sharded-slab-0.1.4/.clog.toml�����������������������������������������������������������������������0000644�0000000�0000000�00000001632�00726746425�0014110�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������[clog]
# A repository link with the trailing '.git' which will be used to generate
# all commit and issue links
repository = "https://github.com/hawkw/sharded-slab"
# A constant release title
# subtitle = "sharded-slab"
# specify the style of commit links to generate, defaults to "github" if omitted
link-style = "github"
# The preferred way to set a constant changelog. This file will be read for old changelog
# data, then prepended to for new changelog data. It's the equivilant to setting
# both infile and outfile to the same file.
#
# Do not use with outfile or infile fields!
#
# Defaults to stdout when omitted
changelog = "CHANGELOG.md"
# This sets the output format. There are two options "json" or "markdown" and
# defaults to "markdown" when omitted
output-format = "markdown"
# If you use tags, you can set the following if you wish to only pick
# up changes since your latest tag
from-latest-tag = true
������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/.github/workflows/ci.yml���������������������������������������������������������0000644�0000000�0000000�00000004101�00726746425�0016716�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������name: CI
on: [push]
jobs:
check:
name: check
runs-on: ubuntu-latest
strategy:
matrix:
rust:
- stable
- nightly
- 1.42.0
steps:
- uses: actions/checkout@master
- name: Install toolchain
uses: actions-rs/toolchain@v1
with:
profile: minimal
toolchain: ${{ matrix.rust }}
override: true
- name: Cargo check
uses: actions-rs/cargo@v1
with:
command: check
args: --all-features
test:
name: Tests
runs-on: ubuntu-latest
needs: check
steps:
- uses: actions/checkout@master
- name: Install toolchain
uses: actions-rs/toolchain@v1
with:
profile: minimal
toolchain: nightly
override: true
- name: Run tests
run: cargo test
test-loom:
name: Loom tests
runs-on: ubuntu-latest
needs: check
steps:
- uses: actions/checkout@master
- name: Install toolchain
uses: actions-rs/toolchain@v1
with:
profile: minimal
toolchain: nightly
override: true
- name: Run Loom tests
run: ./bin/loom.sh
clippy_check:
runs-on: ubuntu-latest
needs: check
steps:
- uses: actions/checkout@v2
- name: Install toolchain
uses: actions-rs/toolchain@v1
with:
profile: minimal
toolchain: stable
components: clippy
override: true
- name: Run clippy
uses: actions-rs/clippy-check@v1
with:
token: ${{ secrets.GITHUB_TOKEN }}
args: --all-features
rustfmt:
name: rustfmt
runs-on: ubuntu-latest
needs: check
steps:
- uses: actions/checkout@v2
- name: Install toolchain
uses: actions-rs/toolchain@v1
with:
profile: minimal
toolchain: stable
components: rustfmt
override: true
- name: Run rustfmt
uses: actions-rs/cargo@v1
with:
command: fmt
args: -- --check
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/.github/workflows/release.yml����������������������������������������������������0000644�0000000�0000000�00000001067�00726746425�0017753�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������name: Release
on:
push:
tags:
- v[0-9]+.*
jobs:
create-release:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: taiki-e/create-gh-release-action@v1
with:
# Path to changelog.
changelog: CHANGELOG.md
# Reject releases from commits not contained in branches
# that match the specified pattern (regular expression)
branch: main
env:
# (Required) GitHub token for creating GitHub Releases.
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/.gitignore�����������������������������������������������������������������������0000644�0000000�0000000�00000000036�00726746425�0014176�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������target
Cargo.lock
*.nix
.envrc��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/CHANGELOG.md���������������������������������������������������������������������0000644�0000000�0000000�00000013260�00726746425�0014022�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������
### 0.1.4 (2021-10-12)
#### Features
* emit a nicer panic when thread count overflows `MAX_SHARDS` (#64) ([f1ed058a](https://github.com/hawkw/sharded-slab/commit/f1ed058a3ee296eff033fc0fb88f62a8b2f83f10))
### 0.1.3 (2021-08-02)
#### Bug Fixes
* set up MSRV in CI (#61) ([dfcc9080](https://github.com/hawkw/sharded-slab/commit/dfcc9080a62d08e359f298a9ffb0f275928b83e4), closes [#60](https://github.com/hawkw/sharded-slab/issues/60))
* **tests:** duplicate `hint` mod defs with loom ([0ce3fd91](https://github.com/hawkw/sharded-slab/commit/0ce3fd91feac8b4edb4f1ece6aebfc4ba4e50026))
### 0.1.2 (2021-08-01)
#### Bug Fixes
* make debug assertions drop safe ([26d35a69](https://github.com/hawkw/sharded-slab/commit/26d35a695c9e5d7c62ab07cc5e66a0c6f8b6eade))
#### Features
* improve panics on thread ID bit exhaustion ([9ecb8e61](https://github.com/hawkw/sharded-slab/commit/9ecb8e614f107f68b5c6ba770342ae72af1cd07b))
## 0.1.1 (2021-1-4)
#### Bug Fixes
* change `loom` to an optional dependency ([9bd442b5](https://github.com/hawkw/sharded-slab/commit/9bd442b57bc56153a67d7325144ebcf303e0fe98))
## 0.1.0 (2020-10-20)
#### Bug Fixes
* fix `remove` and `clear` returning true when the key is stale ([b52d38b2](https://github.com/hawkw/sharded-slab/commit/b52d38b2d2d3edc3a59d3dba6b75095bbd864266))
#### Breaking Changes
* **Pool:** change `Pool::create` to return a mutable guard (#48) ([778065ea](https://github.com/hawkw/sharded-slab/commit/778065ead83523e0a9d951fbd19bb37fda3cc280), closes [#41](https://github.com/hawkw/sharded-slab/issues/41), [#16](https://github.com/hawkw/sharded-slab/issues/16))
* **Slab:** rename `Guard` to `Entry` for consistency ([425ad398](https://github.com/hawkw/sharded-slab/commit/425ad39805ee818dc6b332286006bc92c8beab38))
#### Features
* add missing `Debug` impls ([71a8883f](https://github.com/hawkw/sharded-slab/commit/71a8883ff4fd861b95e81840cb5dca167657fe36))
* **Pool:**
* add `Pool::create_owned` and `OwnedRefMut` ([f7774ae0](https://github.com/hawkw/sharded-slab/commit/f7774ae0c5be99340f1e7941bde62f7044f4b4d8))
* add `Arc::get_owned` and `OwnedRef` ([3e566d91](https://github.com/hawkw/sharded-slab/commit/3e566d91e1bc8cc4630a8635ad24b321ec047fe7), closes [#29](https://github.com/hawkw/sharded-slab/issues/29))
* change `Pool::create` to return a mutable guard (#48) ([778065ea](https://github.com/hawkw/sharded-slab/commit/778065ead83523e0a9d951fbd19bb37fda3cc280), closes [#41](https://github.com/hawkw/sharded-slab/issues/41), [#16](https://github.com/hawkw/sharded-slab/issues/16))
* **Slab:**
* add `Arc::get_owned` and `OwnedEntry` ([53a970a2](https://github.com/hawkw/sharded-slab/commit/53a970a2298c30c1afd9578268c79ccd44afba05), closes [#29](https://github.com/hawkw/sharded-slab/issues/29))
* rename `Guard` to `Entry` for consistency ([425ad398](https://github.com/hawkw/sharded-slab/commit/425ad39805ee818dc6b332286006bc92c8beab38))
* add `slab`-style `VacantEntry` API ([6776590a](https://github.com/hawkw/sharded-slab/commit/6776590adeda7bf4a117fb233fc09cfa64d77ced), closes [#16](https://github.com/hawkw/sharded-slab/issues/16))
#### Performance
* allocate shard metadata lazily (#45) ([e543a06d](https://github.com/hawkw/sharded-slab/commit/e543a06d7474b3ff92df2cdb4a4571032135ff8d))
### 0.0.9 (2020-04-03)
#### Features
* **Config:** validate concurrent refs ([9b32af58](9b32af58), closes [#21](21))
* **Pool:**
* add `fmt::Debug` impl for `Pool` ([ffa5c7a0](ffa5c7a0))
* add `Default` impl for `Pool` ([d2399365](d2399365))
* add a sharded object pool for reusing heap allocations (#19) ([89734508](89734508), closes [#2](2), [#15](15))
* **Slab::take:** add exponential backoff when spinning ([6b743a27](6b743a27))
#### Bug Fixes
* incorrect wrapping when overflowing maximum ref count ([aea693f3](aea693f3), closes [#22](22))
### 0.0.8 (2020-01-31)
#### Bug Fixes
* `remove` not adding slots to free lists ([dfdd7aee](dfdd7aee))
### 0.0.7 (2019-12-06)
#### Bug Fixes
* **Config:** compensate for 0 being a valid TID ([b601f5d9](b601f5d9))
* **DefaultConfig:**
* const overflow on 32-bit ([74d42dd1](74d42dd1), closes [#10](10))
* wasted bit patterns on 64-bit ([8cf33f66](8cf33f66))
## 0.0.6 (2019-11-08)
#### Features
* **Guard:** expose `key` method #8 ([748bf39b](748bf39b))
## 0.0.5 (2019-10-31)
#### Performance
* consolidate per-slot state into one AtomicUsize (#6) ([f1146d33](f1146d33))
#### Features
* add Default impl for Slab ([61bb3316](61bb3316))
## 0.0.4 (2019-21-30)
#### Features
* prevent items from being removed while concurrently accessed ([872c81d1](872c81d1))
* added `Slab::remove` method that marks an item to be removed when the last thread
accessing it finishes ([872c81d1](872c81d1))
#### Bug Fixes
* nicer handling of races in remove ([475d9a06](475d9a06))
#### Breaking Changes
* renamed `Slab::remove` to `Slab::take` ([872c81d1](872c81d1))
* `Slab::get` now returns a `Guard` type ([872c81d1](872c81d1))
## 0.0.3 (2019-07-30)
#### Bug Fixes
* split local/remote to fix false sharing & potential races ([69f95fb0](69f95fb0))
* set next pointer _before_ head ([cc7a0bf1](cc7a0bf1))
#### Breaking Changes
* removed potentially racy `Slab::len` and `Slab::capacity` methods ([27af7d6c](27af7d6c))
## 0.0.2 (2019-03-30)
#### Bug Fixes
* fix compilation failure in release mode ([617031da](617031da))
## 0.0.1 (2019-02-30)
- Initial release
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/Cargo.toml�����������������������������������������������������������������������0000644�����������������00000002671�00000000001�0011373�0����������������������������������������������������������������������������������������������������ustar ��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������# THIS FILE IS AUTOMATICALLY GENERATED BY CARGO
#
# When uploading crates to the registry Cargo will automatically
# "normalize" Cargo.toml files for maximal compatibility
# with all versions of Cargo and also rewrite `path` dependencies
# to registry (e.g., crates.io) dependencies.
#
# If you are reading this file be aware that the original Cargo.toml
# will likely look very different (and much more reasonable).
# See Cargo.toml.orig for the original contents.
[package]
edition = "2018"
name = "sharded-slab"
version = "0.1.4"
authors = ["Eliza Weisman "]
description = "A lock-free concurrent slab.\n"
homepage = "https://github.com/hawkw/sharded-slab"
documentation = "https://docs.rs/sharded-slab/0.1.4/sharded_slab"
readme = "README.md"
keywords = ["slab", "allocator", "lock-free", "atomic"]
categories = ["memory-management", "data-structures", "concurrency"]
license = "MIT"
repository = "https://github.com/hawkw/sharded-slab"
[package.metadata.docs.rs]
all-features = true
rustdoc-args = ["--cfg", "docsrs"]
[[bench]]
name = "bench"
harness = false
[dependencies.lazy_static]
version = "1"
[dev-dependencies.criterion]
version = "0.3"
[dev-dependencies.loom]
version = "0.5"
features = ["checkpoint"]
[dev-dependencies.proptest]
version = "1"
[dev-dependencies.slab]
version = "0.4.2"
[target."cfg(loom)".dependencies.loom]
version = "0.5"
features = ["checkpoint"]
optional = true
[badges.maintenance]
status = "experimental"
�����������������������������������������������������������������������sharded-slab-0.1.4/Cargo.toml.orig������������������������������������������������������������������0000644�0000000�0000000�00000001647�00726746425�0015106�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������[package]
name = "sharded-slab"
version = "0.1.4"
authors = ["Eliza Weisman "]
edition = "2018"
documentation = "https://docs.rs/sharded-slab/0.1.4/sharded_slab"
homepage = "https://github.com/hawkw/sharded-slab"
repository = "https://github.com/hawkw/sharded-slab"
readme = "README.md"
license = "MIT"
keywords = ["slab", "allocator", "lock-free", "atomic"]
categories = ["memory-management", "data-structures", "concurrency"]
description = """
A lock-free concurrent slab.
"""
[badges]
maintenance = { status = "experimental" }
[[bench]]
name = "bench"
harness = false
[dependencies]
lazy_static = "1"
[dev-dependencies]
loom = { version = "0.5", features = ["checkpoint"] }
proptest = "1"
criterion = "0.3"
slab = "0.4.2"
[target.'cfg(loom)'.dependencies]
loom = { version = "0.5", features = ["checkpoint"], optional = true }
[package.metadata.docs.rs]
all-features = true
rustdoc-args = ["--cfg", "docsrs"]�����������������������������������������������������������������������������������������sharded-slab-0.1.4/IMPLEMENTATION.md����������������������������������������������������������������0000644�0000000�0000000�00000016672�00726746425�0014672�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Notes on `sharded-slab`'s implementation and design.
# Design
The sharded slab's design is strongly inspired by the ideas presented by
Leijen, Zorn, and de Moura in [Mimalloc: Free List Sharding in
Action][mimalloc]. In this report, the authors present a novel design for a
memory allocator based on a concept of _free list sharding_.
Memory allocators must keep track of what memory regions are not currently
allocated ("free") in order to provide them to future allocation requests.
The term [_free list_][freelist] refers to a technique for performing this
bookkeeping, where each free block stores a pointer to the next free block,
forming a linked list. The memory allocator keeps a pointer to the most
recently freed block, the _head_ of the free list. To allocate more memory,
the allocator pops from the free list by setting the head pointer to the
next free block of the current head block, and returning the previous head.
To deallocate a block, the block is pushed to the free list by setting its
first word to the current head pointer, and the head pointer is set to point
to the deallocated block. Most implementations of slab allocators backed by
arrays or vectors use a similar technique, where pointers are replaced by
indices into the backing array.
When allocations and deallocations can occur concurrently across threads,
they must synchronize accesses to the free list; either by putting the
entire allocator state inside of a lock, or by using atomic operations to
treat the free list as a lock-free structure (such as a [Treiber stack]). In
both cases, there is a significant performance cost — even when the free
list is lock-free, it is likely that a noticeable amount of time will be
spent in compare-and-swap loops. Ideally, the global synchronzation point
created by the single global free list could be avoided as much as possible.
The approach presented by Leijen, Zorn, and de Moura is to introduce
sharding and thus increase the granularity of synchronization significantly.
In mimalloc, the heap is _sharded_ so that each thread has its own
thread-local heap. Objects are always allocated from the local heap of the
thread where the allocation is performed. Because allocations are always
done from a thread's local heap, they need not be synchronized.
However, since objects can move between threads before being deallocated,
_deallocations_ may still occur concurrently. Therefore, Leijen et al.
introduce a concept of _local_ and _global_ free lists. When an object is
deallocated on the same thread it was originally allocated on, it is placed
on the local free list; if it is deallocated on another thread, it goes on
the global free list for the heap of the thread from which it originated. To
allocate, the local free list is used first; if it is empty, the entire
global free list is popped onto the local free list. Since the local free
list is only ever accessed by the thread it belongs to, it does not require
synchronization at all, and because the global free list is popped from
infrequently, the cost of synchronization has a reduced impact. A majority
of allocations can occur without any synchronization at all; and
deallocations only require synchronization when an object has left its
parent thread (a relatively uncommon case).
[mimalloc]: https://www.microsoft.com/en-us/research/uploads/prod/2019/06/mimalloc-tr-v1.pdf
[freelist]: https://en.wikipedia.org/wiki/Free_list
[Treiber stack]: https://en.wikipedia.org/wiki/Treiber_stack
# Implementation
A slab is represented as an array of [`MAX_THREADS`] _shards_. A shard
consists of a vector of one or more _pages_ plus associated metadata.
Finally, a page consists of an array of _slots_, head indices for the local
and remote free lists.
```text
┌─────────────┐
│ shard 1 │
│ │ ┌─────────────┐ ┌────────┐
│ pages───────┼───▶│ page 1 │ │ │
├─────────────┤ ├─────────────┤ ┌────▶│ next──┼─┐
│ shard 2 │ │ page 2 │ │ ├────────┤ │
├─────────────┤ │ │ │ │XXXXXXXX│ │
│ shard 3 │ │ local_head──┼──┘ ├────────┤ │
└─────────────┘ │ remote_head─┼──┐ │ │◀┘
... ├─────────────┤ │ │ next──┼─┐
┌─────────────┐ │ page 3 │ │ ├────────┤ │
│ shard n │ └─────────────┘ │ │XXXXXXXX│ │
└─────────────┘ ... │ ├────────┤ │
┌─────────────┐ │ │XXXXXXXX│ │
│ page n │ │ ├────────┤ │
└─────────────┘ │ │ │◀┘
└────▶│ next──┼───▶ ...
├────────┤
│XXXXXXXX│
└────────┘
```
The size of the first page in a shard is always a power of two, and every
subsequent page added after the first is twice as large as the page that
preceeds it.
```text
pg.
┌───┐ ┌─┬─┐
│ 0 │───▶ │ │
├───┤ ├─┼─┼─┬─┐
│ 1 │───▶ │ │ │ │
├───┤ ├─┼─┼─┼─┼─┬─┬─┬─┐
│ 2 │───▶ │ │ │ │ │ │ │ │
├───┤ ├─┼─┼─┼─┼─┼─┼─┼─┼─┬─┬─┬─┬─┬─┬─┬─┐
│ 3 │───▶ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
└───┘ └─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┘
```
When searching for a free slot, the smallest page is searched first, and if
it is full, the search proceeds to the next page until either a free slot is
found or all available pages have been searched. If all available pages have
been searched and the maximum number of pages has not yet been reached, a
new page is then allocated.
Since every page is twice as large as the previous page, and all page sizes
are powers of two, we can determine the page index that contains a given
address by shifting the address down by the smallest page size and
looking at how many twos places necessary to represent that number,
telling us what power of two page size it fits inside of. We can
determine the number of twos places by counting the number of leading
zeros (unused twos places) in the number's binary representation, and
subtracting that count from the total number of bits in a word.
The formula for determining the page number that contains an offset is thus:
```rust,ignore
WIDTH - ((offset + INITIAL_PAGE_SIZE) >> INDEX_SHIFT).leading_zeros()
```
where `WIDTH` is the number of bits in a `usize`, and `INDEX_SHIFT` is
```rust,ignore
INITIAL_PAGE_SIZE.trailing_zeros() + 1;
```
[`MAX_THREADS`]: https://docs.rs/sharded-slab/latest/sharded_slab/trait.Config.html#associatedconstant.MAX_THREADS
����������������������������������������������������������������������sharded-slab-0.1.4/LICENSE��������������������������������������������������������������������������0000644�0000000�0000000�00000002041�00726746425�0013211�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������Copyright (c) 2019 Eliza Weisman
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/README.md������������������������������������������������������������������������0000644�0000000�0000000�00000022052�00726746425�0013467�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������# sharded-slab
A lock-free concurrent slab.
[![Crates.io][crates-badge]][crates-url]
[![Documentation][docs-badge]][docs-url]
[![CI Status][ci-badge]][ci-url]
[![GitHub License][license-badge]][license]
![maintenance status][maint-badge]
[crates-badge]: https://img.shields.io/crates/v/sharded-slab.svg
[crates-url]: https://crates.io/crates/sharded-slab
[docs-badge]: https://docs.rs/sharded-slab/badge.svg
[docs-url]: https://docs.rs/sharded-slab/0.1.4/sharded_slab
[ci-badge]: https://github.com/hawkw/sharded-slab/workflows/CI/badge.svg
[ci-url]: https://github.com/hawkw/sharded-slab/actions?workflow=CI
[license-badge]: https://img.shields.io/crates/l/sharded-slab
[license]: LICENSE
[maint-badge]: https://img.shields.io/badge/maintenance-experimental-blue.svg
Slabs provide pre-allocated storage for many instances of a single data
type. When a large number of values of a single type are required,
this can be more efficient than allocating each item individually. Since the
allocated items are the same size, memory fragmentation is reduced, and
creating and removing new items can be very cheap.
This crate implements a lock-free concurrent slab, indexed by `usize`s.
**Note**: This crate is currently experimental. Please feel free to use it in
your projects, but bear in mind that there's still plenty of room for
optimization, and there may still be some lurking bugs.
## Usage
First, add this to your `Cargo.toml`:
```toml
sharded-slab = "0.1.1"
```
This crate provides two types, [`Slab`] and [`Pool`], which provide slightly
different APIs for using a sharded slab.
[`Slab`] implements a slab for _storing_ small types, sharing them between
threads, and accessing them by index. New entries are allocated by [inserting]
data, moving it in by value. Similarly, entries may be deallocated by [taking]
from the slab, moving the value out. This API is similar to a `Vec>`,
but allowing lock-free concurrent insertion and removal.
