(0, 3, 2, 1)
}
#[inline]
#[target_feature(enable = "sse2")]
unsafe fn add_xor_rot([a, b, c, d]: &mut [__m128i; 4]) {
// a += b; d ^= a; d <<<= (16, 16, 16, 16);
*a = _mm_add_epi32(*a, *b);
*d = _mm_xor_si128(*d, *a);
*d = _mm_xor_si128(_mm_slli_epi32(*d, 16), _mm_srli_epi32(*d, 16));
// c += d; b ^= c; b <<<= (12, 12, 12, 12);
*c = _mm_add_epi32(*c, *d);
*b = _mm_xor_si128(*b, *c);
*b = _mm_xor_si128(_mm_slli_epi32(*b, 12), _mm_srli_epi32(*b, 20));
// a += b; d ^= a; d <<<= (8, 8, 8, 8);
*a = _mm_add_epi32(*a, *b);
*d = _mm_xor_si128(*d, *a);
*d = _mm_xor_si128(_mm_slli_epi32(*d, 8), _mm_srli_epi32(*d, 24));
// c += d; b ^= c; b <<<= (7, 7, 7, 7);
*c = _mm_add_epi32(*c, *d);
*b = _mm_xor_si128(*b, *c);
*b = _mm_xor_si128(_mm_slli_epi32(*b, 7), _mm_srli_epi32(*b, 25));
}
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/backends.rs����������������������������������������������������������������������0000644�0000000�0000000�00000001265�10461020230�0014117�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use cfg_if::cfg_if;
cfg_if! {
if #[cfg(chacha20_force_soft)] {
pub(crate) mod soft;
} else if #[cfg(any(target_arch = "x86", target_arch = "x86_64"))] {
cfg_if! {
if #[cfg(chacha20_force_avx2)] {
pub(crate) mod avx2;
} else if #[cfg(chacha20_force_sse2)] {
pub(crate) mod sse2;
} else {
pub(crate) mod soft;
pub(crate) mod avx2;
pub(crate) mod sse2;
}
}
} else if #[cfg(all(chacha20_force_neon, target_arch = "aarch64", target_feature = "neon"))] {
pub(crate) mod neon;
} else {
pub(crate) mod soft;
}
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/legacy.rs������������������������������������������������������������������������0000644�0000000�0000000�00000004152�10461020230�0013607�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! Legacy version of ChaCha20 with a 64-bit nonce
use super::{ChaChaCore, Key, Nonce};
use cipher::{
consts::{U10, U32, U64, U8},
generic_array::GenericArray,
BlockSizeUser, IvSizeUser, KeyIvInit, KeySizeUser, StreamCipherCore, StreamCipherCoreWrapper,
StreamCipherSeekCore, StreamClosure,
};
#[cfg(feature = "zeroize")]
use cipher::zeroize::ZeroizeOnDrop;
/// Nonce type used by [`ChaCha20Legacy`].
pub type LegacyNonce = GenericArray;
/// The ChaCha20 stream cipher (legacy "djb" construction with 64-bit nonce).
///
/// **WARNING:** this implementation uses 32-bit counter, while the original
/// implementation uses 64-bit counter. In other words, it does
/// not allow encrypting of more than 256 GiB of data.
pub type ChaCha20Legacy = StreamCipherCoreWrapper;
/// The ChaCha20 stream cipher (legacy "djb" construction with 64-bit nonce).
pub struct ChaCha20LegacyCore(ChaChaCore);
impl KeySizeUser for ChaCha20LegacyCore {
type KeySize = U32;
}
impl IvSizeUser for ChaCha20LegacyCore {
type IvSize = U8;
}
impl BlockSizeUser for ChaCha20LegacyCore {
type BlockSize = U64;
}
impl KeyIvInit for ChaCha20LegacyCore {
#[inline(always)]
fn new(key: &Key, iv: &LegacyNonce) -> Self {
let mut padded_iv = Nonce::default();
padded_iv[4..].copy_from_slice(iv);
ChaCha20LegacyCore(ChaChaCore::new(key, &padded_iv))
}
}
impl StreamCipherCore for ChaCha20LegacyCore {
#[inline(always)]
fn remaining_blocks(&self) -> Option {
self.0.remaining_blocks()
}
#[inline(always)]
fn process_with_backend(&mut self, f: impl StreamClosure) {
self.0.process_with_backend(f);
}
}
impl StreamCipherSeekCore for ChaCha20LegacyCore {
type Counter = u32;
#[inline(always)]
fn get_block_pos(&self) -> u32 {
self.0.get_block_pos()
}
#[inline(always)]
fn set_block_pos(&mut self, pos: u32) {
self.0.set_block_pos(pos);
}
}
#[cfg(feature = "zeroize")]
#[cfg_attr(docsrs, doc(cfg(feature = "zeroize")))]
impl ZeroizeOnDrop for ChaCha20LegacyCore {}
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/lib.rs���������������������������������������������������������������������������0000644�0000000�0000000�00000025400�10461020230�0013110�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! Implementation of the [ChaCha] family of stream ciphers.
//!
//! Cipher functionality is accessed using traits from re-exported [`cipher`] crate.
//!
//! ChaCha stream ciphers are lightweight and amenable to fast, constant-time
//! implementations in software. It improves upon the previous [Salsa] design,
//! providing increased per-round diffusion with no cost to performance.
//!
//! This crate contains the following variants of the ChaCha20 core algorithm:
//!
//! - [`ChaCha20`]: standard IETF variant with 96-bit nonce
//! - [`ChaCha8`] / [`ChaCha12`]: reduced round variants of ChaCha20
//! - [`XChaCha20`]: 192-bit extended nonce variant
//! - [`XChaCha8`] / [`XChaCha12`]: reduced round variants of XChaCha20
//! - [`ChaCha20Legacy`]: "djb" variant with 64-bit nonce.
//! **WARNING:** This implementation internally uses 32-bit counter,
//! while the original implementation uses 64-bit counter. In other words,
//! it does not allow encryption of more than 256 GiB of data.
//!
//! # ⚠️ Security Warning: Hazmat!
//!
//! This crate does not ensure ciphertexts are authentic, which can lead to
//! serious vulnerabilities if used incorrectly!
//!
//! If in doubt, use the [`chacha20poly1305`] crate instead, which provides
//! an authenticated mode on top of ChaCha20.
//!
//! **USE AT YOUR OWN RISK!**
//!
//! # Diagram
//!
//! This diagram illustrates the ChaCha quarter round function.
//! Each round consists of four quarter-rounds:
//!
//! 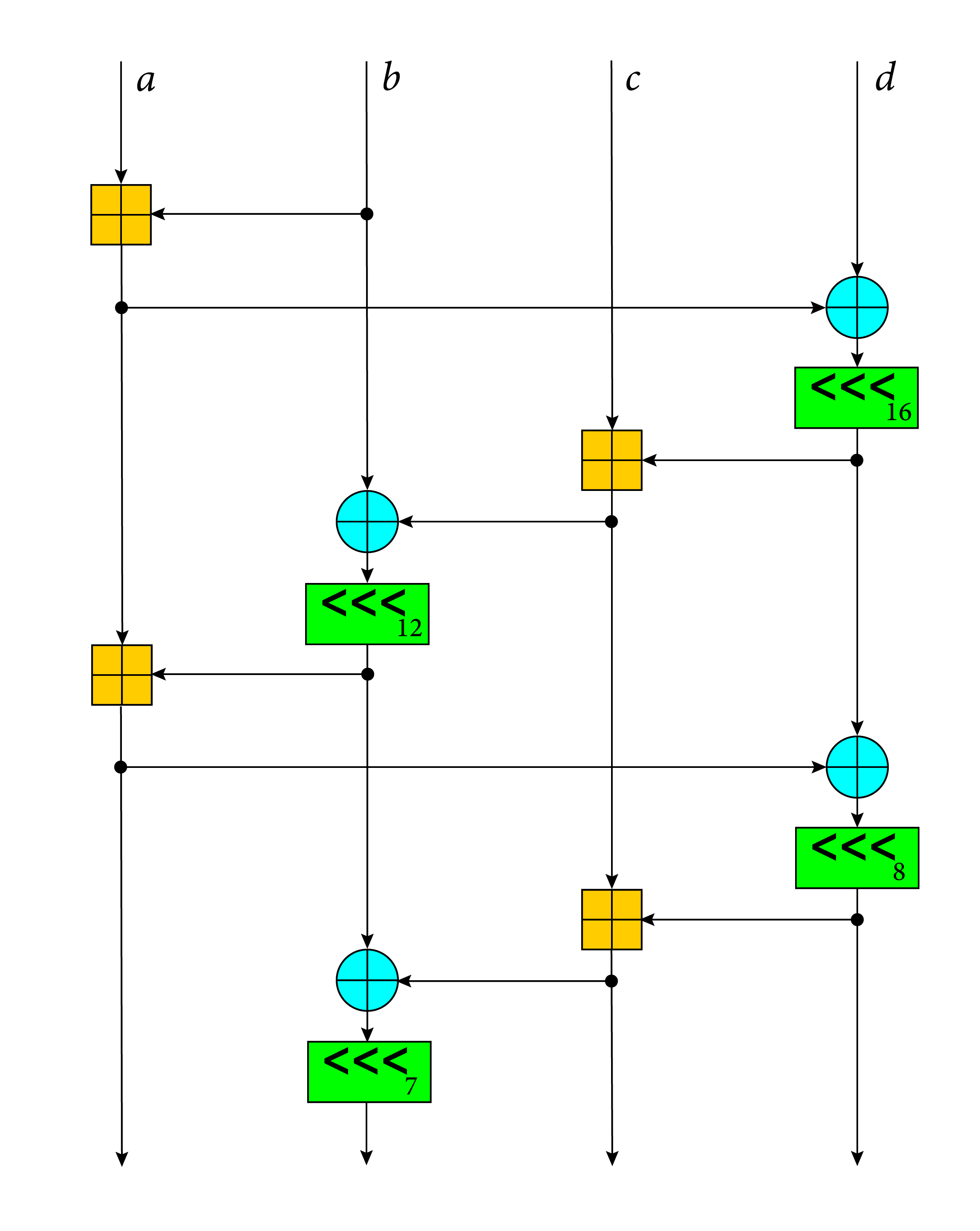 //!