In contrast, the [`Pool`] type provides an [object pool] style API for
_reusing storage_. Rather than constructing values and moving them into
the pool, as with [`Slab`], [allocating an entry][create] from the pool
takes a closure that's provided with a mutable reference to initialize
the entry in place. When entries are deallocated, they are [cleared] in
place. Types which own a heap allocation can be cleared by dropping any
_data_ they store, but retaining any previously-allocated capacity. This
means that a [`Pool`] may be used to reuse a set of existing heap
allocations, reducing allocator load.
[`Slab`]: https://docs.rs/sharded-slab/0.1.4/sharded_slab/struct.Slab.html
[inserting]: https://docs.rs/sharded-slab/0.1.4/sharded_slab/struct.Slab.html#method.insert
[taking]: https://docs.rs/sharded-slab/0.1.4/sharded_slab/struct.Slab.html#method.take
[`Pool`]: https://docs.rs/sharded-slab/0.1.4/sharded_slab/struct.Pool.html
[create]: https://docs.rs/sharded-slab/0.1.4/sharded_slab/struct.Pool.html#method.create
[cleared]: https://docs.rs/sharded-slab/0.1.4/sharded_slab/trait.Clear.html
[object pool]: https://en.wikipedia.org/wiki/Object_pool_pattern
### Examples
Inserting an item into the slab, returning an index:
```rust
use sharded_slab::Slab;
let slab = Slab::new();
let key = slab.insert("hello world").unwrap();
assert_eq!(slab.get(key).unwrap(), "hello world");
```
To share a slab across threads, it may be wrapped in an `Arc`:
```rust
use sharded_slab::Slab;
use std::sync::Arc;
let slab = Arc::new(Slab::new());
let slab2 = slab.clone();
let thread2 = std::thread::spawn(move || {
let key = slab2.insert("hello from thread two").unwrap();
assert_eq!(slab2.get(key).unwrap(), "hello from thread two");
key
});
let key1 = slab.insert("hello from thread one").unwrap();
assert_eq!(slab.get(key1).unwrap(), "hello from thread one");
// Wait for thread 2 to complete.
let key2 = thread2.join().unwrap();
// The item inserted by thread 2 remains in the slab.
assert_eq!(slab.get(key2).unwrap(), "hello from thread two");
```
If items in the slab must be mutated, a `Mutex` or `RwLock` may be used for
each item, providing granular locking of items rather than of the slab:
```rust
use sharded_slab::Slab;
use std::sync::{Arc, Mutex};
let slab = Arc::new(Slab::new());
let key = slab.insert(Mutex::new(String::from("hello world"))).unwrap();
let slab2 = slab.clone();
let thread2 = std::thread::spawn(move || {
let hello = slab2.get(key).expect("item missing");
let mut hello = hello.lock().expect("mutex poisoned");
*hello = String::from("hello everyone!");
});
thread2.join().unwrap();
let hello = slab.get(key).expect("item missing");
let mut hello = hello.lock().expect("mutex poisoned");
assert_eq!(hello.as_str(), "hello everyone!");
```
## Comparison with Similar Crates
- [`slab`]: Carl Lerche's `slab` crate provides a slab implementation with a
similar API, implemented by storing all data in a single vector.
Unlike `sharded-slab`, inserting and removing elements from the slab requires
mutable access. This means that if the slab is accessed concurrently by
multiple threads, it is necessary for it to be protected by a `Mutex` or
`RwLock`. Items may not be inserted or removed (or accessed, if a `Mutex` is
used) concurrently, even when they are unrelated. In many cases, the lock can
become a significant bottleneck. On the other hand, `sharded-slab` allows
separate indices in the slab to be accessed, inserted, and removed
concurrently without requiring a global lock. Therefore, when the slab is
shared across multiple threads, this crate offers significantly better
performance than `slab`.
However, the lock free slab introduces some additional constant-factor
overhead. This means that in use-cases where a slab is _not_ shared by
multiple threads and locking is not required, `sharded-slab` will likely
offer slightly worse performance.
In summary: `sharded-slab` offers significantly improved performance in
concurrent use-cases, while `slab` should be preferred in single-threaded
use-cases.
[`slab`]: https://crates.io/crates/slab
## Safety and Correctness
Most implementations of lock-free data structures in Rust require some
amount of unsafe code, and this crate is not an exception. In order to catch
potential bugs in this unsafe code, we make use of [`loom`], a
permutation-testing tool for concurrent Rust programs. All `unsafe` blocks
this crate occur in accesses to `loom` `UnsafeCell`s. This means that when
those accesses occur in this crate's tests, `loom` will assert that they are
valid under the C11 memory model across multiple permutations of concurrent
executions of those tests.
In order to guard against the [ABA problem][aba], this crate makes use of
_generational indices_. Each slot in the slab tracks a generation counter
which is incremented every time a value is inserted into that slot, and the
indices returned by `Slab::insert` include the generation of the slot when
the value was inserted, packed into the high-order bits of the index. This
ensures that if a value is inserted, removed, and a new value is inserted
into the same slot in the slab, the key returned by the first call to
`insert` will not map to the new value.
Since a fixed number of bits are set aside to use for storing the generation
counter, the counter will wrap around after being incremented a number of
times. To avoid situations where a returned index lives long enough to see the
generation counter wrap around to the same value, it is good to be fairly
generous when configuring the allocation of index bits.
[`loom`]: https://crates.io/crates/loom
[aba]: https://en.wikipedia.org/wiki/ABA_problem
## Performance
These graphs were produced by [benchmarks] of the sharded slab implementation,
using the [`criterion`] crate.
The first shows the results of a benchmark where an increasing number of
items are inserted and then removed into a slab concurrently by five
threads. It compares the performance of the sharded slab implementation
with a `RwLock`:
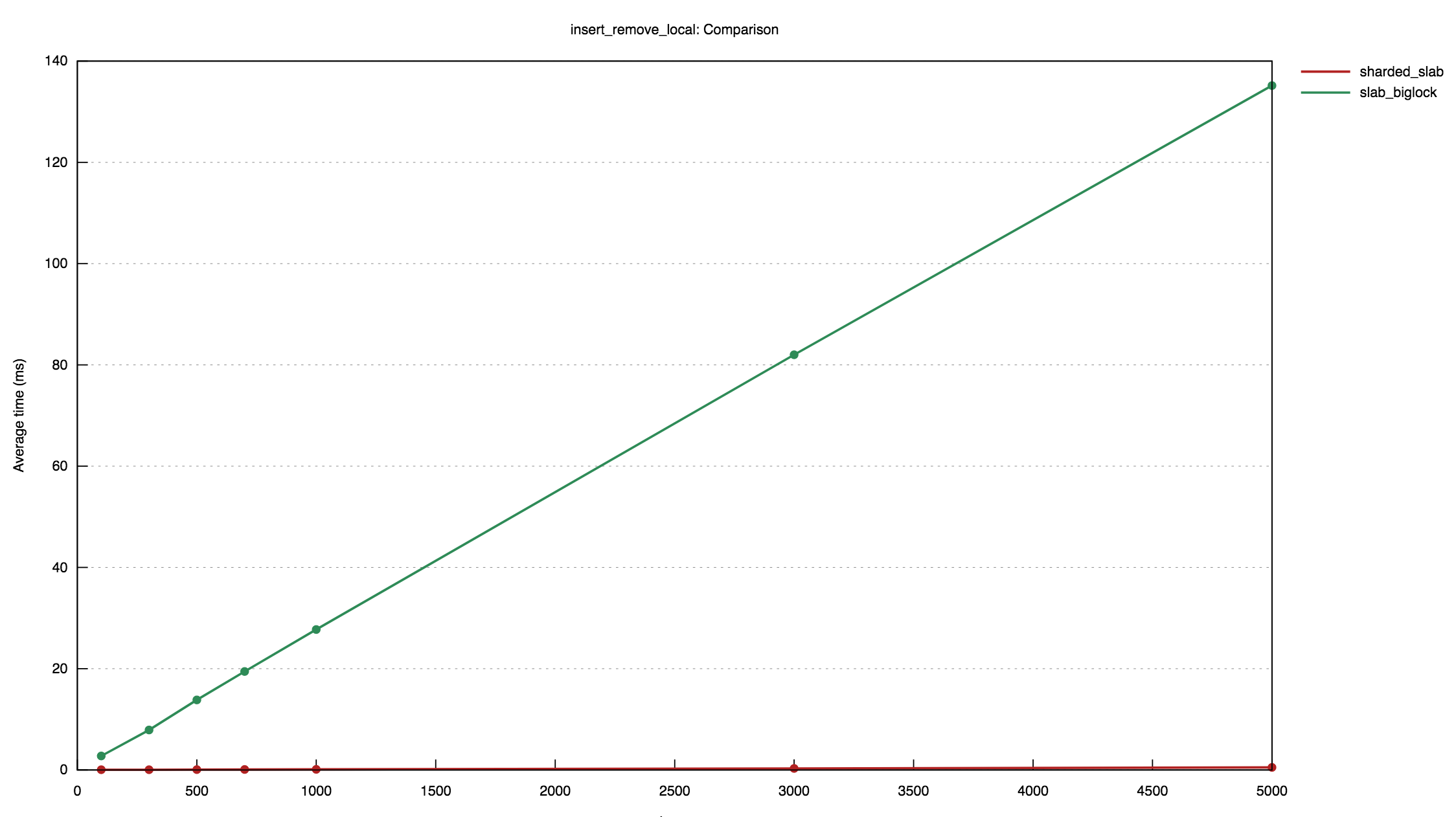 The second graph shows the results of a benchmark where an increasing
number of items are inserted and then removed by a _single_ thread. It
compares the performance of the sharded slab implementation with an
`RwLock` and a `mut slab::Slab`.
The second graph shows the results of a benchmark where an increasing
number of items are inserted and then removed by a _single_ thread. It
compares the performance of the sharded slab implementation with an
`RwLock` and a `mut slab::Slab`.
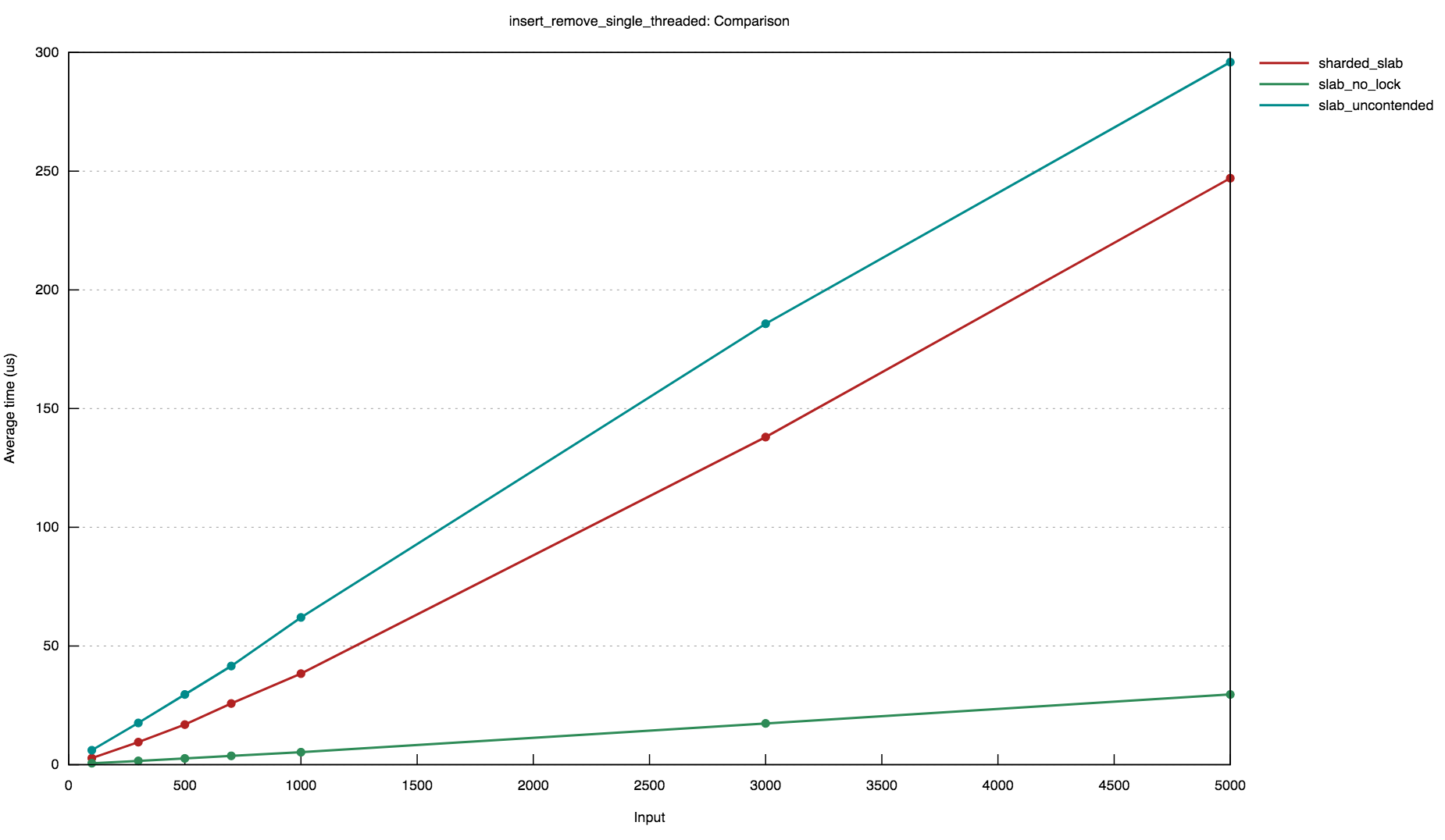 These benchmarks demonstrate that, while the sharded approach introduces
a small constant-factor overhead, it offers significantly better
performance across concurrent accesses.
[benchmarks]: https://github.com/hawkw/sharded-slab/blob/master/benches/bench.rs
[`criterion`]: https://crates.io/crates/criterion
## License
This project is licensed under the [MIT license](LICENSE).
### Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted
for inclusion in this project by you, shall be licensed as MIT, without any
additional terms or conditions.
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/benches/bench.rs�����������������������������������������������������������������0000644�0000000�0000000�00000015456�00726746425�0015256�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use criterion::{criterion_group, criterion_main, BenchmarkId, Criterion};
use std::{
sync::{Arc, Barrier, RwLock},
thread,
time::{Duration, Instant},
};
#[derive(Clone)]
struct MultithreadedBench {
start: Arc,
end: Arc,
slab: Arc,
}
impl MultithreadedBench {
fn new(slab: Arc) -> Self {
Self {
start: Arc::new(Barrier::new(5)),
end: Arc::new(Barrier::new(5)),
slab,
}
}
fn thread(&self, f: impl FnOnce(&Barrier, &T) + Send + 'static) -> &Self {
let start = self.start.clone();
let end = self.end.clone();
let slab = self.slab.clone();
thread::spawn(move || {
f(&*start, &*slab);
end.wait();
});
self
}
fn run(&self) -> Duration {
self.start.wait();
let t0 = Instant::now();
self.end.wait();
t0.elapsed()
}
}
const N_INSERTIONS: &[usize] = &[100, 300, 500, 700, 1000, 3000, 5000];
fn insert_remove_local(c: &mut Criterion) {
// the 10000-insertion benchmark takes the `slab` crate about an hour to
// run; don't run this unless you're prepared for that...
// const N_INSERTIONS: &'static [usize] = &[100, 500, 1000, 5000, 10000];
let mut group = c.benchmark_group("insert_remove_local");
let g = group.measurement_time(Duration::from_secs(15));
for i in N_INSERTIONS {
g.bench_with_input(BenchmarkId::new("sharded_slab", i), i, |b, &i| {
b.iter_custom(|iters| {
let mut total = Duration::from_secs(0);
for _ in 0..iters {
let bench = MultithreadedBench::new(Arc::new(sharded_slab::Slab::new()));
let elapsed = bench
.thread(move |start, slab| {
start.wait();
let v: Vec<_> = (0..i).map(|i| slab.insert(i).unwrap()).collect();
for i in v {
slab.remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> = (0..i).map(|i| slab.insert(i).unwrap()).collect();
for i in v {
slab.remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> = (0..i).map(|i| slab.insert(i).unwrap()).collect();
for i in v {
slab.remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> = (0..i).map(|i| slab.insert(i).unwrap()).collect();
for i in v {
slab.remove(i);
}
})
.run();
total += elapsed;
}
total
})
});
g.bench_with_input(BenchmarkId::new("slab_biglock", i), i, |b, &i| {
b.iter_custom(|iters| {
let mut total = Duration::from_secs(0);
let i = i;
for _ in 0..iters {
let bench = MultithreadedBench::new(Arc::new(RwLock::new(slab::Slab::new())));
let elapsed = bench
.thread(move |start, slab| {
start.wait();
let v: Vec<_> =
(0..i).map(|i| slab.write().unwrap().insert(i)).collect();
for i in v {
slab.write().unwrap().remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> =
(0..i).map(|i| slab.write().unwrap().insert(i)).collect();
for i in v {
slab.write().unwrap().remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> =
(0..i).map(|i| slab.write().unwrap().insert(i)).collect();
for i in v {
slab.write().unwrap().remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> =
(0..i).map(|i| slab.write().unwrap().insert(i)).collect();
for i in v {
slab.write().unwrap().remove(i);
}
})
.run();
total += elapsed;
}
total
})
});
}
group.finish();
}
fn insert_remove_single_thread(c: &mut Criterion) {
// the 10000-insertion benchmark takes the `slab` crate about an hour to
// run; don't run this unless you're prepared for that...
// const N_INSERTIONS: &'static [usize] = &[100, 500, 1000, 5000, 10000];
let mut group = c.benchmark_group("insert_remove_single_threaded");
for i in N_INSERTIONS {
group.bench_with_input(BenchmarkId::new("sharded_slab", i), i, |b, &i| {
let slab = sharded_slab::Slab::new();
b.iter(|| {
let v: Vec<_> = (0..i).map(|i| slab.insert(i).unwrap()).collect();
for i in v {
slab.remove(i);
}
});
});
group.bench_with_input(BenchmarkId::new("slab_no_lock", i), i, |b, &i| {
let mut slab = slab::Slab::new();
b.iter(|| {
let v: Vec<_> = (0..i).map(|i| slab.insert(i)).collect();
for i in v {
slab.remove(i);
}
});
});
group.bench_with_input(BenchmarkId::new("slab_uncontended", i), i, |b, &i| {
let slab = RwLock::new(slab::Slab::new());
b.iter(|| {
let v: Vec<_> = (0..i).map(|i| slab.write().unwrap().insert(i)).collect();
for i in v {
slab.write().unwrap().remove(i);
}
});
});
}
group.finish();
}
criterion_group!(benches, insert_remove_local, insert_remove_single_thread);
criterion_main!(benches);
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/bin/loom.sh����������������������������������������������������������������������0000755�0000000�0000000�00000001011�00726746425�0014255�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env bash
# Runs Loom tests with defaults for Loom's configuration values.
#
# The tests are compiled in release mode to improve performance, but debug
# assertions are enabled.
#
# Any arguments to this script are passed to the `cargo test` invocation.
RUSTFLAGS="${RUSTFLAGS} --cfg loom -C debug-assertions=on" \
LOOM_MAX_PREEMPTIONS="${LOOM_MAX_PREEMPTIONS:-2}" \
LOOM_CHECKPOINT_INTERVAL="${LOOM_CHECKPOINT_INTERVAL:-1}" \
LOOM_LOG=1 \
LOOM_LOCATION=1 \
cargo test --release --lib "$@"
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/cfg.rs�����������������������������������������������������������������������0000644�0000000�0000000�00000015341�00726746425�0014107�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use crate::page::{
slot::{Generation, RefCount},
Addr,
};
use crate::Pack;
use std::{fmt, marker::PhantomData};
/// Configuration parameters which can be overridden to tune the behavior of a slab.
pub trait Config: Sized {
/// The maximum number of threads which can access the slab.
///
/// This value (rounded to a power of two) determines the number of shards
/// in the slab. If a thread is created, accesses the slab, and then terminates,
/// its shard may be reused and thus does not count against the maximum
/// number of threads once the thread has terminated.
const MAX_THREADS: usize = DefaultConfig::MAX_THREADS;
/// The maximum number of pages in each shard in the slab.
///
/// This value, in combination with `INITIAL_PAGE_SIZE`, determines how many
/// bits of each index are used to represent page addresses.
const MAX_PAGES: usize = DefaultConfig::MAX_PAGES;
/// The size of the first page in each shard.
///
/// When a page in a shard has been filled with values, a new page
/// will be allocated that is twice as large as the previous page. Thus, the
/// second page will be twice this size, and the third will be four times
/// this size, and so on.
///
/// Note that page sizes must be powers of two. If this value is not a power
/// of two, it will be rounded to the next power of two.
const INITIAL_PAGE_SIZE: usize = DefaultConfig::INITIAL_PAGE_SIZE;
/// Sets a number of high-order bits in each index which are reserved from
/// user code.
///
/// Note that these bits are taken from the generation counter; if the page
/// address and thread IDs are configured to use a large number of bits,
/// reserving additional bits will decrease the period of the generation
/// counter. These should thus be used relatively sparingly, to ensure that
/// generation counters are able to effectively prevent the ABA problem.
const RESERVED_BITS: usize = 0;
}
pub(crate) trait CfgPrivate: Config {
const USED_BITS: usize = Generation::::LEN + Generation::::SHIFT;
const INITIAL_SZ: usize = next_pow2(Self::INITIAL_PAGE_SIZE);
const MAX_SHARDS: usize = next_pow2(Self::MAX_THREADS - 1);
const ADDR_INDEX_SHIFT: usize = Self::INITIAL_SZ.trailing_zeros() as usize + 1;
fn page_size(n: usize) -> usize {
Self::INITIAL_SZ * 2usize.pow(n as _)
}
fn debug() -> DebugConfig {
DebugConfig { _cfg: PhantomData }
}
fn validate() {
assert!(
Self::INITIAL_SZ.is_power_of_two(),
"invalid Config: {:#?}",
Self::debug(),
);
assert!(
Self::INITIAL_SZ <= Addr::::BITS,
"invalid Config: {:#?}",
Self::debug()
);
assert!(
Generation::::BITS >= 3,
"invalid Config: {:#?}\ngeneration counter should be at least 3 bits!",
Self::debug()
);
assert!(
Self::USED_BITS <= WIDTH,
"invalid Config: {:#?}\ntotal number of bits per index is too large to fit in a word!",
Self::debug()
);
assert!(
WIDTH - Self::USED_BITS >= Self::RESERVED_BITS,
"invalid Config: {:#?}\nindices are too large to fit reserved bits!",
Self::debug()
);
assert!(
RefCount::::MAX > 1,
"invalid config: {:#?}\n maximum concurrent references would be {}",
Self::debug(),
RefCount::::MAX,
);
}
#[inline(always)]
fn unpack>(packed: usize) -> A {
A::from_packed(packed)
}
#[inline(always)]
fn unpack_addr(packed: usize) -> Addr {
Self::unpack(packed)
}
#[inline(always)]
fn unpack_tid(packed: usize) -> crate::Tid {
Self::unpack(packed)
}
#[inline(always)]
fn unpack_gen(packed: usize) -> Generation {
Self::unpack(packed)
}
}
impl CfgPrivate for C {}
/// Default slab configuration values.
#[derive(Copy, Clone)]
pub struct DefaultConfig {
_p: (),
}
pub(crate) struct DebugConfig {
_cfg: PhantomData,
}
pub(crate) const WIDTH: usize = std::mem::size_of::() * 8;
pub(crate) const fn next_pow2(n: usize) -> usize {
let pow2 = n.count_ones() == 1;
let zeros = n.leading_zeros();
1 << (WIDTH - zeros as usize - pow2 as usize)
}
// === impl DefaultConfig ===
impl Config for DefaultConfig {
const INITIAL_PAGE_SIZE: usize = 32;
#[cfg(target_pointer_width = "64")]
const MAX_THREADS: usize = 4096;
#[cfg(target_pointer_width = "32")]
// TODO(eliza): can we find enough bits to give 32-bit platforms more threads?
const MAX_THREADS: usize = 128;
const MAX_PAGES: usize = WIDTH / 2;
}
impl fmt::Debug for DefaultConfig {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
Self::debug().fmt(f)
}
}
impl fmt::Debug for DebugConfig {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.debug_struct(std::any::type_name::())
.field("initial_page_size", &C::INITIAL_SZ)
.field("max_shards", &C::MAX_SHARDS)
.field("max_pages", &C::MAX_PAGES)
.field("used_bits", &C::USED_BITS)
.field("reserved_bits", &C::RESERVED_BITS)
.field("pointer_width", &WIDTH)
.field("max_concurrent_references", &RefCount::::MAX)
.finish()
}
}
#[cfg(test)]
mod tests {
use super::*;
use crate::test_util;
use crate::Slab;
#[test]
#[cfg_attr(loom, ignore)]
#[should_panic]
fn validates_max_refs() {
struct GiantGenConfig;
// Configure the slab with a very large number of bits for the generation
// counter. This will only leave 1 bit to use for the slot reference
// counter, which will fail to validate.
impl Config for GiantGenConfig {
const INITIAL_PAGE_SIZE: usize = 1;
const MAX_THREADS: usize = 1;
const MAX_PAGES: usize = 1;
}
let _slab = Slab::::new_with_config::();
}
#[test]
#[cfg_attr(loom, ignore)]
fn big() {
let slab = Slab::new();
for i in 0..10000 {
println!("{:?}", i);
let k = slab.insert(i).expect("insert");
assert_eq!(slab.get(k).expect("get"), i);
}
}
#[test]
#[cfg_attr(loom, ignore)]
fn custom_page_sz() {
let slab = Slab::new_with_config::();
for i in 0..4096 {
println!("{}", i);
let k = slab.insert(i).expect("insert");
assert_eq!(slab.get(k).expect("get"), i);
}
}
}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/clear.rs���������������������������������������������������������������������0000644�0000000�0000000�00000005231�00726746425�0014433�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use std::{collections, hash, ops::DerefMut, sync};
/// Trait implemented by types which can be cleared in place, retaining any
/// allocated memory.
///
/// This is essentially a generalization of methods on standard library
/// collection types, including as [`Vec::clear`], [`String::clear`], and
/// [`HashMap::clear`]. These methods drop all data stored in the collection,
/// but retain the collection's heap allocation for future use. Types such as
/// `BTreeMap`, whose `clear` methods drops allocations, should not
/// implement this trait.
///
/// When implemented for types which do not own a heap allocation, `Clear`
/// should reset the type in place if possible. If the type has an empty state
/// or stores `Option`s, those values should be reset to the empty state. For
/// "plain old data" types, which hold no pointers to other data and do not have
/// an empty or initial state, it's okay for a `Clear` implementation to be a
/// no-op. In that case, it essentially serves as a marker indicating that the
/// type may be reused to store new data.
///
/// [`Vec::clear`]: https://doc.rust-lang.org/stable/std/vec/struct.Vec.html#method.clear
/// [`String::clear`]: https://doc.rust-lang.org/stable/std/string/struct.String.html#method.clear
/// [`HashMap::clear`]: https://doc.rust-lang.org/stable/std/collections/struct.HashMap.html#method.clear
pub trait Clear {
/// Clear all data in `self`, retaining the allocated capacithy.
fn clear(&mut self);
}
impl Clear for Option {
fn clear(&mut self) {
let _ = self.take();
}
}
impl Clear for Box
where
T: Clear,
{
#[inline]
fn clear(&mut self) {
self.deref_mut().clear()
}
}
impl Clear for Vec {
#[inline]
fn clear(&mut self) {
Vec::clear(self)
}
}
impl Clear for collections::HashMap
where
K: hash::Hash + Eq,
S: hash::BuildHasher,
{
#[inline]
fn clear(&mut self) {
collections::HashMap::clear(self)
}
}
impl Clear for collections::HashSet
where
T: hash::Hash + Eq,
S: hash::BuildHasher,
{
#[inline]
fn clear(&mut self) {
collections::HashSet::clear(self)
}
}
impl Clear for String {
#[inline]
fn clear(&mut self) {
String::clear(self)
}
}
impl Clear for sync::Mutex {
#[inline]
fn clear(&mut self) {
self.get_mut().unwrap().clear();
}
}
impl Clear for sync::RwLock {
#[inline]
fn clear(&mut self) {
self.write().unwrap().clear();
}
}
#[cfg(all(loom, test))]
impl Clear for crate::sync::alloc::Track {
fn clear(&mut self) {
self.get_mut().clear()
}
}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/implementation.rs������������������������������������������������������������0000644�0000000�0000000�00000020041�00726746425�0016366�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������// This module exists only to provide a separate page for the implementation
// documentation.
//! Notes on `sharded-slab`'s implementation and design.
//!
//! # Design
//!
//! The sharded slab's design is strongly inspired by the ideas presented by
//! Leijen, Zorn, and de Moura in [Mimalloc: Free List Sharding in
//! Action][mimalloc]. In this report, the authors present a novel design for a
//! memory allocator based on a concept of _free list sharding_.
//!
//! Memory allocators must keep track of what memory regions are not currently
//! allocated ("free") in order to provide them to future allocation requests.
//! The term [_free list_][freelist] refers to a technique for performing this
//! bookkeeping, where each free block stores a pointer to the next free block,
//! forming a linked list. The memory allocator keeps a pointer to the most
//! recently freed block, the _head_ of the free list. To allocate more memory,
//! the allocator pops from the free list by setting the head pointer to the
//! next free block of the current head block, and returning the previous head.
//! To deallocate a block, the block is pushed to the free list by setting its
//! first word to the current head pointer, and the head pointer is set to point
//! to the deallocated block. Most implementations of slab allocators backed by
//! arrays or vectors use a similar technique, where pointers are replaced by
//! indices into the backing array.
//!
//! When allocations and deallocations can occur concurrently across threads,
//! they must synchronize accesses to the free list; either by putting the
//! entire allocator state inside of a lock, or by using atomic operations to
//! treat the free list as a lock-free structure (such as a [Treiber stack]). In
//! both cases, there is a significant performance cost — even when the free
//! list is lock-free, it is likely that a noticeable amount of time will be
//! spent in compare-and-swap loops. Ideally, the global synchronzation point
//! created by the single global free list could be avoided as much as possible.
//!
//! The approach presented by Leijen, Zorn, and de Moura is to introduce
//! sharding and thus increase the granularity of synchronization significantly.
//! In mimalloc, the heap is _sharded_ so that each thread has its own
//! thread-local heap. Objects are always allocated from the local heap of the
//! thread where the allocation is performed. Because allocations are always
//! done from a thread's local heap, they need not be synchronized.
//!
//! However, since objects can move between threads before being deallocated,
//! _deallocations_ may still occur concurrently. Therefore, Leijen et al.
//! introduce a concept of _local_ and _global_ free lists. When an object is
//! deallocated on the same thread it was originally allocated on, it is placed
//! on the local free list; if it is deallocated on another thread, it goes on
//! the global free list for the heap of the thread from which it originated. To
//! allocate, the local free list is used first; if it is empty, the entire
//! global free list is popped onto the local free list. Since the local free
//! list is only ever accessed by the thread it belongs to, it does not require
//! synchronization at all, and because the global free list is popped from
//! infrequently, the cost of synchronization has a reduced impact. A majority
//! of allocations can occur without any synchronization at all; and
//! deallocations only require synchronization when an object has left its
//! parent thread (a relatively uncommon case).
//!
//! [mimalloc]: https://www.microsoft.com/en-us/research/uploads/prod/2019/06/mimalloc-tr-v1.pdf
//! [freelist]: https://en.wikipedia.org/wiki/Free_list
//! [Treiber stack]: https://en.wikipedia.org/wiki/Treiber_stack
//!
//! # Implementation
//!
//! A slab is represented as an array of [`MAX_THREADS`] _shards_. A shard
//! consists of a vector of one or more _pages_ plus associated metadata.
//! Finally, a page consists of an array of _slots_, head indices for the local
//! and remote free lists.
//!
//! ```text
//! ┌─────────────┐
//! │ shard 1 │
//! │ │ ┌─────────────┐ ┌────────┐
//! │ pages───────┼───▶│ page 1 │ │ │
//! ├─────────────┤ ├─────────────┤ ┌────▶│ next──┼─┐
//! │ shard 2 │ │ page 2 │ │ ├────────┤ │
//! ├─────────────┤ │ │ │ │XXXXXXXX│ │
//! │ shard 3 │ │ local_head──┼──┘ ├────────┤ │
//! └─────────────┘ │ remote_head─┼──┐ │ │◀┘
//! ... ├─────────────┤ │ │ next──┼─┐
//! ┌─────────────┐ │ page 3 │ │ ├────────┤ │
//! │ shard n │ └─────────────┘ │ │XXXXXXXX│ │
//! └─────────────┘ ... │ ├────────┤ │
//! ┌─────────────┐ │ │XXXXXXXX│ │
//! │ page n │ │ ├────────┤ │
//! └─────────────┘ │ │ │◀┘
//! └────▶│ next──┼───▶ ...
//! ├────────┤
//! │XXXXXXXX│
//! └────────┘
//! ```
//!
//!
//! The size of the first page in a shard is always a power of two, and every
//! subsequent page added after the first is twice as large as the page that
//! preceeds it.
//!
//! ```text
//!
//! pg.
//! ┌───┐ ┌─┬─┐
//! │ 0 │───▶ │ │
//! ├───┤ ├─┼─┼─┬─┐
//! │ 1 │───▶ │ │ │ │
//! ├───┤ ├─┼─┼─┼─┼─┬─┬─┬─┐
//! │ 2 │───▶ │ │ │ │ │ │ │ │
//! ├───┤ ├─┼─┼─┼─┼─┼─┼─┼─┼─┬─┬─┬─┬─┬─┬─┬─┐
//! │ 3 │───▶ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
//! └───┘ └─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┘
//! ```
//!
//! When searching for a free slot, the smallest page is searched first, and if
//! it is full, the search proceeds to the next page until either a free slot is
//! found or all available pages have been searched. If all available pages have
//! been searched and the maximum number of pages has not yet been reached, a
//! new page is then allocated.
//!
//! Since every page is twice as large as the previous page, and all page sizes
//! are powers of two, we can determine the page index that contains a given
//! address by shifting the address down by the smallest page size and
//! looking at how many twos places necessary to represent that number,
//! telling us what power of two page size it fits inside of. We can
//! determine the number of twos places by counting the number of leading
//! zeros (unused twos places) in the number's binary representation, and
//! subtracting that count from the total number of bits in a word.
//!
//! The formula for determining the page number that contains an offset is thus:
//!
//! ```rust,ignore
//! WIDTH - ((offset + INITIAL_PAGE_SIZE) >> INDEX_SHIFT).leading_zeros()
//! ```
//!
//! where `WIDTH` is the number of bits in a `usize`, and `INDEX_SHIFT` is
//!
//! ```rust,ignore
//! INITIAL_PAGE_SIZE.trailing_zeros() + 1;
//! ```
//!
//! [`MAX_THREADS`]: https://docs.rs/sharded-slab/latest/sharded_slab/trait.Config.html#associatedconstant.MAX_THREADS
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/iter.rs����������������������������������������������������������������������0000644�0000000�0000000�00000002417�00726746425�0014313�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use crate::{page, shard};
use std::slice;
#[derive(Debug)]
pub struct UniqueIter<'a, T, C: crate::cfg::Config> {
pub(super) shards: shard::IterMut<'a, Option, C>,
pub(super) pages: slice::Iter<'a, page::Shared, C>>,
pub(super) slots: Option>,
}
impl<'a, T, C: crate::cfg::Config> Iterator for UniqueIter<'a, T, C> {
type Item = &'a T;
fn next(&mut self) -> Option {
test_println!("UniqueIter::next");
loop {
test_println!("-> try next slot");
if let Some(item) = self.slots.as_mut().and_then(|slots| slots.next()) {
test_println!("-> found an item!");
return Some(item);
}
test_println!("-> try next page");
if let Some(page) = self.pages.next() {
test_println!("-> found another page");
self.slots = page.iter();
continue;
}
test_println!("-> try next shard");
if let Some(shard) = self.shards.next() {
test_println!("-> found another shard");
self.pages = shard.iter();
} else {
test_println!("-> all done!");
return None;
}
}
}
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/lib.rs�����������������������������������������������������������������������0000644�0000000�0000000�00000106601�00726746425�0014116�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! A lock-free concurrent slab.
//!
//! Slabs provide pre-allocated storage for many instances of a single data
//! type. When a large number of values of a single type are required,
//! this can be more efficient than allocating each item individually. Since the
//! allocated items are the same size, memory fragmentation is reduced, and
//! creating and removing new items can be very cheap.
//!
//! This crate implements a lock-free concurrent slab, indexed by `usize`s.
//!
//! ## Usage
//!
//! First, add this to your `Cargo.toml`:
//!
//! ```toml
//! sharded-slab = "0.1.1"
//! ```
//!
//! This crate provides two types, [`Slab`] and [`Pool`], which provide
//! slightly different APIs for using a sharded slab.
//!
//! [`Slab`] implements a slab for _storing_ small types, sharing them between
//! threads, and accessing them by index. New entries are allocated by
//! [inserting] data, moving it in by value. Similarly, entries may be
//! deallocated by [taking] from the slab, moving the value out. This API is
//! similar to a `Vec>`, but allowing lock-free concurrent insertion
//! and removal.
//!
//! In contrast, the [`Pool`] type provides an [object pool] style API for
//! _reusing storage_. Rather than constructing values and moving them into the
//! pool, as with [`Slab`], [allocating an entry][create] from the pool takes a
//! closure that's provided with a mutable reference to initialize the entry in
//! place. When entries are deallocated, they are [cleared] in place. Types
//! which own a heap allocation can be cleared by dropping any _data_ they
//! store, but retaining any previously-allocated capacity. This means that a
//! [`Pool`] may be used to reuse a set of existing heap allocations, reducing
//! allocator load.
//!
//! [inserting]: Slab::insert
//! [taking]: Slab::take
//! [create]: Pool::create
//! [cleared]: Clear
//! [object pool]: https://en.wikipedia.org/wiki/Object_pool_pattern
//!
//! # Examples
//!
//! Inserting an item into the slab, returning an index:
//! ```rust
//! # use sharded_slab::Slab;
//! let slab = Slab::new();
//!
//! let key = slab.insert("hello world").unwrap();
//! assert_eq!(slab.get(key).unwrap(), "hello world");
//! ```
//!
//! To share a slab across threads, it may be wrapped in an `Arc`:
//! ```rust
//! # use sharded_slab::Slab;
//! use std::sync::Arc;
//! let slab = Arc::new(Slab::new());
//!
//! let slab2 = slab.clone();
//! let thread2 = std::thread::spawn(move || {
//! let key = slab2.insert("hello from thread two").unwrap();
//! assert_eq!(slab2.get(key).unwrap(), "hello from thread two");
//! key
//! });
//!
//! let key1 = slab.insert("hello from thread one").unwrap();
//! assert_eq!(slab.get(key1).unwrap(), "hello from thread one");
//!
//! // Wait for thread 2 to complete.
//! let key2 = thread2.join().unwrap();
//!
//! // The item inserted by thread 2 remains in the slab.
//! assert_eq!(slab.get(key2).unwrap(), "hello from thread two");
//!```
//!
//! If items in the slab must be mutated, a `Mutex` or `RwLock` may be used for
//! each item, providing granular locking of items rather than of the slab:
//!
//! ```rust
//! # use sharded_slab::Slab;
//! use std::sync::{Arc, Mutex};
//! let slab = Arc::new(Slab::new());
//!
//! let key = slab.insert(Mutex::new(String::from("hello world"))).unwrap();
//!
//! let slab2 = slab.clone();
//! let thread2 = std::thread::spawn(move || {
//! let hello = slab2.get(key).expect("item missing");
//! let mut hello = hello.lock().expect("mutex poisoned");
//! *hello = String::from("hello everyone!");
//! });
//!
//! thread2.join().unwrap();
//!
//! let hello = slab.get(key).expect("item missing");
//! let mut hello = hello.lock().expect("mutex poisoned");
//! assert_eq!(hello.as_str(), "hello everyone!");
//! ```
//!
//! # Configuration
//!
//! For performance reasons, several values used by the slab are calculated as
//! constants. In order to allow users to tune the slab's parameters, we provide
//! a [`Config`] trait which defines these parameters as associated `consts`.
//! The `Slab` type is generic over a `C: Config` parameter.
//!
//! [`Config`]: trait.Config.html
//!
//! # Comparison with Similar Crates
//!
//! - [`slab`]: Carl Lerche's `slab` crate provides a slab implementation with a
//! similar API, implemented by storing all data in a single vector.
//!
//! Unlike `sharded_slab`, inserting and removing elements from the slab
//! requires mutable access. This means that if the slab is accessed
//! concurrently by multiple threads, it is necessary for it to be protected
//! by a `Mutex` or `RwLock`. Items may not be inserted or removed (or
//! accessed, if a `Mutex` is used) concurrently, even when they are
//! unrelated. In many cases, the lock can become a significant bottleneck. On
//! the other hand, this crate allows separate indices in the slab to be
//! accessed, inserted, and removed concurrently without requiring a global
//! lock. Therefore, when the slab is shared across multiple threads, this
//! crate offers significantly better performance than `slab`.
//!
//! However, the lock free slab introduces some additional constant-factor
//! overhead. This means that in use-cases where a slab is _not_ shared by
//! multiple threads and locking is not required, this crate will likely offer
//! slightly worse performance.
//!
//! In summary: `sharded-slab` offers significantly improved performance in
//! concurrent use-cases, while `slab` should be preferred in single-threaded
//! use-cases.
//!
//! [`slab`]: https://crates.io/crates/loom
//!
//! # Safety and Correctness
//!
//! Most implementations of lock-free data structures in Rust require some
//! amount of unsafe code, and this crate is not an exception. In order to catch
//! potential bugs in this unsafe code, we make use of [`loom`], a
//! permutation-testing tool for concurrent Rust programs. All `unsafe` blocks
//! this crate occur in accesses to `loom` `UnsafeCell`s. This means that when
//! those accesses occur in this crate's tests, `loom` will assert that they are
//! valid under the C11 memory model across multiple permutations of concurrent
//! executions of those tests.
//!
//! In order to guard against the [ABA problem][aba], this crate makes use of
//! _generational indices_. Each slot in the slab tracks a generation counter
//! which is incremented every time a value is inserted into that slot, and the
//! indices returned by [`Slab::insert`] include the generation of the slot when
//! the value was inserted, packed into the high-order bits of the index. This
//! ensures that if a value is inserted, removed, and a new value is inserted
//! into the same slot in the slab, the key returned by the first call to
//! `insert` will not map to the new value.
//!