//! Legend:
//!
//! - ⊞ add
//! - ‹‹‹ rotate
//! - ⊕ xor
//!
//! # Example
//! ```
//! use chacha20::ChaCha20;
//! // Import relevant traits
//! use chacha20::cipher::{KeyIvInit, StreamCipher, StreamCipherSeek};
//! use hex_literal::hex;
//!
//! let key = [0x42; 32];
//! let nonce = [0x24; 12];
//! let plaintext = hex!("00010203 04050607 08090A0B 0C0D0E0F");
//! let ciphertext = hex!("e405626e 4f1236b3 670ee428 332ea20e");
//!
//! // Key and IV must be references to the `GenericArray` type.
//! // Here we use the `Into` trait to convert arrays into it.
//! let mut cipher = ChaCha20::new(&key.into(), &nonce.into());
//!
//! let mut buffer = plaintext.clone();
//!
//! // apply keystream (encrypt)
//! cipher.apply_keystream(&mut buffer);
//! assert_eq!(buffer, ciphertext);
//!
//! let ciphertext = buffer.clone();
//!
//! // ChaCha ciphers support seeking
//! cipher.seek(0u32);
//!
//! // decrypt ciphertext by applying keystream again
//! cipher.apply_keystream(&mut buffer);
//! assert_eq!(buffer, plaintext);
//!
//! // stream ciphers can be used with streaming messages
//! cipher.seek(0u32);
//! for chunk in buffer.chunks_mut(3) {
//! cipher.apply_keystream(chunk);
//! }
//! assert_eq!(buffer, ciphertext);
//! ```
//!
//! # Configuration Flags
//!
//! You can modify crate using the following configuration flags:
//!
//! - `chacha20_force_avx2`: force AVX2 backend on x86/x86_64 targets.
//! Requires enabled AVX2 target feature. Ignored on non-x86(-64) targets.
//! - `chacha20_force_neon`: force NEON backend on ARM targets.
//! Requires enabled NEON target feature. Ignored on non-ARM targets. Nightly-only.
//! - `chacha20_force_soft`: force software backend.
//! - `chacha20_force_sse2`: force SSE2 backend on x86/x86_64 targets.
//! Requires enabled SSE2 target feature. Ignored on non-x86(-64) targets.
//!
//! The flags can be enabled using `RUSTFLAGS` environmental variable
//! (e.g. `RUSTFLAGS="--cfg chacha20_force_avx2"`) or by modifying `.cargo/config`.
//!
//! You SHOULD NOT enable several `force` flags simultaneously.
//!
//! [ChaCha]: https://tools.ietf.org/html/rfc8439
//! [Salsa]: https://en.wikipedia.org/wiki/Salsa20
//! [`chacha20poly1305`]: https://docs.rs/chacha20poly1305
#![no_std]
#![cfg_attr(docsrs, feature(doc_cfg))]
#![doc(
html_logo_url = "https://raw.githubusercontent.com/RustCrypto/media/8f1a9894/logo.svg",
html_favicon_url = "https://raw.githubusercontent.com/RustCrypto/media/8f1a9894/logo.svg"
)]
#![allow(clippy::needless_range_loop)]
#![warn(missing_docs, rust_2018_idioms, trivial_casts, unused_qualifications)]
pub use cipher;
use cfg_if::cfg_if;
use cipher::{
consts::{U10, U12, U32, U4, U6, U64},
generic_array::{typenum::Unsigned, GenericArray},
BlockSizeUser, IvSizeUser, KeyIvInit, KeySizeUser, StreamCipherCore, StreamCipherCoreWrapper,
StreamCipherSeekCore, StreamClosure,
};
use core::marker::PhantomData;
#[cfg(feature = "zeroize")]
use cipher::zeroize::{Zeroize, ZeroizeOnDrop};
mod backends;
mod legacy;
mod xchacha;
pub use legacy::{ChaCha20Legacy, ChaCha20LegacyCore, LegacyNonce};
pub use xchacha::{hchacha, XChaCha12, XChaCha20, XChaCha8, XChaChaCore, XNonce};
/// State initialization constant ("expand 32-byte k")
const CONSTANTS: [u32; 4] = [0x6170_7865, 0x3320_646e, 0x7962_2d32, 0x6b20_6574];
/// Number of 32-bit words in the ChaCha state
const STATE_WORDS: usize = 16;
/// Block type used by all ChaCha variants.
type Block = GenericArray;
/// Key type used by all ChaCha variants.
pub type Key = GenericArray;
/// Nonce type used by ChaCha variants.
pub type Nonce = GenericArray;
/// ChaCha8 stream cipher (reduced-round variant of [`ChaCha20`] with 8 rounds)
pub type ChaCha8 = StreamCipherCoreWrapper>;
/// ChaCha12 stream cipher (reduced-round variant of [`ChaCha20`] with 12 rounds)
pub type ChaCha12 = StreamCipherCoreWrapper>;
/// ChaCha20 stream cipher (RFC 8439 version with 96-bit nonce)
pub type ChaCha20 = StreamCipherCoreWrapper>;
cfg_if! {
if #[cfg(chacha20_force_soft)] {
type Tokens = ();
} else if #[cfg(any(target_arch = "x86", target_arch = "x86_64"))] {
cfg_if! {
if #[cfg(chacha20_force_avx2)] {
#[cfg(not(target_feature = "avx2"))]
compile_error!("You must enable `avx2` target feature with \
`chacha20_force_avx2` configuration option");
type Tokens = ();
} else if #[cfg(chacha20_force_sse2)] {
#[cfg(not(target_feature = "sse2"))]
compile_error!("You must enable `sse2` target feature with \
`chacha20_force_sse2` configuration option");
type Tokens = ();
} else {
cpufeatures::new!(avx2_cpuid, "avx2");
cpufeatures::new!(sse2_cpuid, "sse2");
type Tokens = (avx2_cpuid::InitToken, sse2_cpuid::InitToken);
}
}
} else {
type Tokens = ();
}
}
/// The ChaCha core function.