//! Since a fixed number of bits are set aside to use for storing the generation
//! counter, the counter will wrap around after being incremented a number of
//! times. To avoid situations where a returned index lives long enough to see the
//! generation counter wrap around to the same value, it is good to be fairly
//! generous when configuring the allocation of index bits.
//!
//! [`loom`]: https://crates.io/crates/loom
//! [aba]: https://en.wikipedia.org/wiki/ABA_problem
//! [`Slab::insert`]: struct.Slab.html#method.insert
//!
//! # Performance
//!
//! These graphs were produced by [benchmarks] of the sharded slab implementation,
//! using the [`criterion`] crate.
//!
//! The first shows the results of a benchmark where an increasing number of
//! items are inserted and then removed into a slab concurrently by five
//! threads. It compares the performance of the sharded slab implementation
//! with a `RwLock`:
//!
//!
//!
//! The second graph shows the results of a benchmark where an increasing
//! number of items are inserted and then removed by a _single_ thread. It
//! compares the performance of the sharded slab implementation with an
//! `RwLock` and a `mut slab::Slab`.
//!
//!
//!
//! These benchmarks demonstrate that, while the sharded approach introduces
//! a small constant-factor overhead, it offers significantly better
//! performance across concurrent accesses.
//!
//! [benchmarks]: https://github.com/hawkw/sharded-slab/blob/master/benches/bench.rs
//! [`criterion`]: https://crates.io/crates/criterion
//!
//! # Implementation Notes
//!
//! See [this page](crate::implementation) for details on this crate's design
//! and implementation.
//!
#![doc(html_root_url = "https://docs.rs/sharded-slab/0.1.4")]
#![warn(missing_debug_implementations, missing_docs)]
#![cfg_attr(docsrs, warn(rustdoc::broken_intra_doc_links))]
#[macro_use]
mod macros;
pub mod implementation;
pub mod pool;
pub(crate) mod cfg;
pub(crate) mod sync;
mod clear;
mod iter;
mod page;
mod shard;
mod tid;
pub use cfg::{Config, DefaultConfig};
pub use clear::Clear;
#[doc(inline)]
pub use pool::Pool;
pub(crate) use tid::Tid;
use cfg::CfgPrivate;
use shard::Shard;
use std::{fmt, marker::PhantomData, ptr, sync::Arc};
/// A sharded slab.
///
/// See the [crate-level documentation](crate) for details on using this type.
pub struct Slab {
shards: shard::Array, C>,
_cfg: PhantomData,
}
/// A handle that allows access to an occupied entry in a [`Slab`].
///
/// While the guard exists, it indicates to the slab that the item the guard
/// references is currently being accessed. If the item is removed from the slab
/// while a guard exists, the removal will be deferred until all guards are
/// dropped.
pub struct Entry<'a, T, C: cfg::Config = DefaultConfig> {
inner: page::slot::Guard, C>,
value: ptr::NonNull,
shard: &'a Shard, C>,
key: usize,
}
/// A handle to a vacant entry in a [`Slab`].
///
/// `VacantEntry` allows constructing values with the key that they will be
/// assigned to.
///
/// # Examples
///
/// ```
/// # use sharded_slab::Slab;
/// let mut slab = Slab::new();
///
/// let hello = {
/// let entry = slab.vacant_entry().unwrap();
/// let key = entry.key();
///
/// entry.insert((key, "hello"));
/// key
/// };
///
/// assert_eq!(hello, slab.get(hello).unwrap().0);
/// assert_eq!("hello", slab.get(hello).unwrap().1);
/// ```
#[derive(Debug)]
pub struct VacantEntry<'a, T, C: cfg::Config = DefaultConfig> {
inner: page::slot::InitGuard, C>,
key: usize,
_lt: PhantomData<&'a ()>,
}
/// An owned reference to an occupied entry in a [`Slab`].
///
/// While the guard exists, it indicates to the slab that the item the guard
/// references is currently being accessed. If the item is removed from the slab
/// while the guard exists, the removal will be deferred until all guards are
/// dropped.
///
/// Unlike [`Entry`], which borrows the slab, an `OwnedEntry` clones the [`Arc`]
/// around the slab. Therefore, it keeps the slab from being dropped until all
/// such guards have been dropped. This means that an `OwnedEntry` may be held for
/// an arbitrary lifetime.
///
/// # Examples
///
/// ```
/// # use sharded_slab::Slab;
/// use std::sync::Arc;
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let value = slab.clone().get_owned(key).unwrap();
///
/// // Now, the original `Arc` clone of the slab may be dropped, but the
/// // returned `OwnedEntry` can still access the value.
/// assert_eq!(value, "hello world");
/// ```
///
/// Unlike [`Entry`], an `OwnedEntry` may be stored in a struct which must live
/// for the `'static` lifetime:
///
/// ```
/// # use sharded_slab::Slab;
/// use sharded_slab::OwnedEntry;
/// use std::sync::Arc;
///
/// pub struct MyStruct {
/// entry: OwnedEntry<&'static str>,
/// // ... other fields ...
/// }
///
/// // Suppose this is some arbitrary function which requires a value that
/// // lives for the 'static lifetime...
/// fn function_requiring_static(t: &T) {
/// // ... do something extremely important and interesting ...
/// }
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let entry = slab.clone().get_owned(key).unwrap();
/// let my_struct = MyStruct {
/// entry,
/// // ...
/// };
///
/// // We can use `my_struct` anywhere where it is required to have the
/// // `'static` lifetime:
/// function_requiring_static(&my_struct);
/// ```
///
/// `OwnedEntry`s may be sent between threads:
///
/// ```
/// # use sharded_slab::Slab;
/// use std::{thread, sync::Arc};
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let value = slab.clone().get_owned(key).unwrap();
///
/// thread::spawn(move || {
/// assert_eq!(value, "hello world");
/// // ...
/// }).join().unwrap();
/// ```
///
/// [`get`]: Slab::get
/// [`Arc`]: std::sync::Arc
pub struct OwnedEntry
where
C: cfg::Config,
{
inner: page::slot::Guard, C>,
value: ptr::NonNull,
slab: Arc>,
key: usize,
}
impl Slab {
/// Returns a new slab with the default configuration parameters.
pub fn new() -> Self {
Self::new_with_config()
}
/// Returns a new slab with the provided configuration parameters.
pub fn new_with_config() -> Slab {
C::validate();
Slab {
shards: shard::Array::new(),
_cfg: PhantomData,
}
}
}
impl Slab {
/// The number of bits in each index which are used by the slab.
///
/// If other data is packed into the `usize` indices returned by
/// [`Slab::insert`], user code is free to use any bits higher than the
/// `USED_BITS`-th bit freely.
///
/// This is determined by the [`Config`] type that configures the slab's
/// parameters. By default, all bits are used; this can be changed by
/// overriding the [`Config::RESERVED_BITS`][res] constant.
///
/// [res]: crate::Config#RESERVED_BITS
pub const USED_BITS: usize = C::USED_BITS;
/// Inserts a value into the slab, returning the integer index at which that
/// value was inserted. This index can then be used to access the entry.
///
/// If this function returns `None`, then the shard for the current thread
/// is full and no items can be added until some are removed, or the maximum
/// number of shards has been reached.
///
/// # Examples
/// ```rust
/// # use sharded_slab::Slab;
/// let slab = Slab::new();
///
/// let key = slab.insert("hello world").unwrap();
/// assert_eq!(slab.get(key).unwrap(), "hello world");
/// ```
pub fn insert(&self, value: T) -> Option {
let (tid, shard) = self.shards.current();
test_println!("insert {:?}", tid);
let mut value = Some(value);
shard
.init_with(|idx, slot| {
let gen = slot.insert(&mut value)?;
Some(gen.pack(idx))
})
.map(|idx| tid.pack(idx))
}
/// Return a handle to a vacant entry allowing for further manipulation.
///
/// This function is useful when creating values that must contain their
/// slab index. The returned [`VacantEntry`] reserves a slot in the slab and
/// is able to return the index of the entry.
///
/// # Examples
///
/// ```
/// # use sharded_slab::Slab;
/// let mut slab = Slab::new();
///
/// let hello = {
/// let entry = slab.vacant_entry().unwrap();
/// let key = entry.key();
///
/// entry.insert((key, "hello"));
/// key
/// };
///
/// assert_eq!(hello, slab.get(hello).unwrap().0);
/// assert_eq!("hello", slab.get(hello).unwrap().1);
/// ```
pub fn vacant_entry(&self) -> Option> {
let (tid, shard) = self.shards.current();
test_println!("vacant_entry {:?}", tid);
shard.init_with(|idx, slot| {
let inner = slot.init()?;
let key = inner.generation().pack(tid.pack(idx));
Some(VacantEntry {
inner,
key,
_lt: PhantomData,
})
})
}
/// Remove the value at the given index in the slab, returning `true` if a
/// value was removed.
///
/// Unlike [`take`], this method does _not_ block the current thread until
/// the value can be removed. Instead, if another thread is currently
/// accessing that value, this marks it to be removed by that thread when it
/// finishes accessing the value.
///
/// # Examples
///
/// ```rust
/// let slab = sharded_slab::Slab::new();
/// let key = slab.insert("hello world").unwrap();
///
/// // Remove the item from the slab.
/// assert!(slab.remove(key));
///
/// // Now, the slot is empty.
/// assert!(!slab.contains(key));
/// ```
///
/// ```rust
/// use std::sync::Arc;
///
/// let slab = Arc::new(sharded_slab::Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// let slab2 = slab.clone();
/// let thread2 = std::thread::spawn(move || {
/// // Depending on when this thread begins executing, the item may
/// // or may not have already been removed...
/// if let Some(item) = slab2.get(key) {
/// assert_eq!(item, "hello world");
/// }
/// });
///
/// // The item will be removed by thread2 when it finishes accessing it.
/// assert!(slab.remove(key));
///
/// thread2.join().unwrap();
/// assert!(!slab.contains(key));
/// ```
/// [`take`]: Slab::take
pub fn remove(&self, idx: usize) -> bool {
// The `Drop` impl for `Entry` calls `remove_local` or `remove_remote` based
// on where the guard was dropped from. If the dropped guard was the last one, this will
// call `Slot::remove_value` which actually clears storage.
let tid = C::unpack_tid(idx);
test_println!("rm_deferred {:?}", tid);
let shard = self.shards.get(tid.as_usize());
if tid.is_current() {
shard.map(|shard| shard.remove_local(idx)).unwrap_or(false)
} else {
shard.map(|shard| shard.remove_remote(idx)).unwrap_or(false)
}
}
/// Removes the value associated with the given key from the slab, returning
/// it.
///
/// If the slab does not contain a value for that key, `None` is returned
/// instead.
///
/// If the value associated with the given key is currently being
/// accessed by another thread, this method will block the current thread
/// until the item is no longer accessed. If this is not desired, use
/// [`remove`] instead.
///
/// **Note**: This method blocks the calling thread by spinning until the
/// currently outstanding references are released. Spinning for long periods
/// of time can result in high CPU time and power consumption. Therefore,
/// `take` should only be called when other references to the slot are
/// expected to be dropped soon (e.g., when all accesses are relatively
/// short).
///
/// # Examples
///
/// ```rust
/// let slab = sharded_slab::Slab::new();
/// let key = slab.insert("hello world").unwrap();
///
/// // Remove the item from the slab, returning it.
/// assert_eq!(slab.take(key), Some("hello world"));
///
/// // Now, the slot is empty.
/// assert!(!slab.contains(key));
/// ```
///
/// ```rust
/// use std::sync::Arc;
///
/// let slab = Arc::new(sharded_slab::Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// let slab2 = slab.clone();
/// let thread2 = std::thread::spawn(move || {
/// // Depending on when this thread begins executing, the item may
/// // or may not have already been removed...
/// if let Some(item) = slab2.get(key) {
/// assert_eq!(item, "hello world");
/// }
/// });
///
/// // The item will only be removed when the other thread finishes
/// // accessing it.
/// assert_eq!(slab.take(key), Some("hello world"));
///
/// thread2.join().unwrap();
/// assert!(!slab.contains(key));
/// ```
/// [`remove`]: Slab::remove
pub fn take(&self, idx: usize) -> Option {
let tid = C::unpack_tid(idx);
test_println!("rm {:?}", tid);
let shard = self.shards.get(tid.as_usize())?;
if tid.is_current() {
shard.take_local(idx)
} else {
shard.take_remote(idx)
}
}
/// Return a reference to the value associated with the given key.
///
/// If the slab does not contain a value for the given key, or if the
/// maximum number of concurrent references to the slot has been reached,
/// `None` is returned instead.
///
/// # Examples
///
/// ```rust
/// let slab = sharded_slab::Slab::new();
/// let key = slab.insert("hello world").unwrap();
///
/// assert_eq!(slab.get(key).unwrap(), "hello world");
/// assert!(slab.get(12345).is_none());
/// ```
pub fn get(&self, key: usize) -> Option> {
let tid = C::unpack_tid(key);
test_println!("get {:?}; current={:?}", tid, Tid::::current());
let shard = self.shards.get(tid.as_usize())?;
shard.with_slot(key, |slot| {
let inner = slot.get(C::unpack_gen(key))?;
let value = ptr::NonNull::from(slot.value().as_ref().unwrap());
Some(Entry {
inner,
value,
shard,
key,
})
})
}
/// Return an owned reference to the value at the given index.
///
/// If the slab does not contain a value for the given key, `None` is
/// returned instead.
///
/// Unlike [`get`], which borrows the slab, this method _clones_ the [`Arc`]
/// around the slab. This means that the returned [`OwnedEntry`] can be held
/// for an arbitrary lifetime. However, this method requires that the slab
/// itself be wrapped in an `Arc`.
///
/// # Examples
///
/// ```
/// # use sharded_slab::Slab;
/// use std::sync::Arc;
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let value = slab.clone().get_owned(key).unwrap();
///
/// // Now, the original `Arc` clone of the slab may be dropped, but the
/// // returned `OwnedEntry` can still access the value.
/// assert_eq!(value, "hello world");
/// ```
///
/// Unlike [`Entry`], an `OwnedEntry` may be stored in a struct which must live
/// for the `'static` lifetime:
///
/// ```
/// # use sharded_slab::Slab;
/// use sharded_slab::OwnedEntry;
/// use std::sync::Arc;
///
/// pub struct MyStruct {
/// entry: OwnedEntry<&'static str>,
/// // ... other fields ...
/// }
///
/// // Suppose this is some arbitrary function which requires a value that
/// // lives for the 'static lifetime...
/// fn function_requiring_static(t: &T) {
/// // ... do something extremely important and interesting ...
/// }
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let entry = slab.clone().get_owned(key).unwrap();
/// let my_struct = MyStruct {
/// entry,
/// // ...
/// };
///
/// // We can use `my_struct` anywhere where it is required to have the
/// // `'static` lifetime:
/// function_requiring_static(&my_struct);
/// ```
///
/// [`OwnedEntry`]s may be sent between threads:
///
/// ```
/// # use sharded_slab::Slab;
/// use std::{thread, sync::Arc};
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let value = slab.clone().get_owned(key).unwrap();
///
/// thread::spawn(move || {
/// assert_eq!(value, "hello world");
/// // ...
/// }).join().unwrap();
/// ```
///
/// [`get`]: Slab::get
/// [`Arc`]: std::sync::Arc
pub fn get_owned(self: Arc, key: usize) -> Option> {
let tid = C::unpack_tid(key);
test_println!("get_owned {:?}; current={:?}", tid, Tid::::current());
let shard = self.shards.get(tid.as_usize())?;
shard.with_slot(key, |slot| {
let inner = slot.get(C::unpack_gen(key))?;
let value = ptr::NonNull::from(slot.value().as_ref().unwrap());
Some(OwnedEntry {
inner,
value,
slab: self.clone(),
key,
})
})
}
/// Returns `true` if the slab contains a value for the given key.
///
/// # Examples
///
/// ```
/// let slab = sharded_slab::Slab::new();
///
/// let key = slab.insert("hello world").unwrap();
/// assert!(slab.contains(key));
///
/// slab.take(key).unwrap();
/// assert!(!slab.contains(key));
/// ```
pub fn contains(&self, key: usize) -> bool {
self.get(key).is_some()
}
/// Returns an iterator over all the items in the slab.
pub fn unique_iter(&mut self) -> iter::UniqueIter<'_, T, C> {
let mut shards = self.shards.iter_mut();
let shard = shards.next().expect("must be at least 1 shard");
let mut pages = shard.iter();
let slots = pages.next().and_then(page::Shared::iter);
iter::UniqueIter {
shards,
slots,
pages,
}
}
}
impl Default for Slab {
fn default() -> Self {
Self::new()
}
}
impl fmt::Debug for Slab {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.debug_struct("Slab")
.field("shards", &self.shards)
.field("config", &C::debug())
.finish()
}
}
unsafe impl Send for Slab {}
unsafe impl Sync for Slab {}
// === impl Entry ===
impl<'a, T, C: cfg::Config> Entry<'a, T, C> {
/// Returns the key used to access the guard.
pub fn key(&self) -> usize {
self.key
}
#[inline(always)]
fn value(&self) -> &T {
unsafe {
// Safety: this is always going to be valid, as it's projected from
// the safe reference to `self.value` --- this is just to avoid
// having to `expect` an option in the hot path when dereferencing.
self.value.as_ref()
}
}
}
impl<'a, T, C: cfg::Config> std::ops::Deref for Entry<'a, T, C> {
type Target = T;
fn deref(&self) -> &Self::Target {
self.value()
}
}
impl<'a, T, C: cfg::Config> Drop for Entry<'a, T, C> {
fn drop(&mut self) {
let should_remove = unsafe {
// Safety: calling `slot::Guard::release` is unsafe, since the
// `Guard` value contains a pointer to the slot that may outlive the
// slab containing that slot. Here, the `Entry` guard owns a
// borrowed reference to the shard containing that slot, which
// ensures that the slot will not be dropped while this `Guard`
// exists.
self.inner.release()
};
if should_remove {
self.shard.clear_after_release(self.key)
}
}
}
impl<'a, T, C> fmt::Debug for Entry<'a, T, C>
where
T: fmt::Debug,
C: cfg::Config,
{
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
fmt::Debug::fmt(self.value(), f)
}
}
impl<'a, T, C> PartialEq for Entry<'a, T, C>
where
T: PartialEq,
C: cfg::Config,
{
fn eq(&self, other: &T) -> bool {
self.value().eq(other)
}
}
// === impl VacantEntry ===
impl<'a, T, C: cfg::Config> VacantEntry<'a, T, C> {
/// Insert a value in the entry.
///
/// To get the integer index at which this value will be inserted, use
/// [`key`] prior to calling `insert`.
///
/// # Examples
///
/// ```
/// # use sharded_slab::Slab;
/// let mut slab = Slab::new();
///
/// let hello = {
/// let entry = slab.vacant_entry().unwrap();
/// let key = entry.key();
///
/// entry.insert((key, "hello"));
/// key
/// };
///
/// assert_eq!(hello, slab.get(hello).unwrap().0);
/// assert_eq!("hello", slab.get(hello).unwrap().1);
/// ```
///
/// [`key`]: VacantEntry::key
pub fn insert(mut self, val: T) {
let value = unsafe {
// Safety: this `VacantEntry` only lives as long as the `Slab` it was
// borrowed from, so it cannot outlive the entry's slot.
self.inner.value_mut()
};
debug_assert!(
value.is_none(),
"tried to insert to a slot that already had a value!"
);
*value = Some(val);
let _released = unsafe {
// Safety: again, this `VacantEntry` only lives as long as the
// `Slab` it was borrowed from, so it cannot outlive the entry's
// slot.
self.inner.release()
};
debug_assert!(
!_released,
"removing a value before it was inserted should be a no-op"
)
}
/// Return the integer index at which this entry will be inserted.
///
/// A value stored in this entry will be associated with this key.
///
/// # Examples
///
/// ```
/// # use sharded_slab::*;
/// let mut slab = Slab::new();
///
/// let hello = {
/// let entry = slab.vacant_entry().unwrap();
/// let key = entry.key();
///
/// entry.insert((key, "hello"));
/// key
/// };
///
/// assert_eq!(hello, slab.get(hello).unwrap().0);
/// assert_eq!("hello", slab.get(hello).unwrap().1);
/// ```
pub fn key(&self) -> usize {
self.key
}
}
// === impl OwnedEntry ===
impl OwnedEntry
where
C: cfg::Config,
{
/// Returns the key used to access this guard
pub fn key(&self) -> usize {
self.key
}
#[inline(always)]
fn value(&self) -> &T {
unsafe {
// Safety: this is always going to be valid, as it's projected from
// the safe reference to `self.value` --- this is just to avoid
// having to `expect` an option in the hot path when dereferencing.
self.value.as_ref()
}
}
}
impl std::ops::Deref for OwnedEntry
where
C: cfg::Config,
{
type Target = T;
fn deref(&self) -> &Self::Target {
self.value()
}
}
impl Drop for OwnedEntry
where
C: cfg::Config,
{
fn drop(&mut self) {
test_println!("drop OwnedEntry: try clearing data");
let should_clear = unsafe {
// Safety: calling `slot::Guard::release` is unsafe, since the
// `Guard` value contains a pointer to the slot that may outlive the
// slab containing that slot. Here, the `OwnedEntry` owns an `Arc`
// clone of the pool, which keeps it alive as long as the `OwnedEntry`
// exists.
self.inner.release()
};
if should_clear {
let shard_idx = Tid::::from_packed(self.key);
test_println!("-> shard={:?}", shard_idx);
if let Some(shard) = self.slab.shards.get(shard_idx.as_usize()) {
shard.clear_after_release(self.key)
} else {
test_println!("-> shard={:?} does not exist! THIS IS A BUG", shard_idx);
debug_assert!(std::thread::panicking(), "[internal error] tried to drop an `OwnedEntry` to a slot on a shard that never existed!");
}
}
}
}
impl fmt::Debug for OwnedEntry
where
T: fmt::Debug,
C: cfg::Config,
{
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
fmt::Debug::fmt(self.value(), f)
}
}
impl PartialEq for OwnedEntry
where
T: PartialEq,
C: cfg::Config,
{
fn eq(&self, other: &T) -> bool {
*self.value() == *other
}
}
unsafe impl Sync for OwnedEntry
where
T: Sync,
C: cfg::Config,
{
}
unsafe impl Send for OwnedEntry
where
T: Sync,
C: cfg::Config,
{
}
// === pack ===
pub(crate) trait Pack: Sized {
// ====== provided by each implementation =================================
/// The number of bits occupied by this type when packed into a usize.