pub struct ChaChaCore {
/// Internal state of the core function
state: [u32; STATE_WORDS],
/// CPU target feature tokens
#[allow(dead_code)]
tokens: Tokens,
/// Number of rounds to perform
rounds: PhantomData,
}
impl KeySizeUser for ChaChaCore {
type KeySize = U32;
}
impl IvSizeUser for ChaChaCore {
type IvSize = U12;
}
impl BlockSizeUser for ChaChaCore {
type BlockSize = U64;
}
impl KeyIvInit for ChaChaCore {
#[inline]
fn new(key: &Key, iv: &Nonce) -> Self {
let mut state = [0u32; STATE_WORDS];
state[0..4].copy_from_slice(&CONSTANTS);
let key_chunks = key.chunks_exact(4);
for (val, chunk) in state[4..12].iter_mut().zip(key_chunks) {
*val = u32::from_le_bytes(chunk.try_into().unwrap());
}
let iv_chunks = iv.chunks_exact(4);
for (val, chunk) in state[13..16].iter_mut().zip(iv_chunks) {
*val = u32::from_le_bytes(chunk.try_into().unwrap());
}
cfg_if! {
if #[cfg(chacha20_force_soft)] {
let tokens = ();
} else if #[cfg(any(target_arch = "x86", target_arch = "x86_64"))] {
cfg_if! {
if #[cfg(chacha20_force_avx2)] {
let tokens = ();
} else if #[cfg(chacha20_force_sse2)] {
let tokens = ();
} else {
let tokens = (avx2_cpuid::init(), sse2_cpuid::init());
}
}
} else {
let tokens = ();
}
}
Self {
state,
tokens,
rounds: PhantomData,
}
}
}
impl StreamCipherCore for ChaChaCore {
#[inline(always)]
fn remaining_blocks(&self) -> Option {
let rem = u32::MAX - self.get_block_pos();
rem.try_into().ok()
}
fn process_with_backend(&mut self, f: impl StreamClosure) {
cfg_if! {
if #[cfg(chacha20_force_soft)] {
f.call(&mut backends::soft::Backend(self));
} else if #[cfg(any(target_arch = "x86", target_arch = "x86_64"))] {
cfg_if! {
if #[cfg(chacha20_force_avx2)] {
unsafe {
backends::avx2::inner::(&mut self.state, f);
}
} else if #[cfg(chacha20_force_sse2)] {
unsafe {
backends::sse2::inner::(&mut self.state, f);
}
} else {
let (avx2_token, sse2_token) = self.tokens;
if avx2_token.get() {
unsafe {
backends::avx2::inner::(&mut self.state, f);
}
} else if sse2_token.get() {
unsafe {
backends::sse2::inner::(&mut self.state, f);
}
} else {
f.call(&mut backends::soft::Backend(self));
}
}
}
} else if #[cfg(all(chacha20_force_neon, target_arch = "aarch64", target_feature = "neon"))] {
unsafe {
backends::neon::inner::(&mut self.state, f);
}
} else {
f.call(&mut backends::soft::Backend(self));
}
}
}
}
impl StreamCipherSeekCore for ChaChaCore {
type Counter = u32;
#[inline(always)]
fn get_block_pos(&self) -> u32 {
self.state[12]
}
#[inline(always)]
fn set_block_pos(&mut self, pos: u32) {
self.state[12] = pos;
}
}
#[cfg(feature = "zeroize")]
#[cfg_attr(docsrs, doc(cfg(feature = "zeroize")))]
impl Drop for ChaChaCore {
fn drop(&mut self) {
self.state.zeroize();
}
}
#[cfg(feature = "zeroize")]
#[cfg_attr(docsrs, doc(cfg(feature = "zeroize")))]
impl ZeroizeOnDrop for ChaChaCore {}
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/xchacha.rs�����������������������������������������������������������������������0000644�0000000�0000000�00000014234�10461020230�0013744�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! XChaCha is an extended nonce variant of ChaCha
use super::{ChaChaCore, Key, Nonce, CONSTANTS, STATE_WORDS};
use cipher::{
consts::{U10, U16, U24, U32, U4, U6, U64},
generic_array::{typenum::Unsigned, GenericArray},
BlockSizeUser, IvSizeUser, KeyIvInit, KeySizeUser, StreamCipherCore, StreamCipherCoreWrapper,
StreamCipherSeekCore, StreamClosure,
};
#[cfg(feature = "zeroize")]
use cipher::zeroize::ZeroizeOnDrop;
/// Nonce type used by XChaCha variants.
pub type XNonce = GenericArray;
/// XChaCha is a ChaCha20 variant with an extended 192-bit (24-byte) nonce.
///
/// The construction is an adaptation of the same techniques used by
/// XChaCha as described in the paper "Extending the Salsa20 Nonce",
/// applied to the 96-bit nonce variant of ChaCha20, and derive a
/// separate subkey/nonce for each extended nonce:
///
///
///
/// No authoritative specification exists for XChaCha20, however the
/// construction has "rough consensus and running code" in the form of
/// several interoperable libraries and protocols (e.g. libsodium, WireGuard)
/// and is documented in an (expired) IETF draft:
///
///
pub type XChaCha20 = StreamCipherCoreWrapper>;
/// XChaCha12 stream cipher (reduced-round variant of [`XChaCha20`] with 12 rounds)
pub type XChaCha12 = StreamCipherCoreWrapper>;
/// XChaCha8 stream cipher (reduced-round variant of [`XChaCha20`] with 8 rounds)
pub type XChaCha8 = StreamCipherCoreWrapper>;
/// The XChaCha core function.
pub struct XChaChaCore(ChaChaCore);
impl KeySizeUser for XChaChaCore {
type KeySize = U32;
}
impl IvSizeUser for XChaChaCore {
type IvSize = U24;
}
impl BlockSizeUser for XChaChaCore {
type BlockSize = U64;
}
impl KeyIvInit for XChaChaCore {
fn new(key: &Key, iv: &XNonce) -> Self {
let subkey = hchacha::(key, iv[..16].as_ref().into());
let mut padded_iv = Nonce::default();
padded_iv[4..].copy_from_slice(&iv[16..]);
XChaChaCore(ChaChaCore::new(&subkey, &padded_iv))
}
}
impl StreamCipherCore for XChaChaCore {
#[inline(always)]
fn remaining_blocks(&self) -> Option {
self.0.remaining_blocks()
}
#[inline(always)]
fn process_with_backend(&mut self, f: impl StreamClosure) {
self.0.process_with_backend(f);
}
}
impl StreamCipherSeekCore for XChaChaCore {
type Counter = u32;
#[inline(always)]
fn get_block_pos(&self) -> u32 {
self.0.get_block_pos()
}
#[inline(always)]
fn set_block_pos(&mut self, pos: u32) {
self.0.set_block_pos(pos);
}
}
#[cfg(feature = "zeroize")]
#[cfg_attr(docsrs, doc(cfg(feature = "zeroize")))]
impl ZeroizeOnDrop for XChaChaCore {}
/// The HChaCha function: adapts the ChaCha core function in the same
/// manner that HSalsa adapts the Salsa function.
///
/// HChaCha takes 512-bits of input:
///
/// - Constants: `u32` x 4
/// - Key: `u32` x 8
/// - Nonce: `u32` x 4
///
/// It produces 256-bits of output suitable for use as a ChaCha key
///
/// For more information on HSalsa on which HChaCha is based, see:
///
///
pub fn hchacha(key: &Key, input: &GenericArray) -> GenericArray {
let mut state = [0u32; STATE_WORDS];
state[..4].copy_from_slice(&CONSTANTS);
let key_chunks = key.chunks_exact(4);
for (v, chunk) in state[4..12].iter_mut().zip(key_chunks) {
*v = u32::from_le_bytes(chunk.try_into().unwrap());
}
let input_chunks = input.chunks_exact(4);
for (v, chunk) in state[12..16].iter_mut().zip(input_chunks) {
*v = u32::from_le_bytes(chunk.try_into().unwrap());
}
// R rounds consisting of R/2 column rounds and R/2 diagonal rounds
for _ in 0..R::USIZE {
// column rounds
quarter_round(0, 4, 8, 12, &mut state);
quarter_round(1, 5, 9, 13, &mut state);
quarter_round(2, 6, 10, 14, &mut state);
quarter_round(3, 7, 11, 15, &mut state);
// diagonal rounds
quarter_round(0, 5, 10, 15, &mut state);
quarter_round(1, 6, 11, 12, &mut state);
quarter_round(2, 7, 8, 13, &mut state);
quarter_round(3, 4, 9, 14, &mut state);
}
let mut output = GenericArray::default();
for (chunk, val) in output[..16].chunks_exact_mut(4).zip(&state[..4]) {
chunk.copy_from_slice(&val.to_le_bytes());
}
for (chunk, val) in output[16..].chunks_exact_mut(4).zip(&state[12..]) {
chunk.copy_from_slice(&val.to_le_bytes());
}
output
}
/// The ChaCha20 quarter round function
// for simplicity this function is copied from the software backend
fn quarter_round(a: usize, b: usize, c: usize, d: usize, state: &mut [u32; STATE_WORDS]) {
state[a] = state[a].wrapping_add(state[b]);
state[d] ^= state[a];
state[d] = state[d].rotate_left(16);
state[c] = state[c].wrapping_add(state[d]);
state[b] ^= state[c];
state[b] = state[b].rotate_left(12);
state[a] = state[a].wrapping_add(state[b]);
state[d] ^= state[a];
state[d] = state[d].rotate_left(8);
state[c] = state[c].wrapping_add(state[d]);
state[b] ^= state[c];
state[b] = state[b].rotate_left(7);
}
#[cfg(test)]
mod hchacha20_tests {
use super::*;
use hex_literal::hex;
/// Test vectors from:
/// https://tools.ietf.org/id/draft-arciszewski-xchacha-03.html#rfc.section.2.2.1
#[test]
fn test_vector() {
const KEY: [u8; 32] = hex!(
"000102030405060708090a0b0c0d0e0f"
"101112131415161718191a1b1c1d1e1f"
);
const INPUT: [u8; 16] = hex!("000000090000004a0000000031415927");
const OUTPUT: [u8; 32] = hex!(
"82413b4227b27bfed30e42508a877d73"
"a0f9e4d58a74a853c12ec41326d3ecdc"
);
let actual = hchacha::(
GenericArray::from_slice(&KEY),
&GenericArray::from_slice(&INPUT),
);
assert_eq!(actual.as_slice(), &OUTPUT);
}
}
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/tests/data/chacha20-legacy.blb�������������������������������������������������������0000644�0000000�0000000�00000002025�10461020230�0016552�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������@���������������������������������������������������������������� ����������������������������������������������v�ୠ�=�@]j�S��(���������6�̋w
��AY|QWH�w$�?��J7jC�������i��e���������������?����x���5�=�;� c�4��B�3���8�
2��L�#~�<��d&�J�T]�Iz�Fn}k����/Xk����������x������������������������������������������������������������xޜ�{�֞���c�?e:�I������O�}�7��1�Z��x��E'!Os���[Rw�.��C>D_A�@������������������������������������E@�Z�����sn{ �<��O�F��`OE R�C-A�⠶�ufҥ���
B�,Sג��?�~��u�Tic@��������
��
������������������ ������ ������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������k�������:��Ԓ�ݘ$oii���f�;�#W���l��l.e�K��-5�*�9Cpi���1�����5��N�GN�)�`����~�{Ld�٬h[��l���8������0S`6�X*��Y������-������;�q�O�$e�3j�D���]�����p�%���q������oydCqs��uV�X�z��J4�=��r��6�����N�1��? �=������TJh�u$ �k�R�Q�.2������ �XJ�V�uF̢M����%ֱ^ꃶ�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/tests/data/chacha20.blb��������������������������������������������������������������0000644�0000000�0000000�00000001454�10461020230�0015315�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������@���������������������������������������������������������������� �������������������������������������v�ୠ�=�@]j�S��(���������6�̋w
��AY|QWH�w$�?��J7jC������Ç�i��e�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������M7��67J����?���"��ߤ�r�v[T�'NJ����\��t���_����b���9S��m��(��N�T�"¡�4�U�>�9���# Hj�������^���p��w���U�����Ƃ�E@�-�����k���T�V&O���T����D��R����I�_�ț.?.
����K�e�¶��-�$�St�g����������ь�l���v�p�3���Όl��Ml�����*�m���SH��}۰_}�;�Ɩ05v�ڎv���P/f�@������������������������������������E@�Z�����sn{ �<��O�F��`OE R�C-A�⠶�ufҥ���
B�,Sג��?�~��u�Tic��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/tests/mod.rs�������������������������������������������������������������������������0000644�0000000�0000000�00000020106�10461020230�0013472�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! Tests for ChaCha20 (IETF and "djb" versions) as well as XChaCha20
use chacha20::{ChaCha20, ChaCha20Legacy, XChaCha20};
// IETF version of ChaCha20 (96-bit nonce)
cipher::stream_cipher_test!(chacha20_core, "chacha20", ChaCha20);
cipher::stream_cipher_seek_test!(chacha20_seek, ChaCha20);
cipher::stream_cipher_seek_test!(xchacha20_seek, XChaCha20);
cipher::stream_cipher_seek_test!(chacha20legacy_seek, ChaCha20Legacy);
mod chacha20test {
use chacha20::{ChaCha20, Key, Nonce};
use cipher::{KeyIvInit, StreamCipher};
use hex_literal::hex;
//
// ChaCha20 test vectors from:
//
//
const KEY: [u8; 32] = hex!("000102030405060708090a0b0c0d0e0f101112131415161718191a1b1c1d1e1f");
const IV: [u8; 12] = hex!("000000000000004a00000000");
const PLAINTEXT: [u8; 114] = hex!(
"
4c616469657320616e642047656e746c
656d656e206f662074686520636c6173
73206f66202739393a20496620492063
6f756c64206f6666657220796f75206f
6e6c79206f6e652074697020666f7220
746865206675747572652c2073756e73
637265656e20776f756c642062652069
742e
"
);
const KEYSTREAM: [u8; 114] = hex!(
"
224f51f3401bd9e12fde276fb8631ded8c131f823d2c06
e27e4fcaec9ef3cf788a3b0aa372600a92b57974cded2b
9334794cba40c63e34cdea212c4cf07d41b769a6749f3f
630f4122cafe28ec4dc47e26d4346d70b98c73f3e9c53a
c40c5945398b6eda1a832c89c167eacd901d7e2bf363
"
);
const CIPHERTEXT: [u8; 114] = hex!(
"
6e2e359a2568f98041ba0728dd0d6981
e97e7aec1d4360c20a27afccfd9fae0b
f91b65c5524733ab8f593dabcd62b357
1639d624e65152ab8f530c359f0861d8
07ca0dbf500d6a6156a38e088a22b65e
52bc514d16ccf806818ce91ab7793736
5af90bbf74a35be6b40b8eedf2785e42
874d
"
);
#[test]
fn chacha20_keystream() {
let mut cipher = ChaCha20::new(&Key::from(KEY), &Nonce::from(IV));
// The test vectors omit the first 64-bytes of the keystream
let mut prefix = [0u8; 64];
cipher.apply_keystream(&mut prefix);
let mut buf = [0u8; 114];
cipher.apply_keystream(&mut buf);
assert_eq!(&buf[..], &KEYSTREAM[..]);
}
#[test]
fn chacha20_encryption() {
let mut cipher = ChaCha20::new(&Key::from(KEY), &Nonce::from(IV));
let mut buf = PLAINTEXT.clone();
// The test vectors omit the first 64-bytes of the keystream