///
/// This must be provided to determine the number of bits into which to pack
/// the type.
const LEN: usize;
/// The type packed on the less significant side of this type.
///
/// If this type is packed into the least significant bit of a usize, this
/// should be `()`, which occupies no bytes.
///
/// This is used to calculate the shift amount for packing this value.
type Prev: Pack;
// ====== calculated automatically ========================================
/// A number consisting of `Self::LEN` 1 bits, starting at the least
/// significant bit.
///
/// This is the higest value this type can represent. This number is shifted
/// left by `Self::SHIFT` bits to calculate this type's `MASK`.
///
/// This is computed automatically based on `Self::LEN`.
const BITS: usize = {
let shift = 1 << (Self::LEN - 1);
shift | (shift - 1)
};
/// The number of bits to shift a number to pack it into a usize with other
/// values.
///
/// This is caculated automatically based on the `LEN` and `SHIFT` constants
/// of the previous value.
const SHIFT: usize = Self::Prev::SHIFT + Self::Prev::LEN;
/// The mask to extract only this type from a packed `usize`.
///
/// This is calculated by shifting `Self::BITS` left by `Self::SHIFT`.
const MASK: usize = Self::BITS << Self::SHIFT;
fn as_usize(&self) -> usize;
fn from_usize(val: usize) -> Self;
#[inline(always)]
fn pack(&self, to: usize) -> usize {
let value = self.as_usize();
debug_assert!(value <= Self::BITS);
(to & !Self::MASK) | (value << Self::SHIFT)
}
#[inline(always)]
fn from_packed(from: usize) -> Self {
let value = (from & Self::MASK) >> Self::SHIFT;
debug_assert!(value <= Self::BITS);
Self::from_usize(value)
}
}
impl Pack for () {
const BITS: usize = 0;
const LEN: usize = 0;
const SHIFT: usize = 0;
const MASK: usize = 0;
type Prev = ();
fn as_usize(&self) -> usize {
unreachable!()
}
fn from_usize(_val: usize) -> Self {
unreachable!()
}
fn pack(&self, _to: usize) -> usize {
unreachable!()
}
fn from_packed(_from: usize) -> Self {
unreachable!()
}
}
#[cfg(test)]
pub(crate) use self::tests::util as test_util;
#[cfg(test)]
mod tests;
�������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/macros.rs��������������������������������������������������������������������0000644�0000000�0000000�00000004133�00726746425�0014631�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������macro_rules! test_println {
($($arg:tt)*) => {
if cfg!(test) && cfg!(slab_print) {
if std::thread::panicking() {
// getting the thread ID while panicking doesn't seem to play super nicely with loom's
// mock lazy_static...
println!("[PANIC {:>17}:{:<3}] {}", file!(), line!(), format_args!($($arg)*))
} else {
println!("[{:?} {:>17}:{:<3}] {}", crate::Tid::::current(), file!(), line!(), format_args!($($arg)*))
}
}
}
}
#[cfg(all(test, loom))]
macro_rules! test_dbg {
($e:expr) => {
match $e {
e => {
test_println!("{} = {:?}", stringify!($e), &e);
e
}
}
};
}
macro_rules! panic_in_drop {
($($arg:tt)*) => {
if !std::thread::panicking() {
panic!($($arg)*)
} else {
let thread = std::thread::current();
eprintln!(
"thread '{thread}' attempted to panic at '{msg}', {file}:{line}:{col}\n\
note: we were already unwinding due to a previous panic.",
thread = thread.name().unwrap_or(""),
msg = format_args!($($arg)*),
file = file!(),
line = line!(),
col = column!(),
);
}
}
}
macro_rules! debug_assert_eq_in_drop {
($this:expr, $that:expr) => {
debug_assert_eq_in_drop!(@inner $this, $that, "")
};
($this:expr, $that:expr, $($arg:tt)+) => {
debug_assert_eq_in_drop!(@inner $this, $that, format_args!(": {}", format_args!($($arg)+)))
};
(@inner $this:expr, $that:expr, $msg:expr) => {
if cfg!(debug_assertions) {
if $this != $that {
panic_in_drop!(
"assertion failed ({} == {})\n left: `{:?}`,\n right: `{:?}`{}",
stringify!($this),
stringify!($that),
$this,
$that,
$msg,
)
}
}
}
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/page/mod.rs������������������������������������������������������������������0000644�0000000�0000000�00000031243�00726746425�0015042�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use crate::cfg::{self, CfgPrivate};
use crate::clear::Clear;
use crate::sync::UnsafeCell;
use crate::Pack;
pub(crate) mod slot;
mod stack;
pub(crate) use self::slot::Slot;
use std::{fmt, marker::PhantomData};
/// A page address encodes the location of a slot within a shard (the page
/// number and offset within that page) as a single linear value.
#[repr(transparent)]
pub(crate) struct Addr {
addr: usize,
_cfg: PhantomData,
}
impl Addr {
const NULL: usize = Self::BITS + 1;
pub(crate) fn index(self) -> usize {
// Since every page is twice as large as the previous page, and all page sizes
// are powers of two, we can determine the page index that contains a given
// address by counting leading zeros, which tells us what power of two
// the offset fits into.
//
// First, we must shift down to the smallest page size, so that the last
// offset on the first page becomes 0.
let shifted = (self.addr + C::INITIAL_SZ) >> C::ADDR_INDEX_SHIFT;
// Now, we can determine the number of twos places by counting the
// number of leading zeros (unused twos places) in the number's binary
// representation, and subtracting that count from the total number of bits in a word.
cfg::WIDTH - shifted.leading_zeros() as usize
}
pub(crate) fn offset(self) -> usize {
self.addr
}
}
pub(crate) trait FreeList {
fn push(&self, new_head: usize, slot: &Slot)
where
C: cfg::Config;
}
impl Pack for Addr {
const LEN: usize = C::MAX_PAGES + C::ADDR_INDEX_SHIFT;
type Prev = ();
fn as_usize(&self) -> usize {
self.addr
}
fn from_usize(addr: usize) -> Self {
debug_assert!(addr <= Self::BITS);
Self {
addr,
_cfg: PhantomData,
}
}
}
pub(crate) type Iter<'a, T, C> = std::iter::FilterMap<
std::slice::Iter<'a, Slot, C>>,
fn(&'a Slot, C>) -> Option<&'a T>,
>;
pub(crate) struct Local {
/// Index of the first slot on the local free list
head: UnsafeCell,
}
pub(crate) struct Shared {
/// The remote free list
///
/// Slots freed from a remote thread are pushed onto this list.
remote: stack::TransferStack,
// Total size of the page.
//
// If the head index of the local or remote free list is greater than the size of the
// page, then that free list is emtpy. If the head of both free lists is greater than `size`
// then there are no slots left in that page.
size: usize,
prev_sz: usize,
slab: UnsafeCell>>,
}
type Slots = Box<[Slot]>;
impl Local {
pub(crate) fn new() -> Self {
Self {
head: UnsafeCell::new(0),
}
}
#[inline(always)]
fn head(&self) -> usize {
self.head.with(|head| unsafe { *head })
}
#[inline(always)]
fn set_head(&self, new_head: usize) {
self.head.with_mut(|head| unsafe {
*head = new_head;
})
}
}
impl FreeList for Local {
fn push(&self, new_head: usize, slot: &Slot) {
slot.set_next(self.head());
self.set_head(new_head);
}
}
impl Shared
where
C: cfg::Config,
{
const NULL: usize = Addr::::NULL;
pub(crate) fn new(size: usize, prev_sz: usize) -> Self {
Self {
prev_sz,
size,
remote: stack::TransferStack::new(),
slab: UnsafeCell::new(None),
}
}
/// Return the head of the freelist
///
/// If there is space on the local list, it returns the head of the local list. Otherwise, it
/// pops all the slots from the global list and returns the head of that list
///
/// *Note*: The local list's head is reset when setting the new state in the slot pointed to be
/// `head` returned from this function
#[inline]
fn pop(&self, local: &Local) -> Option {
let head = local.head();
test_println!("-> local head {:?}", head);
// are there any items on the local free list? (fast path)
let head = if head < self.size {
head
} else {
// slow path: if the local free list is empty, pop all the items on
// the remote free list.
let head = self.remote.pop_all();
test_println!("-> remote head {:?}", head);
head?
};
// if the head is still null, both the local and remote free lists are
// empty --- we can't fit any more items on this page.
if head == Self::NULL {
test_println!("-> NULL! {:?}", head);
None
} else {
Some(head)
}
}
/// Returns `true` if storage is currently allocated for this page, `false`
/// otherwise.
#[inline]
fn is_unallocated(&self) -> bool {
self.slab.with(|s| unsafe { (*s).is_none() })
}
#[inline]
pub(crate) fn with_slot<'a, U>(
&'a self,
addr: Addr,
f: impl FnOnce(&'a Slot) -> Option,
) -> Option {
let poff = addr.offset() - self.prev_sz;
test_println!("-> offset {:?}", poff);
self.slab.with(|slab| {
let slot = unsafe { &*slab }.as_ref()?.get(poff)?;
f(slot)
})
}
#[inline(always)]
pub(crate) fn free_list(&self) -> &impl FreeList {
&self.remote
}
}
impl<'a, T, C> Shared, C>
where
C: cfg::Config + 'a,
{
pub(crate) fn take(
&self,
addr: Addr,
gen: slot::Generation,
free_list: &F,
) -> Option
where
F: FreeList,
{
let offset = addr.offset() - self.prev_sz;
test_println!("-> take: offset {:?}", offset);
self.slab.with(|slab| {
let slab = unsafe { &*slab }.as_ref()?;
let slot = slab.get(offset)?;
slot.remove_value(gen, offset, free_list)
})
}
pub(crate) fn remove>(
&self,
addr: Addr,
gen: slot::Generation,
free_list: &F,
) -> bool {
let offset = addr.offset() - self.prev_sz;
test_println!("-> offset {:?}", offset);
self.slab.with(|slab| {
let slab = unsafe { &*slab }.as_ref();
if let Some(slot) = slab.and_then(|slab| slab.get(offset)) {
slot.try_remove_value(gen, offset, free_list)
} else {
false
}
})
}
// Need this function separately, as we need to pass a function pointer to `filter_map` and
// `Slot::value` just returns a `&T`, specifically a `&Option` for this impl.
fn make_ref(slot: &'a Slot, C>) -> Option<&'a T> {
slot.value().as_ref()
}
pub(crate) fn iter(&self) -> Option> {
let slab = self.slab.with(|slab| unsafe { (&*slab).as_ref() });
slab.map(|slab| {
slab.iter()
.filter_map(Shared::make_ref as fn(&'a Slot, C>) -> Option<&'a T>)
})
}
}
impl Shared
where
T: Clear + Default,
C: cfg::Config,
{
pub(crate) fn init_with(
&self,
local: &Local,
init: impl FnOnce(usize, &Slot) -> Option,
) -> Option {
let head = self.pop(local)?;
// do we need to allocate storage for this page?
if self.is_unallocated() {
self.allocate();
}
let index = head + self.prev_sz;
let result = self.slab.with(|slab| {
let slab = unsafe { &*(slab) }
.as_ref()
.expect("page must have been allocated to insert!");
let slot = &slab[head];
let result = init(index, slot)?;
local.set_head(slot.next());
Some(result)
})?;
test_println!("-> init_with: insert at offset: {}", index);
Some(result)
}
/// Allocates storage for the page's slots.
#[cold]
fn allocate(&self) {
test_println!("-> alloc new page ({})", self.size);
debug_assert!(self.is_unallocated());
let mut slab = Vec::with_capacity(self.size);
slab.extend((1..self.size).map(Slot::new));
slab.push(Slot::new(Self::NULL));
self.slab.with_mut(|s| {
// safety: this mut access is safe — it only occurs to initially allocate the page,
// which only happens on this thread; if the page has not yet been allocated, other
// threads will not try to access it yet.
unsafe {
*s = Some(slab.into_boxed_slice());
}
});
}
pub(crate) fn mark_clear>(
&self,
addr: Addr,
gen: slot::Generation,
free_list: &F,
) -> bool {
let offset = addr.offset() - self.prev_sz;
test_println!("-> offset {:?}", offset);
self.slab.with(|slab| {
let slab = unsafe { &*slab }.as_ref();
if let Some(slot) = slab.and_then(|slab| slab.get(offset)) {
slot.try_clear_storage(gen, offset, free_list)
} else {
false
}
})
}
pub(crate) fn clear>(
&self,
addr: Addr,
gen: slot::Generation,
free_list: &F,
) -> bool {
let offset = addr.offset() - self.prev_sz;
test_println!("-> offset {:?}", offset);
self.slab.with(|slab| {
let slab = unsafe { &*slab }.as_ref();
if let Some(slot) = slab.and_then(|slab| slab.get(offset)) {
slot.clear_storage(gen, offset, free_list)
} else {
false
}
})
}
}
impl fmt::Debug for Local {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
self.head.with(|head| {
let head = unsafe { *head };
f.debug_struct("Local")
.field("head", &format_args!("{:#0x}", head))
.finish()
})
}
}
impl fmt::Debug for Shared {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.debug_struct("Shared")
.field("remote", &self.remote)
.field("prev_sz", &self.prev_sz)
.field("size", &self.size)
// .field("slab", &self.slab)
.finish()
}
}
impl fmt::Debug for Addr {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.debug_struct("Addr")
.field("addr", &format_args!("{:#0x}", &self.addr))
.field("index", &self.index())
.field("offset", &self.offset())
.finish()
}
}
impl PartialEq for Addr {
fn eq(&self, other: &Self) -> bool {
self.addr == other.addr
}
}
impl Eq for Addr {}
impl PartialOrd for Addr {
fn partial_cmp(&self, other: &Self) -> Option {
self.addr.partial_cmp(&other.addr)
}
}
impl Ord for Addr {
fn cmp(&self, other: &Self) -> std::cmp::Ordering {
self.addr.cmp(&other.addr)
}
}
impl Clone for Addr {
fn clone(&self) -> Self {
Self::from_usize(self.addr)
}
}
impl Copy for Addr {}
#[inline(always)]
pub(crate) fn indices(idx: usize) -> (Addr, usize) {
let addr = C::unpack_addr(idx);
(addr, addr.index())
}
#[cfg(test)]
mod test {
use super::*;
use crate::Pack;
use proptest::prelude::*;
proptest! {
#[test]
fn addr_roundtrips(pidx in 0usize..Addr::::BITS) {
let addr = Addr::::from_usize(pidx);
let packed = addr.pack(0);
assert_eq!(addr, Addr::from_packed(packed));
}
#[test]
fn gen_roundtrips(gen in 0usize..slot::Generation::::BITS) {
let gen = slot::Generation::::from_usize(gen);
let packed = gen.pack(0);
assert_eq!(gen, slot::Generation::from_packed(packed));
}
#[test]
fn page_roundtrips(
gen in 0usize..slot::Generation::::BITS,
addr in 0usize..Addr::::BITS,
) {
let gen = slot::Generation::::from_usize(gen);
let addr = Addr::::from_usize(addr);
let packed = gen.pack(addr.pack(0));
assert_eq!(addr, Addr::from_packed(packed));
assert_eq!(gen, slot::Generation::from_packed(packed));
}
}
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/page/slot.rs�����������������������������������������������������������������0000644�0000000�0000000�00000072747�00726746425�0015262�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use super::FreeList;
use crate::sync::{
atomic::{AtomicUsize, Ordering},
hint, UnsafeCell,
};
use crate::{cfg, clear::Clear, Pack, Tid};
use std::{fmt, marker::PhantomData, mem, ptr, thread};
pub(crate) struct Slot {
lifecycle: AtomicUsize,
/// The offset of the next item on the free list.
next: UnsafeCell,
/// The data stored in the slot.
item: UnsafeCell,
_cfg: PhantomData,
}
#[derive(Debug)]
pub(crate) struct Guard {
slot: ptr::NonNull>,
}
#[derive(Debug)]
pub(crate) struct InitGuard {
slot: ptr::NonNull>,
curr_lifecycle: usize,
released: bool,
}
#[repr(transparent)]
pub(crate) struct Generation {
value: usize,
_cfg: PhantomData,
}
#[repr(transparent)]
pub(crate) struct RefCount {
value: usize,
_cfg: PhantomData,
}
pub(crate) struct Lifecycle {
state: State,
_cfg: PhantomData,
}
struct LifecycleGen(Generation);
#[derive(Debug, Eq, PartialEq, Copy, Clone)]
#[repr(usize)]
enum State {
Present = 0b00,
Marked = 0b01,
Removing = 0b11,
}
impl Pack for Generation {
/// Use all the remaining bits in the word for the generation counter, minus
/// any bits reserved by the user.
const LEN: usize = (cfg::WIDTH - C::RESERVED_BITS) - Self::SHIFT;
type Prev = Tid;
#[inline(always)]
fn from_usize(u: usize) -> Self {
debug_assert!(u <= Self::BITS);
Self::new(u)
}
#[inline(always)]
fn as_usize(&self) -> usize {
self.value
}
}
impl Generation {
fn new(value: usize) -> Self {
Self {
value,
_cfg: PhantomData,
}
}
}
// Slot methods which should work across all trait bounds
impl Slot
where
C: cfg::Config,
{
#[inline(always)]
pub(super) fn next(&self) -> usize {
self.next.with(|next| unsafe { *next })
}
#[inline(always)]
pub(crate) fn value(&self) -> &T {
self.item.with(|item| unsafe { &*item })
}
#[inline(always)]
pub(super) fn set_next(&self, next: usize) {
self.next.with_mut(|n| unsafe {
(*n) = next;
})
}
#[inline(always)]
pub(crate) fn get(&self, gen: Generation) -> Option> {
let mut lifecycle = self.lifecycle.load(Ordering::Acquire);
loop {
// Unpack the current state.
let state = Lifecycle::::from_packed(lifecycle);
let current_gen = LifecycleGen::::from_packed(lifecycle).0;
let refs = RefCount::::from_packed(lifecycle);
test_println!(
"-> get {:?}; current_gen={:?}; lifecycle={:#x}; state={:?}; refs={:?};",
gen,
current_gen,
lifecycle,
state,
refs,
);
// Is it okay to access this slot? The accessed generation must be
// current, and the slot must not be in the process of being
// removed. If we can no longer access the slot at the given
// generation, return `None`.
if gen != current_gen || state != Lifecycle::PRESENT {
test_println!("-> get: no longer exists!");
return None;
}
// Try to increment the slot's ref count by one.
let new_refs = refs.incr()?;
match self.lifecycle.compare_exchange(
lifecycle,
new_refs.pack(current_gen.pack(state.pack(0))),
Ordering::AcqRel,
Ordering::Acquire,
) {
Ok(_) => {
test_println!("-> {:?}", new_refs);
return Some(Guard {
slot: ptr::NonNull::from(self),
});
}
Err(actual) => {
// Another thread modified the slot's state before us! We
// need to retry with the new state.
//
// Since the new state may mean that the accessed generation
// is no longer valid, we'll check again on the next
// iteration of the loop.
test_println!("-> get: retrying; lifecycle={:#x};", actual);
lifecycle = actual;
}
};
}
}
/// Marks this slot to be released, returning `true` if the slot can be
/// mutated *now* and `false` otherwise.
///
/// This method checks if there are any references to this slot. If there _are_ valid
/// references, it just marks them for modification and returns and the next thread calling
/// either `clear_storage` or `remove_value` will try and modify the storage
fn mark_release(&self, gen: Generation) -> Option {
let mut lifecycle = self.lifecycle.load(Ordering::Acquire);
let mut curr_gen;
// Try to advance the slot's state to "MARKED", which indicates that it
// should be removed when it is no longer concurrently accessed.
loop {
curr_gen = LifecycleGen::from_packed(lifecycle).0;
test_println!(
"-> mark_release; gen={:?}; current_gen={:?};",
gen,
curr_gen
);
// Is the slot still at the generation we are trying to remove?
if gen != curr_gen {
return None;
}
let state = Lifecycle::::from_packed(lifecycle).state;
test_println!("-> mark_release; state={:?};", state);
match state {
State::Removing => {
test_println!("--> mark_release; cannot release (already removed!)");
return None;
}
State::Marked => {
test_println!("--> mark_release; already marked;");
break;
}
State::Present => {}
};
// Set the new state to `MARKED`.
let new_lifecycle = Lifecycle::::MARKED.pack(lifecycle);
test_println!(
"-> mark_release; old_lifecycle={:#x}; new_lifecycle={:#x};",
lifecycle,
new_lifecycle
);
match self.lifecycle.compare_exchange(
lifecycle,
new_lifecycle,
Ordering::AcqRel,
Ordering::Acquire,
) {
Ok(_) => break,
Err(actual) => {
test_println!("-> mark_release; retrying");
lifecycle = actual;
}
}
}
// Unpack the current reference count to see if we can remove the slot now.
let refs = RefCount::::from_packed(lifecycle);
test_println!("-> mark_release: marked; refs={:?};", refs);
// Are there currently outstanding references to the slot? If so, it
// will have to be removed when those references are dropped.