let mut prefix = [0u8; 64];
cipher.apply_keystream(&mut prefix);
cipher.apply_keystream(&mut buf);
assert_eq!(&buf[..], &CIPHERTEXT[..]);
}
}
#[rustfmt::skip]
mod xchacha20 {
use chacha20::{Key, XChaCha20, XNonce};
use cipher::{KeyIvInit, StreamCipher};
use hex_literal::hex;
cipher::stream_cipher_seek_test!(xchacha20_seek, XChaCha20);
//
// XChaCha20 test vectors from:
//
//
const KEY: [u8; 32] = hex!("
808182838485868788898a8b8c8d8e8f909192939495969798999a9b9c9d9e9f
");
const IV: [u8; 24] = hex!("
404142434445464748494a4b4c4d4e4f5051525354555658
");
const PLAINTEXT: [u8; 304] = hex!("
5468652064686f6c65202870726f6e6f756e6365642022646f6c652229206973
20616c736f206b6e6f776e2061732074686520417369617469632077696c6420
646f672c2072656420646f672c20616e642077686973746c696e6720646f672e
2049742069732061626f7574207468652073697a65206f662061204765726d61
6e20736865706865726420627574206c6f6f6b73206d6f7265206c696b652061
206c6f6e672d6c656767656420666f782e205468697320686967686c7920656c
757369766520616e6420736b696c6c6564206a756d70657220697320636c6173
736966696564207769746820776f6c7665732c20636f796f7465732c206a6163
6b616c732c20616e6420666f78657320696e20746865207461786f6e6f6d6963
2066616d696c792043616e696461652e
");
const KEYSTREAM: [u8; 304] = hex!("
29624b4b1b140ace53740e405b2168540fd7d630c1f536fecd722fc3cddba7f4
cca98cf9e47e5e64d115450f9b125b54449ff76141ca620a1f9cfcab2a1a8a25
5e766a5266b878846120ea64ad99aa479471e63befcbd37cd1c22a221fe46221
5cf32c74895bf505863ccddd48f62916dc6521f1ec50a5ae08903aa259d9bf60
7cd8026fba548604f1b6072d91bc91243a5b845f7fd171b02edc5a0a84cf28dd
241146bc376e3f48df5e7fee1d11048c190a3d3deb0feb64b42d9c6fdeee290f
a0e6ae2c26c0249ea8c181f7e2ffd100cbe5fd3c4f8271d62b15330cb8fdcf00
b3df507ca8c924f7017b7e712d15a2eb5c50484451e54e1b4b995bd8fdd94597
bb94d7af0b2c04df10ba0890899ed9293a0f55b8bafa999264035f1d4fbe7fe0
aafa109a62372027e50e10cdfecca127
");
const CIPHERTEXT: [u8; 304] = hex!("
7d0a2e6b7f7c65a236542630294e063b7ab9b555a5d5149aa21e4ae1e4fbce87
ecc8e08a8b5e350abe622b2ffa617b202cfad72032a3037e76ffdcdc4376ee05
3a190d7e46ca1de04144850381b9cb29f051915386b8a710b8ac4d027b8b050f
7cba5854e028d564e453b8a968824173fc16488b8970cac828f11ae53cabd201
12f87107df24ee6183d2274fe4c8b1485534ef2c5fbc1ec24bfc3663efaa08bc
047d29d25043532db8391a8a3d776bf4372a6955827ccb0cdd4af403a7ce4c63
d595c75a43e045f0cce1f29c8b93bd65afc5974922f214a40b7c402cdb91ae73
c0b63615cdad0480680f16515a7ace9d39236464328a37743ffc28f4ddb324f4
d0f5bbdc270c65b1749a6efff1fbaa09536175ccd29fb9e6057b307320d31683
8a9c71f70b5b5907a66f7ea49aadc409
");
#[test]
fn xchacha20_keystream() {
let mut cipher = XChaCha20::new(&Key::from(KEY), &XNonce::from(IV));
// The test vectors omit the first 64-bytes of the keystream
let mut prefix = [0u8; 64];
cipher.apply_keystream(&mut prefix);
let mut buf = [0u8; 304];
cipher.apply_keystream(&mut buf);
assert_eq!(&buf[..], &KEYSTREAM[..]);
}
#[test]
fn xchacha20_encryption() {
let mut cipher = XChaCha20::new(&Key::from(KEY), &XNonce::from(IV));
let mut buf = PLAINTEXT.clone();
// The test vectors omit the first 64-bytes of the keystream
let mut prefix = [0u8; 64];
cipher.apply_keystream(&mut prefix);
cipher.apply_keystream(&mut buf);
assert_eq!(&buf[..], &CIPHERTEXT[..]);
}
}
// Legacy "djb" version of ChaCha20 (64-bit nonce)
#[cfg(feature = "legacy")]
#[rustfmt::skip]
mod legacy {
use chacha20::{ChaCha20Legacy, Key, LegacyNonce};
use cipher::{NewCipher, StreamCipher, StreamCipherSeek};
use hex_literal::hex;
cipher::stream_cipher_test!(chacha20_legacy_core, ChaCha20Legacy, "chacha20-legacy");
cipher::stream_cipher_seek_test!(chacha20_legacy_seek, ChaCha20Legacy);
const KEY_LONG: [u8; 32] = hex!("
0102030405060708090a0b0c0d0e0f101112131415161718191a1b1c1d1e1f20
");
const IV_LONG: [u8; 8] = hex!("0301040105090206");
const EXPECTED_LONG: [u8; 256] = hex!("
deeb6b9d06dff3e091bf3ad4f4d492b6dd98246f69691802e466e03bad235787
0f1c6c010b6c2e650c4bf58d2d35c72ab639437069a384e03100078cc1d735a0
db4e8f474ee6291460fd9197c77ed87b4c64e0d9ac685bd1c56cce021f3819cd
13f49c9a3053603602582a060e59c2fbee90ab0bf7bb102d819ced03969d3bae
71034fe598246583336aa744d8168e5dfff5c6d10270f125a4130e719717e783
c0858b6f7964437173ea1d7556c158bc7a99e74a34d93da6bf72ac9736a215ac
aefd4ec031f3f13f099e3d811d83a2cf1d544a68d2752409cc6be852b0511a2e
32f69aa0be91b30981584a1c56ce7546cca24d8cfdfca525d6b15eea83b6b686
");
#[test]
#[ignore]
fn chacha20_offsets() {
for idx in 0..256 {
for middle in idx..256 {
for last in middle..256 {
let mut cipher =
ChaCha20Legacy::new(&Key::from(KEY_LONG), &LegacyNonce::from(IV_LONG));
let mut buf = [0; 256];
cipher.seek(idx as u64);
cipher.apply_keystream(&mut buf[idx..middle]);
cipher.apply_keystream(&mut buf[middle..last]);
for k in idx..last {
assert_eq!(buf[k], EXPECTED_LONG[k])
}
}
}
}
}
}
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
//!
//! Legend:
//!
//! - ⊞ add
//! - ‹‹‹ rotate
//! - ⊕ xor
//!
//! # Example
//! ```
//! use chacha20::ChaCha20;
//! // Import relevant traits
//! use chacha20::cipher::{KeyIvInit, StreamCipher, StreamCipherSeek};
//! use hex_literal::hex;
//!
//! let key = [0x42; 32];
//! let nonce = [0x24; 12];
//! let plaintext = hex!("00010203 04050607 08090A0B 0C0D0E0F");
//! let ciphertext = hex!("e405626e 4f1236b3 670ee428 332ea20e");
//!
//! // Key and IV must be references to the `GenericArray` type.
//! // Here we use the `Into` trait to convert arrays into it.
//! let mut cipher = ChaCha20::new(&key.into(), &nonce.into());
//!
//! let mut buffer = plaintext.clone();
//!
//! // apply keystream (encrypt)
//! cipher.apply_keystream(&mut buffer);
//! assert_eq!(buffer, ciphertext);
//!
//! let ciphertext = buffer.clone();
//!
//! // ChaCha ciphers support seeking
//! cipher.seek(0u32);
//!
//! // decrypt ciphertext by applying keystream again
//! cipher.apply_keystream(&mut buffer);
//! assert_eq!(buffer, plaintext);
//!
//! // stream ciphers can be used with streaming messages
//! cipher.seek(0u32);
//! for chunk in buffer.chunks_mut(3) {
//! cipher.apply_keystream(chunk);
//! }
//! assert_eq!(buffer, ciphertext);
//! ```
//!
//! # Configuration Flags
//!
//! You can modify crate using the following configuration flags:
//!
//! - `chacha20_force_avx2`: force AVX2 backend on x86/x86_64 targets.
//! Requires enabled AVX2 target feature. Ignored on non-x86(-64) targets.
//! - `chacha20_force_neon`: force NEON backend on ARM targets.
//! Requires enabled NEON target feature. Ignored on non-ARM targets. Nightly-only.
//! - `chacha20_force_soft`: force software backend.
//! - `chacha20_force_sse2`: force SSE2 backend on x86/x86_64 targets.
//! Requires enabled SSE2 target feature. Ignored on non-x86(-64) targets.
//!
//! The flags can be enabled using `RUSTFLAGS` environmental variable
//! (e.g. `RUSTFLAGS="--cfg chacha20_force_avx2"`) or by modifying `.cargo/config`.
//!
//! You SHOULD NOT enable several `force` flags simultaneously.
//!
//! [ChaCha]: https://tools.ietf.org/html/rfc8439
//! [Salsa]: https://en.wikipedia.org/wiki/Salsa20
//! [`chacha20poly1305`]: https://docs.rs/chacha20poly1305
#![no_std]
#![cfg_attr(docsrs, feature(doc_cfg))]
#![doc(
html_logo_url = "https://raw.githubusercontent.com/RustCrypto/media/8f1a9894/logo.svg",
html_favicon_url = "https://raw.githubusercontent.com/RustCrypto/media/8f1a9894/logo.svg"
)]
#![allow(clippy::needless_range_loop)]
#![warn(missing_docs, rust_2018_idioms, trivial_casts, unused_qualifications)]
pub use cipher;
use cfg_if::cfg_if;
use cipher::{
consts::{U10, U12, U32, U4, U6, U64},
generic_array::{typenum::Unsigned, GenericArray},
BlockSizeUser, IvSizeUser, KeyIvInit, KeySizeUser, StreamCipherCore, StreamCipherCoreWrapper,
StreamCipherSeekCore, StreamClosure,
};
use core::marker::PhantomData;
#[cfg(feature = "zeroize")]
use cipher::zeroize::{Zeroize, ZeroizeOnDrop};
mod backends;
mod legacy;
mod xchacha;
pub use legacy::{ChaCha20Legacy, ChaCha20LegacyCore, LegacyNonce};
pub use xchacha::{hchacha, XChaCha12, XChaCha20, XChaCha8, XChaChaCore, XNonce};
/// State initialization constant ("expand 32-byte k")
const CONSTANTS: [u32; 4] = [0x6170_7865, 0x3320_646e, 0x7962_2d32, 0x6b20_6574];
/// Number of 32-bit words in the ChaCha state
const STATE_WORDS: usize = 16;
/// Block type used by all ChaCha variants.
type Block = GenericArray;
/// Key type used by all ChaCha variants.
pub type Key = GenericArray;
/// Nonce type used by ChaCha variants.
pub type Nonce = GenericArray;
/// ChaCha8 stream cipher (reduced-round variant of [`ChaCha20`] with 8 rounds)
pub type ChaCha8 = StreamCipherCoreWrapper>;
/// ChaCha12 stream cipher (reduced-round variant of [`ChaCha20`] with 12 rounds)
pub type ChaCha12 = StreamCipherCoreWrapper>;
/// ChaCha20 stream cipher (RFC 8439 version with 96-bit nonce)
pub type ChaCha20 = StreamCipherCoreWrapper>;
cfg_if! {
if #[cfg(chacha20_force_soft)] {
type Tokens = ();
} else if #[cfg(any(target_arch = "x86", target_arch = "x86_64"))] {
cfg_if! {
if #[cfg(chacha20_force_avx2)] {
#[cfg(not(target_feature = "avx2"))]
compile_error!("You must enable `avx2` target feature with \
`chacha20_force_avx2` configuration option");
type Tokens = ();
} else if #[cfg(chacha20_force_sse2)] {
#[cfg(not(target_feature = "sse2"))]
compile_error!("You must enable `sse2` target feature with \
`chacha20_force_sse2` configuration option");
type Tokens = ();
} else {
cpufeatures::new!(avx2_cpuid, "avx2");
cpufeatures::new!(sse2_cpuid, "sse2");
type Tokens = (avx2_cpuid::InitToken, sse2_cpuid::InitToken);
}
}
} else {
type Tokens = ();
}
}
/// The ChaCha core function.
pub struct ChaChaCore {
/// Internal state of the core function
state: [u32; STATE_WORDS],
/// CPU target feature tokens
#[allow(dead_code)]
tokens: Tokens,
/// Number of rounds to perform
rounds: PhantomData,
}
impl KeySizeUser for ChaChaCore {
type KeySize = U32;
}
impl IvSizeUser for ChaChaCore {
type IvSize = U12;
}
impl BlockSizeUser for ChaChaCore {
type BlockSize = U64;
}
impl KeyIvInit for ChaChaCore {
#[inline]
fn new(key: &Key, iv: &Nonce) -> Self {
let mut state = [0u32; STATE_WORDS];
state[0..4].copy_from_slice(&CONSTANTS);
let key_chunks = key.chunks_exact(4);
for (val, chunk) in state[4..12].iter_mut().zip(key_chunks) {
*val = u32::from_le_bytes(chunk.try_into().unwrap());
}
let iv_chunks = iv.chunks_exact(4);
for (val, chunk) in state[13..16].iter_mut().zip(iv_chunks) {
*val = u32::from_le_bytes(chunk.try_into().unwrap());
}
cfg_if! {
if #[cfg(chacha20_force_soft)] {
let tokens = ();
} else if #[cfg(any(target_arch = "x86", target_arch = "x86_64"))] {
cfg_if! {
if #[cfg(chacha20_force_avx2)] {
let tokens = ();
} else if #[cfg(chacha20_force_sse2)] {
let tokens = ();
} else {
let tokens = (avx2_cpuid::init(), sse2_cpuid::init());
}
}
} else {
let tokens = ();
}
}
Self {
state,
tokens,
rounds: PhantomData,
}
}
}
impl StreamCipherCore for ChaChaCore {
#[inline(always)]
fn remaining_blocks(&self) -> Option {
let rem = u32::MAX - self.get_block_pos();
rem.try_into().ok()
}
fn process_with_backend(&mut self, f: impl StreamClosure) {
cfg_if! {
if #[cfg(chacha20_force_soft)] {
f.call(&mut backends::soft::Backend(self));
} else if #[cfg(any(target_arch = "x86", target_arch = "x86_64"))] {
cfg_if! {
if #[cfg(chacha20_force_avx2)] {
unsafe {
backends::avx2::inner::(&mut self.state, f);
}
} else if #[cfg(chacha20_force_sse2)] {
unsafe {
backends::sse2::inner::(&mut self.state, f);
}
} else {
let (avx2_token, sse2_token) = self.tokens;
if avx2_token.get() {
unsafe {
backends::avx2::inner::(&mut self.state, f);
}
} else if sse2_token.get() {
unsafe {
backends::sse2::inner::(&mut self.state, f);
}
} else {
f.call(&mut backends::soft::Backend(self));
}
}
}
} else if #[cfg(all(chacha20_force_neon, target_arch = "aarch64", target_feature = "neon"))] {
unsafe {
backends::neon::inner::(&mut self.state, f);
}
} else {
f.call(&mut backends::soft::Backend(self));
}
}
}
}
impl StreamCipherSeekCore for ChaChaCore {
type Counter = u32;
#[inline(always)]
fn get_block_pos(&self) -> u32 {
self.state[12]
}
#[inline(always)]
fn set_block_pos(&mut self, pos: u32) {
self.state[12] = pos;
}
}
#[cfg(feature = "zeroize")]
#[cfg_attr(docsrs, doc(cfg(feature = "zeroize")))]
impl Drop for ChaChaCore {
fn drop(&mut self) {
self.state.zeroize();
}
}
#[cfg(feature = "zeroize")]
#[cfg_attr(docsrs, doc(cfg(feature = "zeroize")))]
impl ZeroizeOnDrop for ChaChaCore {}
����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/src/xchacha.rs�����������������������������������������������������������������������0000644�0000000�0000000�00000014234�10461020230�0013744�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! XChaCha is an extended nonce variant of ChaCha
use super::{ChaChaCore, Key, Nonce, CONSTANTS, STATE_WORDS};
use cipher::{
consts::{U10, U16, U24, U32, U4, U6, U64},
generic_array::{typenum::Unsigned, GenericArray},
BlockSizeUser, IvSizeUser, KeyIvInit, KeySizeUser, StreamCipherCore, StreamCipherCoreWrapper,
StreamCipherSeekCore, StreamClosure,
};
#[cfg(feature = "zeroize")]
use cipher::zeroize::ZeroizeOnDrop;
/// Nonce type used by XChaCha variants.
pub type XNonce = GenericArray;
/// XChaCha is a ChaCha20 variant with an extended 192-bit (24-byte) nonce.