Some(refs.value == 0)
}
/// Mutates this slot.
///
/// This method spins until no references to this slot are left, and calls the mutator
fn release_with(&self, gen: Generation, offset: usize, free: &F, mutator: M) -> R
where
F: FreeList,
M: FnOnce(Option<&mut T>) -> R,
{
let mut lifecycle = self.lifecycle.load(Ordering::Acquire);
let mut advanced = false;
// Exponential spin backoff while waiting for the slot to be released.
let mut spin_exp = 0;
let next_gen = gen.advance();
loop {
let current_gen = Generation::from_packed(lifecycle);
test_println!("-> release_with; lifecycle={:#x}; expected_gen={:?}; current_gen={:?}; next_gen={:?};",
lifecycle,
gen,
current_gen,
next_gen
);
// First, make sure we are actually able to remove the value.
// If we're going to remove the value, the generation has to match
// the value that `remove_value` was called with...unless we've
// already stored the new generation.
if (!advanced) && gen != current_gen {
test_println!("-> already removed!");
return mutator(None);
}
match self.lifecycle.compare_exchange(
lifecycle,
next_gen.pack(lifecycle),
Ordering::AcqRel,
Ordering::Acquire,
) {
Ok(actual) => {
// If we're in this state, we have successfully advanced to
// the next generation.
advanced = true;
// Make sure that there are no outstanding references.
let refs = RefCount::::from_packed(actual);
test_println!("-> advanced gen; lifecycle={:#x}; refs={:?};", actual, refs);
if refs.value == 0 {
test_println!("-> ok to remove!");
// safety: we've modified the generation of this slot and any other thread
// calling this method will exit out at the generation check above in the
// next iteraton of the loop.
let value = self
.item
.with_mut(|item| mutator(Some(unsafe { &mut *item })));
free.push(offset, self);
return value;
}
// Otherwise, a reference must be dropped before we can
// remove the value. Spin here until there are no refs remaining...
test_println!("-> refs={:?}; spin...", refs);
// Back off, spinning and possibly yielding.
exponential_backoff(&mut spin_exp);
}
Err(actual) => {
test_println!("-> retrying; lifecycle={:#x};", actual);
lifecycle = actual;
// The state changed; reset the spin backoff.
spin_exp = 0;
}
}
}
}
/// Initialize a slot
///
/// This method initializes and sets up the state for a slot. When being used in `Pool`, we
/// only need to ensure that the `Slot` is in the right `state, while when being used in a
/// `Slab` we want to insert a value into it, as the memory is not initialized
pub(crate) fn init(&self) -> Option> {
// Load the current lifecycle state.
let lifecycle = self.lifecycle.load(Ordering::Acquire);
let gen = LifecycleGen::::from_packed(lifecycle).0;
let refs = RefCount::::from_packed(lifecycle);
test_println!(
"-> initialize_state; state={:?}; gen={:?}; refs={:?};",
Lifecycle::::from_packed(lifecycle),
gen,
refs,
);
if refs.value != 0 {
test_println!("-> initialize while referenced! cancelling");
return None;
}
Some(InitGuard {
slot: ptr::NonNull::from(self),
curr_lifecycle: lifecycle,
released: false,
})
}
}
// Slot impl which _needs_ an `Option` for self.item, this is for `Slab` to use.
impl Slot, C>
where
C: cfg::Config,
{
fn is_empty(&self) -> bool {
self.item.with(|item| unsafe { (*item).is_none() })
}
/// Insert a value into a slot
///
/// We first initialize the state and then insert the pased in value into the slot.
#[inline]
pub(crate) fn insert(&self, value: &mut Option) -> Option
These benchmarks demonstrate that, while the sharded approach introduces
a small constant-factor overhead, it offers significantly better
performance across concurrent accesses.
[benchmarks]: https://github.com/hawkw/sharded-slab/blob/master/benches/bench.rs
[`criterion`]: https://crates.io/crates/criterion
## License
This project is licensed under the [MIT license](LICENSE).
### Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted
for inclusion in this project by you, shall be licensed as MIT, without any
additional terms or conditions.
��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/benches/bench.rs�����������������������������������������������������������������0000644�0000000�0000000�00000015456�00726746425�0015256�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use criterion::{criterion_group, criterion_main, BenchmarkId, Criterion};
use std::{
sync::{Arc, Barrier, RwLock},
thread,
time::{Duration, Instant},
};
#[derive(Clone)]
struct MultithreadedBench {
start: Arc,
end: Arc,
slab: Arc,
}
impl MultithreadedBench {
fn new(slab: Arc) -> Self {
Self {
start: Arc::new(Barrier::new(5)),
end: Arc::new(Barrier::new(5)),
slab,
}
}
fn thread(&self, f: impl FnOnce(&Barrier, &T) + Send + 'static) -> &Self {
let start = self.start.clone();
let end = self.end.clone();
let slab = self.slab.clone();
thread::spawn(move || {
f(&*start, &*slab);
end.wait();
});
self
}
fn run(&self) -> Duration {
self.start.wait();
let t0 = Instant::now();
self.end.wait();
t0.elapsed()
}
}
const N_INSERTIONS: &[usize] = &[100, 300, 500, 700, 1000, 3000, 5000];
fn insert_remove_local(c: &mut Criterion) {
// the 10000-insertion benchmark takes the `slab` crate about an hour to
// run; don't run this unless you're prepared for that...
// const N_INSERTIONS: &'static [usize] = &[100, 500, 1000, 5000, 10000];
let mut group = c.benchmark_group("insert_remove_local");
let g = group.measurement_time(Duration::from_secs(15));
for i in N_INSERTIONS {
g.bench_with_input(BenchmarkId::new("sharded_slab", i), i, |b, &i| {
b.iter_custom(|iters| {
let mut total = Duration::from_secs(0);
for _ in 0..iters {
let bench = MultithreadedBench::new(Arc::new(sharded_slab::Slab::new()));
let elapsed = bench
.thread(move |start, slab| {
start.wait();
let v: Vec<_> = (0..i).map(|i| slab.insert(i).unwrap()).collect();
for i in v {
slab.remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> = (0..i).map(|i| slab.insert(i).unwrap()).collect();
for i in v {
slab.remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> = (0..i).map(|i| slab.insert(i).unwrap()).collect();
for i in v {
slab.remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> = (0..i).map(|i| slab.insert(i).unwrap()).collect();
for i in v {
slab.remove(i);
}
})
.run();
total += elapsed;
}
total
})
});
g.bench_with_input(BenchmarkId::new("slab_biglock", i), i, |b, &i| {
b.iter_custom(|iters| {
let mut total = Duration::from_secs(0);
let i = i;
for _ in 0..iters {
let bench = MultithreadedBench::new(Arc::new(RwLock::new(slab::Slab::new())));
let elapsed = bench
.thread(move |start, slab| {
start.wait();
let v: Vec<_> =
(0..i).map(|i| slab.write().unwrap().insert(i)).collect();
for i in v {
slab.write().unwrap().remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> =
(0..i).map(|i| slab.write().unwrap().insert(i)).collect();
for i in v {
slab.write().unwrap().remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> =
(0..i).map(|i| slab.write().unwrap().insert(i)).collect();
for i in v {
slab.write().unwrap().remove(i);
}
})
.thread(move |start, slab| {
start.wait();
let v: Vec<_> =
(0..i).map(|i| slab.write().unwrap().insert(i)).collect();
for i in v {
slab.write().unwrap().remove(i);
}
})
.run();
total += elapsed;
}
total
})
});
}
group.finish();
}
fn insert_remove_single_thread(c: &mut Criterion) {
// the 10000-insertion benchmark takes the `slab` crate about an hour to
// run; don't run this unless you're prepared for that...
// const N_INSERTIONS: &'static [usize] = &[100, 500, 1000, 5000, 10000];
let mut group = c.benchmark_group("insert_remove_single_threaded");
for i in N_INSERTIONS {
group.bench_with_input(BenchmarkId::new("sharded_slab", i), i, |b, &i| {
let slab = sharded_slab::Slab::new();
b.iter(|| {
let v: Vec<_> = (0..i).map(|i| slab.insert(i).unwrap()).collect();
for i in v {
slab.remove(i);
}
});
});
group.bench_with_input(BenchmarkId::new("slab_no_lock", i), i, |b, &i| {
let mut slab = slab::Slab::new();
b.iter(|| {
let v: Vec<_> = (0..i).map(|i| slab.insert(i)).collect();
for i in v {
slab.remove(i);
}
});
});
group.bench_with_input(BenchmarkId::new("slab_uncontended", i), i, |b, &i| {
let slab = RwLock::new(slab::Slab::new());
b.iter(|| {
let v: Vec<_> = (0..i).map(|i| slab.write().unwrap().insert(i)).collect();
for i in v {
slab.write().unwrap().remove(i);
}
});
});
}
group.finish();
}
criterion_group!(benches, insert_remove_local, insert_remove_single_thread);
criterion_main!(benches);
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/bin/loom.sh����������������������������������������������������������������������0000755�0000000�0000000�00000001011�00726746425�0014255�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������#!/usr/bin/env bash
# Runs Loom tests with defaults for Loom's configuration values.
#
# The tests are compiled in release mode to improve performance, but debug
# assertions are enabled.
#
# Any arguments to this script are passed to the `cargo test` invocation.
RUSTFLAGS="${RUSTFLAGS} --cfg loom -C debug-assertions=on" \
LOOM_MAX_PREEMPTIONS="${LOOM_MAX_PREEMPTIONS:-2}" \
LOOM_CHECKPOINT_INTERVAL="${LOOM_CHECKPOINT_INTERVAL:-1}" \
LOOM_LOG=1 \
LOOM_LOCATION=1 \
cargo test --release --lib "$@"
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/cfg.rs�����������������������������������������������������������������������0000644�0000000�0000000�00000015341�00726746425�0014107�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use crate::page::{
slot::{Generation, RefCount},
Addr,
};
use crate::Pack;
use std::{fmt, marker::PhantomData};
/// Configuration parameters which can be overridden to tune the behavior of a slab.
pub trait Config: Sized {
/// The maximum number of threads which can access the slab.
///
/// This value (rounded to a power of two) determines the number of shards
/// in the slab. If a thread is created, accesses the slab, and then terminates,
/// its shard may be reused and thus does not count against the maximum
/// number of threads once the thread has terminated.
const MAX_THREADS: usize = DefaultConfig::MAX_THREADS;
/// The maximum number of pages in each shard in the slab.
///
/// This value, in combination with `INITIAL_PAGE_SIZE`, determines how many
/// bits of each index are used to represent page addresses.
const MAX_PAGES: usize = DefaultConfig::MAX_PAGES;
/// The size of the first page in each shard.
///
/// When a page in a shard has been filled with values, a new page
/// will be allocated that is twice as large as the previous page. Thus, the
/// second page will be twice this size, and the third will be four times
/// this size, and so on.
///
/// Note that page sizes must be powers of two. If this value is not a power
/// of two, it will be rounded to the next power of two.
const INITIAL_PAGE_SIZE: usize = DefaultConfig::INITIAL_PAGE_SIZE;
/// Sets a number of high-order bits in each index which are reserved from
/// user code.
///
/// Note that these bits are taken from the generation counter; if the page
/// address and thread IDs are configured to use a large number of bits,
/// reserving additional bits will decrease the period of the generation
/// counter. These should thus be used relatively sparingly, to ensure that
/// generation counters are able to effectively prevent the ABA problem.
const RESERVED_BITS: usize = 0;
}
pub(crate) trait CfgPrivate: Config {
const USED_BITS: usize = Generation::::LEN + Generation::::SHIFT;
const INITIAL_SZ: usize = next_pow2(Self::INITIAL_PAGE_SIZE);
const MAX_SHARDS: usize = next_pow2(Self::MAX_THREADS - 1);
const ADDR_INDEX_SHIFT: usize = Self::INITIAL_SZ.trailing_zeros() as usize + 1;
fn page_size(n: usize) -> usize {
Self::INITIAL_SZ * 2usize.pow(n as _)
}
fn debug() -> DebugConfig {
DebugConfig { _cfg: PhantomData }
}
fn validate() {
assert!(
Self::INITIAL_SZ.is_power_of_two(),
"invalid Config: {:#?}",
Self::debug(),
);
assert!(
Self::INITIAL_SZ <= Addr::::BITS,
"invalid Config: {:#?}",
Self::debug()
);
assert!(
Generation::::BITS >= 3,
"invalid Config: {:#?}\ngeneration counter should be at least 3 bits!",
Self::debug()
);
assert!(
Self::USED_BITS <= WIDTH,
"invalid Config: {:#?}\ntotal number of bits per index is too large to fit in a word!",
Self::debug()
);
assert!(
WIDTH - Self::USED_BITS >= Self::RESERVED_BITS,
"invalid Config: {:#?}\nindices are too large to fit reserved bits!",
Self::debug()
);
assert!(
RefCount::::MAX > 1,
"invalid config: {:#?}\n maximum concurrent references would be {}",
Self::debug(),
RefCount::::MAX,
);
}
#[inline(always)]
fn unpack>(packed: usize) -> A {
A::from_packed(packed)
}
#[inline(always)]
fn unpack_addr(packed: usize) -> Addr {
Self::unpack(packed)
}
#[inline(always)]
fn unpack_tid(packed: usize) -> crate::Tid {
Self::unpack(packed)
}
#[inline(always)]
fn unpack_gen(packed: usize) -> Generation {
Self::unpack(packed)
}
}
impl CfgPrivate for C {}
/// Default slab configuration values.
#[derive(Copy, Clone)]
pub struct DefaultConfig {
_p: (),
}
pub(crate) struct DebugConfig {
_cfg: PhantomData,
}
pub(crate) const WIDTH: usize = std::mem::size_of::() * 8;
pub(crate) const fn next_pow2(n: usize) -> usize {
let pow2 = n.count_ones() == 1;
let zeros = n.leading_zeros();
1 << (WIDTH - zeros as usize - pow2 as usize)
}
// === impl DefaultConfig ===
impl Config for DefaultConfig {
const INITIAL_PAGE_SIZE: usize = 32;
#[cfg(target_pointer_width = "64")]
const MAX_THREADS: usize = 4096;
#[cfg(target_pointer_width = "32")]
// TODO(eliza): can we find enough bits to give 32-bit platforms more threads?
const MAX_THREADS: usize = 128;
const MAX_PAGES: usize = WIDTH / 2;
}
impl fmt::Debug for DefaultConfig {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
Self::debug().fmt(f)
}
}
impl fmt::Debug for DebugConfig {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.debug_struct(std::any::type_name::())
.field("initial_page_size", &C::INITIAL_SZ)
.field("max_shards", &C::MAX_SHARDS)
.field("max_pages", &C::MAX_PAGES)
.field("used_bits", &C::USED_BITS)
.field("reserved_bits", &C::RESERVED_BITS)
.field("pointer_width", &WIDTH)
.field("max_concurrent_references", &RefCount::::MAX)
.finish()
}
}
#[cfg(test)]
mod tests {
use super::*;
use crate::test_util;
use crate::Slab;
#[test]
#[cfg_attr(loom, ignore)]
#[should_panic]
fn validates_max_refs() {
struct GiantGenConfig;
// Configure the slab with a very large number of bits for the generation
// counter. This will only leave 1 bit to use for the slot reference
// counter, which will fail to validate.
impl Config for GiantGenConfig {
const INITIAL_PAGE_SIZE: usize = 1;
const MAX_THREADS: usize = 1;
const MAX_PAGES: usize = 1;
}
let _slab = Slab::::new_with_config::();
}
#[test]
#[cfg_attr(loom, ignore)]
fn big() {
let slab = Slab::new();
for i in 0..10000 {
println!("{:?}", i);
let k = slab.insert(i).expect("insert");
assert_eq!(slab.get(k).expect("get"), i);
}
}
#[test]
#[cfg_attr(loom, ignore)]
fn custom_page_sz() {
let slab = Slab::new_with_config::();
for i in 0..4096 {
println!("{}", i);
let k = slab.insert(i).expect("insert");
assert_eq!(slab.get(k).expect("get"), i);
}
}
}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/clear.rs���������������������������������������������������������������������0000644�0000000�0000000�00000005231�00726746425�0014433�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use std::{collections, hash, ops::DerefMut, sync};
/// Trait implemented by types which can be cleared in place, retaining any
/// allocated memory.
///
/// This is essentially a generalization of methods on standard library
/// collection types, including as [`Vec::clear`], [`String::clear`], and
/// [`HashMap::clear`]. These methods drop all data stored in the collection,
/// but retain the collection's heap allocation for future use. Types such as
/// `BTreeMap`, whose `clear` methods drops allocations, should not
/// implement this trait.
///
/// When implemented for types which do not own a heap allocation, `Clear`
/// should reset the type in place if possible. If the type has an empty state
/// or stores `Option`s, those values should be reset to the empty state. For
/// "plain old data" types, which hold no pointers to other data and do not have
/// an empty or initial state, it's okay for a `Clear` implementation to be a
/// no-op. In that case, it essentially serves as a marker indicating that the
/// type may be reused to store new data.
///
/// [`Vec::clear`]: https://doc.rust-lang.org/stable/std/vec/struct.Vec.html#method.clear
/// [`String::clear`]: https://doc.rust-lang.org/stable/std/string/struct.String.html#method.clear
/// [`HashMap::clear`]: https://doc.rust-lang.org/stable/std/collections/struct.HashMap.html#method.clear
pub trait Clear {
/// Clear all data in `self`, retaining the allocated capacithy.
fn clear(&mut self);
}
impl Clear for Option {
fn clear(&mut self) {
let _ = self.take();
}
}
impl Clear for Box
where
T: Clear,
{
#[inline]
fn clear(&mut self) {
self.deref_mut().clear()
}
}
impl Clear for Vec {
#[inline]
fn clear(&mut self) {
Vec::clear(self)
}
}
impl Clear for collections::HashMap
where
K: hash::Hash + Eq,
S: hash::BuildHasher,
{
#[inline]
fn clear(&mut self) {
collections::HashMap::clear(self)
}
}
impl Clear for collections::HashSet
where
T: hash::Hash + Eq,
S: hash::BuildHasher,
{
#[inline]
fn clear(&mut self) {
collections::HashSet::clear(self)
}
}
impl Clear for String {
#[inline]
fn clear(&mut self) {
String::clear(self)
}
}
impl Clear for sync::Mutex {
#[inline]
fn clear(&mut self) {
self.get_mut().unwrap().clear();
}
}
impl Clear for sync::RwLock {
#[inline]
fn clear(&mut self) {
self.write().unwrap().clear();
}
}
#[cfg(all(loom, test))]
impl Clear for crate::sync::alloc::Track {
fn clear(&mut self) {
self.get_mut().clear()
}
}
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/implementation.rs������������������������������������������������������������0000644�0000000�0000000�00000020041�00726746425�0016366�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������// This module exists only to provide a separate page for the implementation
// documentation.
//! Notes on `sharded-slab`'s implementation and design.
//!
//! # Design
//!
//! The sharded slab's design is strongly inspired by the ideas presented by
//! Leijen, Zorn, and de Moura in [Mimalloc: Free List Sharding in
//! Action][mimalloc]. In this report, the authors present a novel design for a
//! memory allocator based on a concept of _free list sharding_.
//!
//! Memory allocators must keep track of what memory regions are not currently
//! allocated ("free") in order to provide them to future allocation requests.
//! The term [_free list_][freelist] refers to a technique for performing this
//! bookkeeping, where each free block stores a pointer to the next free block,
//! forming a linked list. The memory allocator keeps a pointer to the most
//! recently freed block, the _head_ of the free list. To allocate more memory,
//! the allocator pops from the free list by setting the head pointer to the
//! next free block of the current head block, and returning the previous head.
//! To deallocate a block, the block is pushed to the free list by setting its
//! first word to the current head pointer, and the head pointer is set to point
//! to the deallocated block. Most implementations of slab allocators backed by
//! arrays or vectors use a similar technique, where pointers are replaced by
//! indices into the backing array.
//!
//! When allocations and deallocations can occur concurrently across threads,
//! they must synchronize accesses to the free list; either by putting the
//! entire allocator state inside of a lock, or by using atomic operations to
//! treat the free list as a lock-free structure (such as a [Treiber stack]). In
//! both cases, there is a significant performance cost — even when the free
//! list is lock-free, it is likely that a noticeable amount of time will be
//! spent in compare-and-swap loops. Ideally, the global synchronzation point
//! created by the single global free list could be avoided as much as possible.
//!
//! The approach presented by Leijen, Zorn, and de Moura is to introduce
//! sharding and thus increase the granularity of synchronization significantly.
//! In mimalloc, the heap is _sharded_ so that each thread has its own
//! thread-local heap. Objects are always allocated from the local heap of the
//! thread where the allocation is performed. Because allocations are always
//! done from a thread's local heap, they need not be synchronized.
//!
//! However, since objects can move between threads before being deallocated,
//! _deallocations_ may still occur concurrently. Therefore, Leijen et al.