///
/// The construction is an adaptation of the same techniques used by
/// XChaCha as described in the paper "Extending the Salsa20 Nonce",
/// applied to the 96-bit nonce variant of ChaCha20, and derive a
/// separate subkey/nonce for each extended nonce:
///
///
///
/// No authoritative specification exists for XChaCha20, however the
/// construction has "rough consensus and running code" in the form of
/// several interoperable libraries and protocols (e.g. libsodium, WireGuard)
/// and is documented in an (expired) IETF draft:
///
///
pub type XChaCha20 = StreamCipherCoreWrapper>;
/// XChaCha12 stream cipher (reduced-round variant of [`XChaCha20`] with 12 rounds)
pub type XChaCha12 = StreamCipherCoreWrapper>;
/// XChaCha8 stream cipher (reduced-round variant of [`XChaCha20`] with 8 rounds)
pub type XChaCha8 = StreamCipherCoreWrapper>;
/// The XChaCha core function.
pub struct XChaChaCore(ChaChaCore);
impl KeySizeUser for XChaChaCore {
type KeySize = U32;
}
impl IvSizeUser for XChaChaCore {
type IvSize = U24;
}
impl BlockSizeUser for XChaChaCore {
type BlockSize = U64;
}
impl KeyIvInit for XChaChaCore {
fn new(key: &Key, iv: &XNonce) -> Self {
let subkey = hchacha::(key, iv[..16].as_ref().into());
let mut padded_iv = Nonce::default();
padded_iv[4..].copy_from_slice(&iv[16..]);
XChaChaCore(ChaChaCore::new(&subkey, &padded_iv))
}
}
impl StreamCipherCore for XChaChaCore {
#[inline(always)]
fn remaining_blocks(&self) -> Option {
self.0.remaining_blocks()
}
#[inline(always)]
fn process_with_backend(&mut self, f: impl StreamClosure) {
self.0.process_with_backend(f);
}
}
impl StreamCipherSeekCore for XChaChaCore {
type Counter = u32;
#[inline(always)]
fn get_block_pos(&self) -> u32 {
self.0.get_block_pos()
}
#[inline(always)]
fn set_block_pos(&mut self, pos: u32) {
self.0.set_block_pos(pos);
}
}
#[cfg(feature = "zeroize")]
#[cfg_attr(docsrs, doc(cfg(feature = "zeroize")))]
impl ZeroizeOnDrop for XChaChaCore {}
/// The HChaCha function: adapts the ChaCha core function in the same
/// manner that HSalsa adapts the Salsa function.
///
/// HChaCha takes 512-bits of input:
///
/// - Constants: `u32` x 4
/// - Key: `u32` x 8
/// - Nonce: `u32` x 4
///
/// It produces 256-bits of output suitable for use as a ChaCha key
///
/// For more information on HSalsa on which HChaCha is based, see:
///
///
pub fn hchacha(key: &Key, input: &GenericArray) -> GenericArray {
let mut state = [0u32; STATE_WORDS];
state[..4].copy_from_slice(&CONSTANTS);
let key_chunks = key.chunks_exact(4);
for (v, chunk) in state[4..12].iter_mut().zip(key_chunks) {
*v = u32::from_le_bytes(chunk.try_into().unwrap());
}
let input_chunks = input.chunks_exact(4);
for (v, chunk) in state[12..16].iter_mut().zip(input_chunks) {
*v = u32::from_le_bytes(chunk.try_into().unwrap());
}
// R rounds consisting of R/2 column rounds and R/2 diagonal rounds
for _ in 0..R::USIZE {
// column rounds
quarter_round(0, 4, 8, 12, &mut state);
quarter_round(1, 5, 9, 13, &mut state);
quarter_round(2, 6, 10, 14, &mut state);
quarter_round(3, 7, 11, 15, &mut state);
// diagonal rounds
quarter_round(0, 5, 10, 15, &mut state);
quarter_round(1, 6, 11, 12, &mut state);
quarter_round(2, 7, 8, 13, &mut state);
quarter_round(3, 4, 9, 14, &mut state);
}
let mut output = GenericArray::default();
for (chunk, val) in output[..16].chunks_exact_mut(4).zip(&state[..4]) {
chunk.copy_from_slice(&val.to_le_bytes());
}
for (chunk, val) in output[16..].chunks_exact_mut(4).zip(&state[12..]) {
chunk.copy_from_slice(&val.to_le_bytes());
}
output
}
/// The ChaCha20 quarter round function
// for simplicity this function is copied from the software backend
fn quarter_round(a: usize, b: usize, c: usize, d: usize, state: &mut [u32; STATE_WORDS]) {
state[a] = state[a].wrapping_add(state[b]);
state[d] ^= state[a];
state[d] = state[d].rotate_left(16);
state[c] = state[c].wrapping_add(state[d]);
state[b] ^= state[c];
state[b] = state[b].rotate_left(12);
state[a] = state[a].wrapping_add(state[b]);
state[d] ^= state[a];
state[d] = state[d].rotate_left(8);
state[c] = state[c].wrapping_add(state[d]);
state[b] ^= state[c];
state[b] = state[b].rotate_left(7);
}
#[cfg(test)]
mod hchacha20_tests {
use super::*;
use hex_literal::hex;
/// Test vectors from:
/// https://tools.ietf.org/id/draft-arciszewski-xchacha-03.html#rfc.section.2.2.1
#[test]
fn test_vector() {
const KEY: [u8; 32] = hex!(
"000102030405060708090a0b0c0d0e0f"
"101112131415161718191a1b1c1d1e1f"
);
const INPUT: [u8; 16] = hex!("000000090000004a0000000031415927");
const OUTPUT: [u8; 32] = hex!(
"82413b4227b27bfed30e42508a877d73"
"a0f9e4d58a74a853c12ec41326d3ecdc"
);
let actual = hchacha::(
GenericArray::from_slice(&KEY),
&GenericArray::from_slice(&INPUT),
);
assert_eq!(actual.as_slice(), &OUTPUT);
}
}
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/tests/data/chacha20-legacy.blb�������������������������������������������������������0000644�0000000�0000000�00000002025�10461020230�0016552�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000�������������������������������������������������������������������������������������������������������������������������������������������������������������������������@���������������������������������������������������������������� ����������������������������������������������v�ୠ�=�@]j�S��(���������6�̋w
��AY|QWH�w$�?��J7jC�������i��e���������������?����x���5�=�;� c�4��B�3���8�
2��L�#~�<��d&�J�T]�Iz�Fn}k����/Xk����������x������������������������������������������������������������xޜ�{�֞���c�?e:�I������O�}�7��1�Z��x��E'!Os���[Rw�.��C>D_A�@������������������������������������E@�Z�����sn{ �<��O�F��`OE R�C-A�⠶�ufҥ���
B�,Sג��?�~��u�Tic@��������
��
������������������ ������ ������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������k�������:��Ԓ�ݘ$oii���f�;�#W���l��l.e�K��-5�*�9Cpi���1�����5��N�GN�)�`����~�{Ld�٬h[��l���8������0S`6�X*��Y������-������;�q�O�$e�3j�D���]�����p�%���q������oydCqs��uV�X�z��J4�=��r��6�����N�1��? �=������TJh�u$ �k�R�Q�.2������ �XJ�V�uF̢M����%ֱ^ꃶ�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/tests/data/chacha20.blb��������������������������������������������������������������0000644�0000000�0000000�00000001454�10461020230�0015315�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������@���������������������������������������������������������������� �������������������������������������v�ୠ�=�@]j�S��(���������6�̋w
��AY|QWH�w$�?��J7jC������Ç�i��e�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������M7��67J����?���"��ߤ�r�v[T�'NJ����\��t���_����b���9S��m��(��N�T�"¡�4�U�>�9���# Hj�������^���p��w���U�����Ƃ�E@�-�����k���T�V&O���T����D��R����I�_�ț.?.
����K�e�¶��-�$�St�g����������ь�l���v�p�3���Όl��Ml�����*�m���SH��}۰_}�;�Ɩ05v�ڎv���P/f�@������������������������������������E@�Z�����sn{ �<��O�F��`OE R�C-A�⠶�ufҥ���
B�,Sג��?�~��u�Tic��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������chacha20-0.9.1/tests/mod.rs�������������������������������������������������������������������������0000644�0000000�0000000�00000020106�10461020230�0013472�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! Tests for ChaCha20 (IETF and "djb" versions) as well as XChaCha20
use chacha20::{ChaCha20, ChaCha20Legacy, XChaCha20};
// IETF version of ChaCha20 (96-bit nonce)
cipher::stream_cipher_test!(chacha20_core, "chacha20", ChaCha20);
cipher::stream_cipher_seek_test!(chacha20_seek, ChaCha20);
cipher::stream_cipher_seek_test!(xchacha20_seek, XChaCha20);
cipher::stream_cipher_seek_test!(chacha20legacy_seek, ChaCha20Legacy);
mod chacha20test {
use chacha20::{ChaCha20, Key, Nonce};
use cipher::{KeyIvInit, StreamCipher};
use hex_literal::hex;
//
// ChaCha20 test vectors from:
//
//
const KEY: [u8; 32] = hex!("000102030405060708090a0b0c0d0e0f101112131415161718191a1b1c1d1e1f");
const IV: [u8; 12] = hex!("000000000000004a00000000");
const PLAINTEXT: [u8; 114] = hex!(
"
4c616469657320616e642047656e746c
656d656e206f662074686520636c6173
73206f66202739393a20496620492063
6f756c64206f6666657220796f75206f
6e6c79206f6e652074697020666f7220
746865206675747572652c2073756e73
637265656e20776f756c642062652069
742e
"
);
const KEYSTREAM: [u8; 114] = hex!(
"
224f51f3401bd9e12fde276fb8631ded8c131f823d2c06
e27e4fcaec9ef3cf788a3b0aa372600a92b57974cded2b
9334794cba40c63e34cdea212c4cf07d41b769a6749f3f
630f4122cafe28ec4dc47e26d4346d70b98c73f3e9c53a
c40c5945398b6eda1a832c89c167eacd901d7e2bf363
"
);
const CIPHERTEXT: [u8; 114] = hex!(
"
6e2e359a2568f98041ba0728dd0d6981
e97e7aec1d4360c20a27afccfd9fae0b
f91b65c5524733ab8f593dabcd62b357
1639d624e65152ab8f530c359f0861d8
07ca0dbf500d6a6156a38e088a22b65e
52bc514d16ccf806818ce91ab7793736
5af90bbf74a35be6b40b8eedf2785e42
874d
"
);
#[test]
fn chacha20_keystream() {
let mut cipher = ChaCha20::new(&Key::from(KEY), &Nonce::from(IV));
// The test vectors omit the first 64-bytes of the keystream
let mut prefix = [0u8; 64];
cipher.apply_keystream(&mut prefix);
let mut buf = [0u8; 114];
cipher.apply_keystream(&mut buf);
assert_eq!(&buf[..], &KEYSTREAM[..]);
}
#[test]
fn chacha20_encryption() {
let mut cipher = ChaCha20::new(&Key::from(KEY), &Nonce::from(IV));
let mut buf = PLAINTEXT.clone();
// The test vectors omit the first 64-bytes of the keystream
let mut prefix = [0u8; 64];
cipher.apply_keystream(&mut prefix);
cipher.apply_keystream(&mut buf);
assert_eq!(&buf[..], &CIPHERTEXT[..]);
}
}
#[rustfmt::skip]
mod xchacha20 {
use chacha20::{Key, XChaCha20, XNonce};
use cipher::{KeyIvInit, StreamCipher};
use hex_literal::hex;
cipher::stream_cipher_seek_test!(xchacha20_seek, XChaCha20);
//
// XChaCha20 test vectors from:
//
//
const KEY: [u8; 32] = hex!("
808182838485868788898a8b8c8d8e8f909192939495969798999a9b9c9d9e9f
");
const IV: [u8; 24] = hex!("
404142434445464748494a4b4c4d4e4f5051525354555658
");
const PLAINTEXT: [u8; 304] = hex!("
5468652064686f6c65202870726f6e6f756e6365642022646f6c652229206973
20616c736f206b6e6f776e2061732074686520417369617469632077696c6420
646f672c2072656420646f672c20616e642077686973746c696e6720646f672e
2049742069732061626f7574207468652073697a65206f662061204765726d61
6e20736865706865726420627574206c6f6f6b73206d6f7265206c696b652061
206c6f6e672d6c656767656420666f782e205468697320686967686c7920656c
757369766520616e6420736b696c6c6564206a756d70657220697320636c6173
736966696564207769746820776f6c7665732c20636f796f7465732c206a6163
6b616c732c20616e6420666f78657320696e20746865207461786f6e6f6d6963
2066616d696c792043616e696461652e
");
const KEYSTREAM: [u8; 304] = hex!("
29624b4b1b140ace53740e405b2168540fd7d630c1f536fecd722fc3cddba7f4
cca98cf9e47e5e64d115450f9b125b54449ff76141ca620a1f9cfcab2a1a8a25
5e766a5266b878846120ea64ad99aa479471e63befcbd37cd1c22a221fe46221
5cf32c74895bf505863ccddd48f62916dc6521f1ec50a5ae08903aa259d9bf60
7cd8026fba548604f1b6072d91bc91243a5b845f7fd171b02edc5a0a84cf28dd
241146bc376e3f48df5e7fee1d11048c190a3d3deb0feb64b42d9c6fdeee290f
a0e6ae2c26c0249ea8c181f7e2ffd100cbe5fd3c4f8271d62b15330cb8fdcf00
b3df507ca8c924f7017b7e712d15a2eb5c50484451e54e1b4b995bd8fdd94597
bb94d7af0b2c04df10ba0890899ed9293a0f55b8bafa999264035f1d4fbe7fe0
aafa109a62372027e50e10cdfecca127
");
const CIPHERTEXT: [u8; 304] = hex!("
7d0a2e6b7f7c65a236542630294e063b7ab9b555a5d5149aa21e4ae1e4fbce87
ecc8e08a8b5e350abe622b2ffa617b202cfad72032a3037e76ffdcdc4376ee05
3a190d7e46ca1de04144850381b9cb29f051915386b8a710b8ac4d027b8b050f
7cba5854e028d564e453b8a968824173fc16488b8970cac828f11ae53cabd201
12f87107df24ee6183d2274fe4c8b1485534ef2c5fbc1ec24bfc3663efaa08bc
047d29d25043532db8391a8a3d776bf4372a6955827ccb0cdd4af403a7ce4c63
d595c75a43e045f0cce1f29c8b93bd65afc5974922f214a40b7c402cdb91ae73
c0b63615cdad0480680f16515a7ace9d39236464328a37743ffc28f4ddb324f4
d0f5bbdc270c65b1749a6efff1fbaa09536175ccd29fb9e6057b307320d31683
8a9c71f70b5b5907a66f7ea49aadc409
");
#[test]
fn xchacha20_keystream() {
let mut cipher = XChaCha20::new(&Key::from(KEY), &XNonce::from(IV));
// The test vectors omit the first 64-bytes of the keystream
let mut prefix = [0u8; 64];
cipher.apply_keystream(&mut prefix);
let mut buf = [0u8; 304];
cipher.apply_keystream(&mut buf);
assert_eq!(&buf[..], &KEYSTREAM[..]);
}
#[test]
fn xchacha20_encryption() {
let mut cipher = XChaCha20::new(&Key::from(KEY), &XNonce::from(IV));
let mut buf = PLAINTEXT.clone();
// The test vectors omit the first 64-bytes of the keystream
let mut prefix = [0u8; 64];
cipher.apply_keystream(&mut prefix);
cipher.apply_keystream(&mut buf);
assert_eq!(&buf[..], &CIPHERTEXT[..]);
}
}
// Legacy "djb" version of ChaCha20 (64-bit nonce)
#[cfg(feature = "legacy")]
#[rustfmt::skip]
mod legacy {
use chacha20::{ChaCha20Legacy, Key, LegacyNonce};
use cipher::{NewCipher, StreamCipher, StreamCipherSeek};
use hex_literal::hex;
cipher::stream_cipher_test!(chacha20_legacy_core, ChaCha20Legacy, "chacha20-legacy");
cipher::stream_cipher_seek_test!(chacha20_legacy_seek, ChaCha20Legacy);
const KEY_LONG: [u8; 32] = hex!("
0102030405060708090a0b0c0d0e0f101112131415161718191a1b1c1d1e1f20
");
const IV_LONG: [u8; 8] = hex!("0301040105090206");
const EXPECTED_LONG: [u8; 256] = hex!("
deeb6b9d06dff3e091bf3ad4f4d492b6dd98246f69691802e466e03bad235787
0f1c6c010b6c2e650c4bf58d2d35c72ab639437069a384e03100078cc1d735a0
db4e8f474ee6291460fd9197c77ed87b4c64e0d9ac685bd1c56cce021f3819cd
13f49c9a3053603602582a060e59c2fbee90ab0bf7bb102d819ced03969d3bae
71034fe598246583336aa744d8168e5dfff5c6d10270f125a4130e719717e783
c0858b6f7964437173ea1d7556c158bc7a99e74a34d93da6bf72ac9736a215ac
aefd4ec031f3f13f099e3d811d83a2cf1d544a68d2752409cc6be852b0511a2e
32f69aa0be91b30981584a1c56ce7546cca24d8cfdfca525d6b15eea83b6b686
");
#[test]
#[ignore]
fn chacha20_offsets() {
for idx in 0..256 {
for middle in idx..256 {
for last in middle..256 {
let mut cipher =
ChaCha20Legacy::new(&Key::from(KEY_LONG), &LegacyNonce::from(IV_LONG));
let mut buf = [0; 256];
cipher.seek(idx as u64);
cipher.apply_keystream(&mut buf[idx..middle]);
cipher.apply_keystream(&mut buf[middle..last]);
for k in idx..last {
assert_eq!(buf[k], EXPECTED_LONG[k])
}
}
}
}
}
}
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������