//! introduce a concept of _local_ and _global_ free lists. When an object is
//! deallocated on the same thread it was originally allocated on, it is placed
//! on the local free list; if it is deallocated on another thread, it goes on
//! the global free list for the heap of the thread from which it originated. To
//! allocate, the local free list is used first; if it is empty, the entire
//! global free list is popped onto the local free list. Since the local free
//! list is only ever accessed by the thread it belongs to, it does not require
//! synchronization at all, and because the global free list is popped from
//! infrequently, the cost of synchronization has a reduced impact. A majority
//! of allocations can occur without any synchronization at all; and
//! deallocations only require synchronization when an object has left its
//! parent thread (a relatively uncommon case).
//!
//! [mimalloc]: https://www.microsoft.com/en-us/research/uploads/prod/2019/06/mimalloc-tr-v1.pdf
//! [freelist]: https://en.wikipedia.org/wiki/Free_list
//! [Treiber stack]: https://en.wikipedia.org/wiki/Treiber_stack
//!
//! # Implementation
//!
//! A slab is represented as an array of [`MAX_THREADS`] _shards_. A shard
//! consists of a vector of one or more _pages_ plus associated metadata.
//! Finally, a page consists of an array of _slots_, head indices for the local
//! and remote free lists.
//!
//! ```text
//! ┌─────────────┐
//! │ shard 1 │
//! │ │ ┌─────────────┐ ┌────────┐
//! │ pages───────┼───▶│ page 1 │ │ │
//! ├─────────────┤ ├─────────────┤ ┌────▶│ next──┼─┐
//! │ shard 2 │ │ page 2 │ │ ├────────┤ │
//! ├─────────────┤ │ │ │ │XXXXXXXX│ │
//! │ shard 3 │ │ local_head──┼──┘ ├────────┤ │
//! └─────────────┘ │ remote_head─┼──┐ │ │◀┘
//! ... ├─────────────┤ │ │ next──┼─┐
//! ┌─────────────┐ │ page 3 │ │ ├────────┤ │
//! │ shard n │ └─────────────┘ │ │XXXXXXXX│ │
//! └─────────────┘ ... │ ├────────┤ │
//! ┌─────────────┐ │ │XXXXXXXX│ │
//! │ page n │ │ ├────────┤ │
//! └─────────────┘ │ │ │◀┘
//! └────▶│ next──┼───▶ ...
//! ├────────┤
//! │XXXXXXXX│
//! └────────┘
//! ```
//!
//!
//! The size of the first page in a shard is always a power of two, and every
//! subsequent page added after the first is twice as large as the page that
//! preceeds it.
//!
//! ```text
//!
//! pg.
//! ┌───┐ ┌─┬─┐
//! │ 0 │───▶ │ │
//! ├───┤ ├─┼─┼─┬─┐
//! │ 1 │───▶ │ │ │ │
//! ├───┤ ├─┼─┼─┼─┼─┬─┬─┬─┐
//! │ 2 │───▶ │ │ │ │ │ │ │ │
//! ├───┤ ├─┼─┼─┼─┼─┼─┼─┼─┼─┬─┬─┬─┬─┬─┬─┬─┐
//! │ 3 │───▶ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
//! └───┘ └─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┘
//! ```
//!
//! When searching for a free slot, the smallest page is searched first, and if
//! it is full, the search proceeds to the next page until either a free slot is
//! found or all available pages have been searched. If all available pages have
//! been searched and the maximum number of pages has not yet been reached, a
//! new page is then allocated.
//!
//! Since every page is twice as large as the previous page, and all page sizes
//! are powers of two, we can determine the page index that contains a given
//! address by shifting the address down by the smallest page size and
//! looking at how many twos places necessary to represent that number,
//! telling us what power of two page size it fits inside of. We can
//! determine the number of twos places by counting the number of leading
//! zeros (unused twos places) in the number's binary representation, and
//! subtracting that count from the total number of bits in a word.
//!
//! The formula for determining the page number that contains an offset is thus:
//!
//! ```rust,ignore
//! WIDTH - ((offset + INITIAL_PAGE_SIZE) >> INDEX_SHIFT).leading_zeros()
//! ```
//!
//! where `WIDTH` is the number of bits in a `usize`, and `INDEX_SHIFT` is
//!
//! ```rust,ignore
//! INITIAL_PAGE_SIZE.trailing_zeros() + 1;
//! ```
//!
//! [`MAX_THREADS`]: https://docs.rs/sharded-slab/latest/sharded_slab/trait.Config.html#associatedconstant.MAX_THREADS
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/iter.rs����������������������������������������������������������������������0000644�0000000�0000000�00000002417�00726746425�0014313�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use crate::{page, shard};
use std::slice;
#[derive(Debug)]
pub struct UniqueIter<'a, T, C: crate::cfg::Config> {
pub(super) shards: shard::IterMut<'a, Option, C>,
pub(super) pages: slice::Iter<'a, page::Shared, C>>,
pub(super) slots: Option>,
}
impl<'a, T, C: crate::cfg::Config> Iterator for UniqueIter<'a, T, C> {
type Item = &'a T;
fn next(&mut self) -> Option {
test_println!("UniqueIter::next");
loop {
test_println!("-> try next slot");
if let Some(item) = self.slots.as_mut().and_then(|slots| slots.next()) {
test_println!("-> found an item!");
return Some(item);
}
test_println!("-> try next page");
if let Some(page) = self.pages.next() {
test_println!("-> found another page");
self.slots = page.iter();
continue;
}
test_println!("-> try next shard");
if let Some(shard) = self.shards.next() {
test_println!("-> found another shard");
self.pages = shard.iter();
} else {
test_println!("-> all done!");
return None;
}
}
}
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/lib.rs�����������������������������������������������������������������������0000644�0000000�0000000�00000106601�00726746425�0014116�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������//! A lock-free concurrent slab.
//!
//! Slabs provide pre-allocated storage for many instances of a single data
//! type. When a large number of values of a single type are required,
//! this can be more efficient than allocating each item individually. Since the
//! allocated items are the same size, memory fragmentation is reduced, and
//! creating and removing new items can be very cheap.
//!
//! This crate implements a lock-free concurrent slab, indexed by `usize`s.
//!
//! ## Usage
//!
//! First, add this to your `Cargo.toml`:
//!
//! ```toml
//! sharded-slab = "0.1.1"
//! ```
//!
//! This crate provides two types, [`Slab`] and [`Pool`], which provide
//! slightly different APIs for using a sharded slab.
//!
//! [`Slab`] implements a slab for _storing_ small types, sharing them between
//! threads, and accessing them by index. New entries are allocated by
//! [inserting] data, moving it in by value. Similarly, entries may be
//! deallocated by [taking] from the slab, moving the value out. This API is
//! similar to a `Vec>`, but allowing lock-free concurrent insertion
//! and removal.
//!
//! In contrast, the [`Pool`] type provides an [object pool] style API for
//! _reusing storage_. Rather than constructing values and moving them into the
//! pool, as with [`Slab`], [allocating an entry][create] from the pool takes a
//! closure that's provided with a mutable reference to initialize the entry in
//! place. When entries are deallocated, they are [cleared] in place. Types
//! which own a heap allocation can be cleared by dropping any _data_ they
//! store, but retaining any previously-allocated capacity. This means that a
//! [`Pool`] may be used to reuse a set of existing heap allocations, reducing
//! allocator load.
//!
//! [inserting]: Slab::insert
//! [taking]: Slab::take
//! [create]: Pool::create
//! [cleared]: Clear
//! [object pool]: https://en.wikipedia.org/wiki/Object_pool_pattern
//!
//! # Examples
//!
//! Inserting an item into the slab, returning an index:
//! ```rust
//! # use sharded_slab::Slab;
//! let slab = Slab::new();
//!
//! let key = slab.insert("hello world").unwrap();
//! assert_eq!(slab.get(key).unwrap(), "hello world");
//! ```
//!
//! To share a slab across threads, it may be wrapped in an `Arc`:
//! ```rust
//! # use sharded_slab::Slab;
//! use std::sync::Arc;
//! let slab = Arc::new(Slab::new());
//!
//! let slab2 = slab.clone();
//! let thread2 = std::thread::spawn(move || {
//! let key = slab2.insert("hello from thread two").unwrap();
//! assert_eq!(slab2.get(key).unwrap(), "hello from thread two");
//! key
//! });
//!
//! let key1 = slab.insert("hello from thread one").unwrap();
//! assert_eq!(slab.get(key1).unwrap(), "hello from thread one");
//!
//! // Wait for thread 2 to complete.
//! let key2 = thread2.join().unwrap();
//!
//! // The item inserted by thread 2 remains in the slab.
//! assert_eq!(slab.get(key2).unwrap(), "hello from thread two");
//!```
//!
//! If items in the slab must be mutated, a `Mutex` or `RwLock` may be used for
//! each item, providing granular locking of items rather than of the slab:
//!
//! ```rust
//! # use sharded_slab::Slab;
//! use std::sync::{Arc, Mutex};
//! let slab = Arc::new(Slab::new());
//!
//! let key = slab.insert(Mutex::new(String::from("hello world"))).unwrap();
//!
//! let slab2 = slab.clone();
//! let thread2 = std::thread::spawn(move || {
//! let hello = slab2.get(key).expect("item missing");
//! let mut hello = hello.lock().expect("mutex poisoned");
//! *hello = String::from("hello everyone!");
//! });
//!
//! thread2.join().unwrap();
//!
//! let hello = slab.get(key).expect("item missing");
//! let mut hello = hello.lock().expect("mutex poisoned");
//! assert_eq!(hello.as_str(), "hello everyone!");
//! ```
//!
//! # Configuration
//!
//! For performance reasons, several values used by the slab are calculated as
//! constants. In order to allow users to tune the slab's parameters, we provide
//! a [`Config`] trait which defines these parameters as associated `consts`.
//! The `Slab` type is generic over a `C: Config` parameter.
//!
//! [`Config`]: trait.Config.html
//!
//! # Comparison with Similar Crates
//!
//! - [`slab`]: Carl Lerche's `slab` crate provides a slab implementation with a
//! similar API, implemented by storing all data in a single vector.
//!
//! Unlike `sharded_slab`, inserting and removing elements from the slab
//! requires mutable access. This means that if the slab is accessed
//! concurrently by multiple threads, it is necessary for it to be protected
//! by a `Mutex` or `RwLock`. Items may not be inserted or removed (or
//! accessed, if a `Mutex` is used) concurrently, even when they are
//! unrelated. In many cases, the lock can become a significant bottleneck. On
//! the other hand, this crate allows separate indices in the slab to be
//! accessed, inserted, and removed concurrently without requiring a global
//! lock. Therefore, when the slab is shared across multiple threads, this
//! crate offers significantly better performance than `slab`.
//!
//! However, the lock free slab introduces some additional constant-factor
//! overhead. This means that in use-cases where a slab is _not_ shared by
//! multiple threads and locking is not required, this crate will likely offer
//! slightly worse performance.
//!
//! In summary: `sharded-slab` offers significantly improved performance in
//! concurrent use-cases, while `slab` should be preferred in single-threaded
//! use-cases.
//!
//! [`slab`]: https://crates.io/crates/loom
//!
//! # Safety and Correctness
//!
//! Most implementations of lock-free data structures in Rust require some
//! amount of unsafe code, and this crate is not an exception. In order to catch
//! potential bugs in this unsafe code, we make use of [`loom`], a
//! permutation-testing tool for concurrent Rust programs. All `unsafe` blocks
//! this crate occur in accesses to `loom` `UnsafeCell`s. This means that when
//! those accesses occur in this crate's tests, `loom` will assert that they are
//! valid under the C11 memory model across multiple permutations of concurrent
//! executions of those tests.
//!
//! In order to guard against the [ABA problem][aba], this crate makes use of
//! _generational indices_. Each slot in the slab tracks a generation counter
//! which is incremented every time a value is inserted into that slot, and the
//! indices returned by [`Slab::insert`] include the generation of the slot when
//! the value was inserted, packed into the high-order bits of the index. This
//! ensures that if a value is inserted, removed, and a new value is inserted
//! into the same slot in the slab, the key returned by the first call to
//! `insert` will not map to the new value.
//!
//! Since a fixed number of bits are set aside to use for storing the generation
//! counter, the counter will wrap around after being incremented a number of
//! times. To avoid situations where a returned index lives long enough to see the
//! generation counter wrap around to the same value, it is good to be fairly
//! generous when configuring the allocation of index bits.
//!
//! [`loom`]: https://crates.io/crates/loom
//! [aba]: https://en.wikipedia.org/wiki/ABA_problem
//! [`Slab::insert`]: struct.Slab.html#method.insert
//!
//! # Performance
//!
//! These graphs were produced by [benchmarks] of the sharded slab implementation,
//! using the [`criterion`] crate.
//!
//! The first shows the results of a benchmark where an increasing number of
//! items are inserted and then removed into a slab concurrently by five
//! threads. It compares the performance of the sharded slab implementation
//! with a `RwLock`:
//!
//!
//!
//! The second graph shows the results of a benchmark where an increasing
//! number of items are inserted and then removed by a _single_ thread. It
//! compares the performance of the sharded slab implementation with an
//! `RwLock` and a `mut slab::Slab`.
//!
//!
//!
//! These benchmarks demonstrate that, while the sharded approach introduces
//! a small constant-factor overhead, it offers significantly better
//! performance across concurrent accesses.
//!
//! [benchmarks]: https://github.com/hawkw/sharded-slab/blob/master/benches/bench.rs
//! [`criterion`]: https://crates.io/crates/criterion
//!
//! # Implementation Notes
//!
//! See [this page](crate::implementation) for details on this crate's design
//! and implementation.
//!
#![doc(html_root_url = "https://docs.rs/sharded-slab/0.1.4")]
#![warn(missing_debug_implementations, missing_docs)]
#![cfg_attr(docsrs, warn(rustdoc::broken_intra_doc_links))]
#[macro_use]
mod macros;
pub mod implementation;
pub mod pool;
pub(crate) mod cfg;
pub(crate) mod sync;
mod clear;
mod iter;
mod page;
mod shard;
mod tid;
pub use cfg::{Config, DefaultConfig};
pub use clear::Clear;
#[doc(inline)]
pub use pool::Pool;
pub(crate) use tid::Tid;
use cfg::CfgPrivate;
use shard::Shard;
use std::{fmt, marker::PhantomData, ptr, sync::Arc};
/// A sharded slab.
///
/// See the [crate-level documentation](crate) for details on using this type.
pub struct Slab {
shards: shard::Array, C>,
_cfg: PhantomData,
}
/// A handle that allows access to an occupied entry in a [`Slab`].
///
/// While the guard exists, it indicates to the slab that the item the guard
/// references is currently being accessed. If the item is removed from the slab
/// while a guard exists, the removal will be deferred until all guards are
/// dropped.
pub struct Entry<'a, T, C: cfg::Config = DefaultConfig> {
inner: page::slot::Guard, C>,
value: ptr::NonNull,
shard: &'a Shard, C>,
key: usize,
}
/// A handle to a vacant entry in a [`Slab`].
///
/// `VacantEntry` allows constructing values with the key that they will be
/// assigned to.
///
/// # Examples
///
/// ```
/// # use sharded_slab::Slab;
/// let mut slab = Slab::new();
///
/// let hello = {
/// let entry = slab.vacant_entry().unwrap();
/// let key = entry.key();
///
/// entry.insert((key, "hello"));
/// key
/// };
///
/// assert_eq!(hello, slab.get(hello).unwrap().0);
/// assert_eq!("hello", slab.get(hello).unwrap().1);
/// ```
#[derive(Debug)]
pub struct VacantEntry<'a, T, C: cfg::Config = DefaultConfig> {
inner: page::slot::InitGuard, C>,
key: usize,
_lt: PhantomData<&'a ()>,
}
/// An owned reference to an occupied entry in a [`Slab`].
///
/// While the guard exists, it indicates to the slab that the item the guard
/// references is currently being accessed. If the item is removed from the slab
/// while the guard exists, the removal will be deferred until all guards are
/// dropped.
///
/// Unlike [`Entry`], which borrows the slab, an `OwnedEntry` clones the [`Arc`]
/// around the slab. Therefore, it keeps the slab from being dropped until all
/// such guards have been dropped. This means that an `OwnedEntry` may be held for
/// an arbitrary lifetime.
///
/// # Examples
///
/// ```
/// # use sharded_slab::Slab;
/// use std::sync::Arc;
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let value = slab.clone().get_owned(key).unwrap();
///
/// // Now, the original `Arc` clone of the slab may be dropped, but the
/// // returned `OwnedEntry` can still access the value.
/// assert_eq!(value, "hello world");
/// ```
///
/// Unlike [`Entry`], an `OwnedEntry` may be stored in a struct which must live
/// for the `'static` lifetime:
///
/// ```
/// # use sharded_slab::Slab;
/// use sharded_slab::OwnedEntry;
/// use std::sync::Arc;
///
/// pub struct MyStruct {
/// entry: OwnedEntry<&'static str>,
/// // ... other fields ...
/// }
///
/// // Suppose this is some arbitrary function which requires a value that
/// // lives for the 'static lifetime...
/// fn function_requiring_static(t: &T) {
/// // ... do something extremely important and interesting ...
/// }
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let entry = slab.clone().get_owned(key).unwrap();
/// let my_struct = MyStruct {
/// entry,
/// // ...
/// };
///
/// // We can use `my_struct` anywhere where it is required to have the
/// // `'static` lifetime:
/// function_requiring_static(&my_struct);
/// ```
///
/// `OwnedEntry`s may be sent between threads:
///
/// ```
/// # use sharded_slab::Slab;
/// use std::{thread, sync::Arc};
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let value = slab.clone().get_owned(key).unwrap();
///
/// thread::spawn(move || {
/// assert_eq!(value, "hello world");
/// // ...
/// }).join().unwrap();
/// ```
///
/// [`get`]: Slab::get
/// [`Arc`]: std::sync::Arc
pub struct OwnedEntry
where
C: cfg::Config,
{
inner: page::slot::Guard, C>,
value: ptr::NonNull,
slab: Arc>,
key: usize,
}
impl Slab {
/// Returns a new slab with the default configuration parameters.
pub fn new() -> Self {
Self::new_with_config()
}
/// Returns a new slab with the provided configuration parameters.
pub fn new_with_config() -> Slab {
C::validate();
Slab {
shards: shard::Array::new(),
_cfg: PhantomData,
}
}
}
impl Slab {
/// The number of bits in each index which are used by the slab.
///
/// If other data is packed into the `usize` indices returned by
/// [`Slab::insert`], user code is free to use any bits higher than the
/// `USED_BITS`-th bit freely.
///
/// This is determined by the [`Config`] type that configures the slab's
/// parameters. By default, all bits are used; this can be changed by
/// overriding the [`Config::RESERVED_BITS`][res] constant.
///
/// [res]: crate::Config#RESERVED_BITS
pub const USED_BITS: usize = C::USED_BITS;
/// Inserts a value into the slab, returning the integer index at which that
/// value was inserted. This index can then be used to access the entry.
///
/// If this function returns `None`, then the shard for the current thread
/// is full and no items can be added until some are removed, or the maximum
/// number of shards has been reached.
///
/// # Examples
/// ```rust
/// # use sharded_slab::Slab;
/// let slab = Slab::new();
///
/// let key = slab.insert("hello world").unwrap();
/// assert_eq!(slab.get(key).unwrap(), "hello world");
/// ```
pub fn insert(&self, value: T) -> Option {
let (tid, shard) = self.shards.current();
test_println!("insert {:?}", tid);
let mut value = Some(value);
shard
.init_with(|idx, slot| {
let gen = slot.insert(&mut value)?;
Some(gen.pack(idx))
})
.map(|idx| tid.pack(idx))
}
/// Return a handle to a vacant entry allowing for further manipulation.
///
/// This function is useful when creating values that must contain their
/// slab index. The returned [`VacantEntry`] reserves a slot in the slab and
/// is able to return the index of the entry.
///
/// # Examples
///
/// ```
/// # use sharded_slab::Slab;
/// let mut slab = Slab::new();
///
/// let hello = {
/// let entry = slab.vacant_entry().unwrap();
/// let key = entry.key();
///
/// entry.insert((key, "hello"));
/// key
/// };
///
/// assert_eq!(hello, slab.get(hello).unwrap().0);
/// assert_eq!("hello", slab.get(hello).unwrap().1);
/// ```
pub fn vacant_entry(&self) -> Option> {
let (tid, shard) = self.shards.current();
test_println!("vacant_entry {:?}", tid);
shard.init_with(|idx, slot| {
let inner = slot.init()?;
let key = inner.generation().pack(tid.pack(idx));
Some(VacantEntry {
inner,
key,
_lt: PhantomData,
})
})
}
/// Remove the value at the given index in the slab, returning `true` if a
/// value was removed.
///
/// Unlike [`take`], this method does _not_ block the current thread until
/// the value can be removed. Instead, if another thread is currently
/// accessing that value, this marks it to be removed by that thread when it
/// finishes accessing the value.
///
/// # Examples
///
/// ```rust
/// let slab = sharded_slab::Slab::new();
/// let key = slab.insert("hello world").unwrap();
///
/// // Remove the item from the slab.
/// assert!(slab.remove(key));
///
/// // Now, the slot is empty.
/// assert!(!slab.contains(key));
/// ```
///
/// ```rust
/// use std::sync::Arc;
///
/// let slab = Arc::new(sharded_slab::Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// let slab2 = slab.clone();
/// let thread2 = std::thread::spawn(move || {
/// // Depending on when this thread begins executing, the item may
/// // or may not have already been removed...
/// if let Some(item) = slab2.get(key) {
/// assert_eq!(item, "hello world");
/// }
/// });
///
/// // The item will be removed by thread2 when it finishes accessing it.
/// assert!(slab.remove(key));
///
/// thread2.join().unwrap();
/// assert!(!slab.contains(key));
/// ```
/// [`take`]: Slab::take
pub fn remove(&self, idx: usize) -> bool {
// The `Drop` impl for `Entry` calls `remove_local` or `remove_remote` based
// on where the guard was dropped from. If the dropped guard was the last one, this will
// call `Slot::remove_value` which actually clears storage.
let tid = C::unpack_tid(idx);
test_println!("rm_deferred {:?}", tid);
let shard = self.shards.get(tid.as_usize());
if tid.is_current() {
shard.map(|shard| shard.remove_local(idx)).unwrap_or(false)
} else {
shard.map(|shard| shard.remove_remote(idx)).unwrap_or(false)
}
}
/// Removes the value associated with the given key from the slab, returning
/// it.
///
/// If the slab does not contain a value for that key, `None` is returned
/// instead.
///
/// If the value associated with the given key is currently being
/// accessed by another thread, this method will block the current thread
/// until the item is no longer accessed. If this is not desired, use
/// [`remove`] instead.
///
/// **Note**: This method blocks the calling thread by spinning until the
/// currently outstanding references are released. Spinning for long periods
/// of time can result in high CPU time and power consumption. Therefore,
/// `take` should only be called when other references to the slot are
/// expected to be dropped soon (e.g., when all accesses are relatively
/// short).
///
/// # Examples
///
/// ```rust
/// let slab = sharded_slab::Slab::new();
/// let key = slab.insert("hello world").unwrap();
///
/// // Remove the item from the slab, returning it.
/// assert_eq!(slab.take(key), Some("hello world"));
///
/// // Now, the slot is empty.
/// assert!(!slab.contains(key));
/// ```
///
/// ```rust
/// use std::sync::Arc;
///
/// let slab = Arc::new(sharded_slab::Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// let slab2 = slab.clone();
/// let thread2 = std::thread::spawn(move || {
/// // Depending on when this thread begins executing, the item may
/// // or may not have already been removed...
/// if let Some(item) = slab2.get(key) {
/// assert_eq!(item, "hello world");
/// }
/// });
///
/// // The item will only be removed when the other thread finishes
/// // accessing it.
/// assert_eq!(slab.take(key), Some("hello world"));
///
/// thread2.join().unwrap();
/// assert!(!slab.contains(key));
/// ```
/// [`remove`]: Slab::remove
pub fn take(&self, idx: usize) -> Option {
let tid = C::unpack_tid(idx);
test_println!("rm {:?}", tid);
let shard = self.shards.get(tid.as_usize())?;
if tid.is_current() {
shard.take_local(idx)
} else {
shard.take_remote(idx)
}
}
/// Return a reference to the value associated with the given key.
///
/// If the slab does not contain a value for the given key, or if the
/// maximum number of concurrent references to the slot has been reached,
/// `None` is returned instead.
///
/// # Examples
///
/// ```rust
/// let slab = sharded_slab::Slab::new();
/// let key = slab.insert("hello world").unwrap();
///
/// assert_eq!(slab.get(key).unwrap(), "hello world");
/// assert!(slab.get(12345).is_none());
/// ```
pub fn get(&self, key: usize) -> Option> {
let tid = C::unpack_tid(key);
test_println!("get {:?}; current={:?}", tid, Tid::::current());
let shard = self.shards.get(tid.as_usize())?;
shard.with_slot(key, |slot| {
let inner = slot.get(C::unpack_gen(key))?;
let value = ptr::NonNull::from(slot.value().as_ref().unwrap());
Some(Entry {
inner,
value,
shard,
key,
})
})
}
/// Return an owned reference to the value at the given index.
///
/// If the slab does not contain a value for the given key, `None` is
/// returned instead.
///
/// Unlike [`get`], which borrows the slab, this method _clones_ the [`Arc`]
/// around the slab. This means that the returned [`OwnedEntry`] can be held
/// for an arbitrary lifetime. However, this method requires that the slab
/// itself be wrapped in an `Arc`.
///
/// # Examples
///
/// ```
/// # use sharded_slab::Slab;
/// use std::sync::Arc;
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let value = slab.clone().get_owned(key).unwrap();
///
/// // Now, the original `Arc` clone of the slab may be dropped, but the
/// // returned `OwnedEntry` can still access the value.
/// assert_eq!(value, "hello world");
/// ```
///
/// Unlike [`Entry`], an `OwnedEntry` may be stored in a struct which must live
/// for the `'static` lifetime:
///
/// ```
/// # use sharded_slab::Slab;
/// use sharded_slab::OwnedEntry;
/// use std::sync::Arc;
///
/// pub struct MyStruct {
/// entry: OwnedEntry<&'static str>,
/// // ... other fields ...
/// }
///
/// // Suppose this is some arbitrary function which requires a value that
/// // lives for the 'static lifetime...
/// fn function_requiring_static(t: &T) {
/// // ... do something extremely important and interesting ...
/// }
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let entry = slab.clone().get_owned(key).unwrap();
/// let my_struct = MyStruct {
/// entry,
/// // ...
/// };
///
/// // We can use `my_struct` anywhere where it is required to have the
/// // `'static` lifetime:
/// function_requiring_static(&my_struct);
/// ```
///
/// [`OwnedEntry`]s may be sent between threads:
///
/// ```
/// # use sharded_slab::Slab;
/// use std::{thread, sync::Arc};
///
/// let slab: Arc> = Arc::new(Slab::new());
/// let key = slab.insert("hello world").unwrap();
///
/// // Look up the created key, returning an `OwnedEntry`.
/// let value = slab.clone().get_owned(key).unwrap();
///
/// thread::spawn(move || {
/// assert_eq!(value, "hello world");
/// // ...
/// }).join().unwrap();
/// ```
///
/// [`get`]: Slab::get
/// [`Arc`]: std::sync::Arc
pub fn get_owned(self: Arc, key: usize) -> Option> {
let tid = C::unpack_tid(key);
test_println!("get_owned {:?}; current={:?}", tid, Tid::::current());
let shard = self.shards.get(tid.as_usize())?;
shard.with_slot(key, |slot| {
let inner = slot.get(C::unpack_gen(key))?;
let value = ptr::NonNull::from(slot.value().as_ref().unwrap());
Some(OwnedEntry {
inner,
value,
slab: self.clone(),
key,
})
})
}
/// Returns `true` if the slab contains a value for the given key.
///
/// # Examples
///
/// ```
/// let slab = sharded_slab::Slab::new();
///
/// let key = slab.insert("hello world").unwrap();
/// assert!(slab.contains(key));
///
/// slab.take(key).unwrap();
/// assert!(!slab.contains(key));
/// ```
pub fn contains(&self, key: usize) -> bool {
self.get(key).is_some()
}
/// Returns an iterator over all the items in the slab.
pub fn unique_iter(&mut self) -> iter::UniqueIter<'_, T, C> {
let mut shards = self.shards.iter_mut();
let shard = shards.next().expect("must be at least 1 shard");
let mut pages = shard.iter();
let slots = pages.next().and_then(page::Shared::iter);
iter::UniqueIter {
shards,
slots,
pages,
}
}
}
impl Default for Slab {
fn default() -> Self {
Self::new()
}
}
impl fmt::Debug for Slab {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.debug_struct("Slab")
.field("shards", &self.shards)
.field("config", &C::debug())
.finish()
}
}
unsafe impl Send for Slab {}
unsafe impl Sync for Slab {}
// === impl Entry ===
impl<'a, T, C: cfg::Config> Entry<'a, T, C> {
/// Returns the key used to access the guard.
pub fn key(&self) -> usize {
self.key
}
#[inline(always)]
fn value(&self) -> &T {
unsafe {
// Safety: this is always going to be valid, as it's projected from
// the safe reference to `self.value` --- this is just to avoid
// having to `expect` an option in the hot path when dereferencing.
self.value.as_ref()
}
}
}
impl<'a, T, C: cfg::Config> std::ops::Deref for Entry<'a, T, C> {
type Target = T;
fn deref(&self) -> &Self::Target {
self.value()
}
}
impl<'a, T, C: cfg::Config> Drop for Entry<'a, T, C> {
fn drop(&mut self) {
let should_remove = unsafe {
// Safety: calling `slot::Guard::release` is unsafe, since the
// `Guard` value contains a pointer to the slot that may outlive the
// slab containing that slot. Here, the `Entry` guard owns a
// borrowed reference to the shard containing that slot, which
// ensures that the slot will not be dropped while this `Guard`
// exists.
self.inner.release()
};
if should_remove {
self.shard.clear_after_release(self.key)
}
}
}
impl<'a, T, C> fmt::Debug for Entry<'a, T, C>
where
T: fmt::Debug,
C: cfg::Config,
{
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
fmt::Debug::fmt(self.value(), f)
}
}
impl<'a, T, C> PartialEq for Entry<'a, T, C>
where
T: PartialEq,
C: cfg::Config,
{
fn eq(&self, other: &T) -> bool {
self.value().eq(other)
}
}
// === impl VacantEntry ===
impl<'a, T, C: cfg::Config> VacantEntry<'a, T, C> {
/// Insert a value in the entry.
///
/// To get the integer index at which this value will be inserted, use
/// [`key`] prior to calling `insert`.
///
/// # Examples
///
/// ```
/// # use sharded_slab::Slab;
/// let mut slab = Slab::new();
///
/// let hello = {
/// let entry = slab.vacant_entry().unwrap();
/// let key = entry.key();
///
/// entry.insert((key, "hello"));
/// key
/// };
///
/// assert_eq!(hello, slab.get(hello).unwrap().0);
/// assert_eq!("hello", slab.get(hello).unwrap().1);
/// ```
///
/// [`key`]: VacantEntry::key
pub fn insert(mut self, val: T) {
let value = unsafe {
// Safety: this `VacantEntry` only lives as long as the `Slab` it was
// borrowed from, so it cannot outlive the entry's slot.
self.inner.value_mut()
};
debug_assert!(
value.is_none(),
"tried to insert to a slot that already had a value!"
);
*value = Some(val);
let _released = unsafe {
// Safety: again, this `VacantEntry` only lives as long as the
// `Slab` it was borrowed from, so it cannot outlive the entry's
// slot.
self.inner.release()
};
debug_assert!(
!_released,
"removing a value before it was inserted should be a no-op"
)
}
/// Return the integer index at which this entry will be inserted.
///
/// A value stored in this entry will be associated with this key.
///
/// # Examples
///
/// ```
/// # use sharded_slab::*;
/// let mut slab = Slab::new();
///
/// let hello = {
/// let entry = slab.vacant_entry().unwrap();
/// let key = entry.key();
///
/// entry.insert((key, "hello"));
/// key
/// };
///
/// assert_eq!(hello, slab.get(hello).unwrap().0);
/// assert_eq!("hello", slab.get(hello).unwrap().1);
/// ```
pub fn key(&self) -> usize {
self.key
}
}
// === impl OwnedEntry ===
impl OwnedEntry
where
C: cfg::Config,
{
/// Returns the key used to access this guard
pub fn key(&self) -> usize {
self.key
}
#[inline(always)]
fn value(&self) -> &T {
unsafe {
// Safety: this is always going to be valid, as it's projected from
// the safe reference to `self.value` --- this is just to avoid
// having to `expect` an option in the hot path when dereferencing.
self.value.as_ref()
}
}
}
impl std::ops::Deref for OwnedEntry
where
C: cfg::Config,
{
type Target = T;
fn deref(&self) -> &Self::Target {
self.value()
}
}
impl Drop for OwnedEntry
where
C: cfg::Config,
{
fn drop(&mut self) {
test_println!("drop OwnedEntry: try clearing data");
let should_clear = unsafe {
// Safety: calling `slot::Guard::release` is unsafe, since the
// `Guard` value contains a pointer to the slot that may outlive the
// slab containing that slot. Here, the `OwnedEntry` owns an `Arc`
// clone of the pool, which keeps it alive as long as the `OwnedEntry`
// exists.
self.inner.release()
};
if should_clear {
let shard_idx = Tid::::from_packed(self.key);
test_println!("-> shard={:?}", shard_idx);
if let Some(shard) = self.slab.shards.get(shard_idx.as_usize()) {
shard.clear_after_release(self.key)
} else {
test_println!("-> shard={:?} does not exist! THIS IS A BUG", shard_idx);
debug_assert!(std::thread::panicking(), "[internal error] tried to drop an `OwnedEntry` to a slot on a shard that never existed!");
}
}
}
}
impl fmt::Debug for OwnedEntry
where
T: fmt::Debug,
C: cfg::Config,
{
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
fmt::Debug::fmt(self.value(), f)
}
}
impl PartialEq for OwnedEntry
where
T: PartialEq,
C: cfg::Config,
{
fn eq(&self, other: &T) -> bool {
*self.value() == *other
}
}
unsafe impl Sync for OwnedEntry
where
T: Sync,
C: cfg::Config,
{
}
unsafe impl Send for OwnedEntry
where
T: Sync,
C: cfg::Config,
{
}
// === pack ===
pub(crate) trait Pack: Sized {
// ====== provided by each implementation =================================
/// The number of bits occupied by this type when packed into a usize.
///
/// This must be provided to determine the number of bits into which to pack
/// the type.
const LEN: usize;
/// The type packed on the less significant side of this type.
///
/// If this type is packed into the least significant bit of a usize, this
/// should be `()`, which occupies no bytes.
///
/// This is used to calculate the shift amount for packing this value.
type Prev: Pack;
// ====== calculated automatically ========================================
/// A number consisting of `Self::LEN` 1 bits, starting at the least
/// significant bit.
///
/// This is the higest value this type can represent. This number is shifted
/// left by `Self::SHIFT` bits to calculate this type's `MASK`.
///
/// This is computed automatically based on `Self::LEN`.
const BITS: usize = {
let shift = 1 << (Self::LEN - 1);
shift | (shift - 1)
};
/// The number of bits to shift a number to pack it into a usize with other
/// values.
///
/// This is caculated automatically based on the `LEN` and `SHIFT` constants
/// of the previous value.
const SHIFT: usize = Self::Prev::SHIFT + Self::Prev::LEN;
/// The mask to extract only this type from a packed `usize`.
///
/// This is calculated by shifting `Self::BITS` left by `Self::SHIFT`.
const MASK: usize = Self::BITS << Self::SHIFT;
fn as_usize(&self) -> usize;
fn from_usize(val: usize) -> Self;
#[inline(always)]
fn pack(&self, to: usize) -> usize {
let value = self.as_usize();
debug_assert!(value <= Self::BITS);
(to & !Self::MASK) | (value << Self::SHIFT)
}
#[inline(always)]
fn from_packed(from: usize) -> Self {
let value = (from & Self::MASK) >> Self::SHIFT;
debug_assert!(value <= Self::BITS);
Self::from_usize(value)
}
}
impl Pack for () {
const BITS: usize = 0;
const LEN: usize = 0;
const SHIFT: usize = 0;
const MASK: usize = 0;
type Prev = ();
fn as_usize(&self) -> usize {
unreachable!()
}
fn from_usize(_val: usize) -> Self {
unreachable!()
}
fn pack(&self, _to: usize) -> usize {
unreachable!()
}
fn from_packed(_from: usize) -> Self {
unreachable!()
}
}
#[cfg(test)]
pub(crate) use self::tests::util as test_util;
#[cfg(test)]
mod tests;
�������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/macros.rs��������������������������������������������������������������������0000644�0000000�0000000�00000004133�00726746425�0014631�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������macro_rules! test_println {
($($arg:tt)*) => {
if cfg!(test) && cfg!(slab_print) {
if std::thread::panicking() {
// getting the thread ID while panicking doesn't seem to play super nicely with loom's
// mock lazy_static...
println!("[PANIC {:>17}:{:<3}] {}", file!(), line!(), format_args!($($arg)*))
} else {
println!("[{:?} {:>17}:{:<3}] {}", crate::Tid::::current(), file!(), line!(), format_args!($($arg)*))
}
}
}
}
#[cfg(all(test, loom))]
macro_rules! test_dbg {
($e:expr) => {
match $e {
e => {
test_println!("{} = {:?}", stringify!($e), &e);
e
}
}
};
}
macro_rules! panic_in_drop {
($($arg:tt)*) => {
if !std::thread::panicking() {
panic!($($arg)*)
} else {
let thread = std::thread::current();
eprintln!(
"thread '{thread}' attempted to panic at '{msg}', {file}:{line}:{col}\n\
note: we were already unwinding due to a previous panic.",
thread = thread.name().unwrap_or(""),
msg = format_args!($($arg)*),
file = file!(),
line = line!(),
col = column!(),
);
}
}
}
macro_rules! debug_assert_eq_in_drop {
($this:expr, $that:expr) => {
debug_assert_eq_in_drop!(@inner $this, $that, "")
};
($this:expr, $that:expr, $($arg:tt)+) => {
debug_assert_eq_in_drop!(@inner $this, $that, format_args!(": {}", format_args!($($arg)+)))
};
(@inner $this:expr, $that:expr, $msg:expr) => {
if cfg!(debug_assertions) {
if $this != $that {
panic_in_drop!(
"assertion failed ({} == {})\n left: `{:?}`,\n right: `{:?}`{}",
stringify!($this),
stringify!($that),
$this,
$that,
$msg,
)
}
}
}
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/page/mod.rs������������������������������������������������������������������0000644�0000000�0000000�00000031243�00726746425�0015042�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use crate::cfg::{self, CfgPrivate};
use crate::clear::Clear;
use crate::sync::UnsafeCell;
use crate::Pack;
pub(crate) mod slot;
mod stack;
pub(crate) use self::slot::Slot;
use std::{fmt, marker::PhantomData};
/// A page address encodes the location of a slot within a shard (the page
/// number and offset within that page) as a single linear value.
#[repr(transparent)]
pub(crate) struct Addr {
addr: usize,
_cfg: PhantomData,
}
impl Addr {
const NULL: usize = Self::BITS + 1;
pub(crate) fn index(self) -> usize {
// Since every page is twice as large as the previous page, and all page sizes
// are powers of two, we can determine the page index that contains a given
// address by counting leading zeros, which tells us what power of two
// the offset fits into.
//
// First, we must shift down to the smallest page size, so that the last
// offset on the first page becomes 0.
let shifted = (self.addr + C::INITIAL_SZ) >> C::ADDR_INDEX_SHIFT;
// Now, we can determine the number of twos places by counting the
// number of leading zeros (unused twos places) in the number's binary
// representation, and subtracting that count from the total number of bits in a word.
cfg::WIDTH - shifted.leading_zeros() as usize
}
pub(crate) fn offset(self) -> usize {
self.addr
}
}
pub(crate) trait FreeList {
fn push(&self, new_head: usize, slot: &Slot)
where
C: cfg::Config;
}
impl Pack for Addr {
const LEN: usize = C::MAX_PAGES + C::ADDR_INDEX_SHIFT;
type Prev = ();
fn as_usize(&self) -> usize {
self.addr
}
fn from_usize(addr: usize) -> Self {
debug_assert!(addr <= Self::BITS);
Self {
addr,
_cfg: PhantomData,
}
}
}
pub(crate) type Iter<'a, T, C> = std::iter::FilterMap<
std::slice::Iter<'a, Slot, C>>,
fn(&'a Slot, C>) -> Option<&'a T>,
>;
pub(crate) struct Local {
/// Index of the first slot on the local free list
head: UnsafeCell,
}
pub(crate) struct Shared {
/// The remote free list
///
/// Slots freed from a remote thread are pushed onto this list.
remote: stack::TransferStack,
// Total size of the page.
//
// If the head index of the local or remote free list is greater than the size of the
// page, then that free list is emtpy. If the head of both free lists is greater than `size`
// then there are no slots left in that page.
size: usize,
prev_sz: usize,
slab: UnsafeCell>>,
}
type Slots = Box<[Slot]>;
impl Local {
pub(crate) fn new() -> Self {
Self {
head: UnsafeCell::new(0),
}
}
#[inline(always)]
fn head(&self) -> usize {
self.head.with(|head| unsafe { *head })
}
#[inline(always)]
fn set_head(&self, new_head: usize) {
self.head.with_mut(|head| unsafe {
*head = new_head;
})
}
}
impl FreeList for Local {
fn push(&self, new_head: usize, slot: &Slot) {
slot.set_next(self.head());
self.set_head(new_head);
}
}
impl Shared
where
C: cfg::Config,
{
const NULL: usize = Addr::::NULL;
pub(crate) fn new(size: usize, prev_sz: usize) -> Self {
Self {
prev_sz,
size,
remote: stack::TransferStack::new(),
slab: UnsafeCell::new(None),
}
}
/// Return the head of the freelist
///
/// If there is space on the local list, it returns the head of the local list. Otherwise, it
/// pops all the slots from the global list and returns the head of that list
///
/// *Note*: The local list's head is reset when setting the new state in the slot pointed to be
/// `head` returned from this function
#[inline]
fn pop(&self, local: &Local) -> Option {
let head = local.head();
test_println!("-> local head {:?}", head);
// are there any items on the local free list? (fast path)
let head = if head < self.size {
head
} else {
// slow path: if the local free list is empty, pop all the items on
// the remote free list.
let head = self.remote.pop_all();
test_println!("-> remote head {:?}", head);
head?
};
// if the head is still null, both the local and remote free lists are
// empty --- we can't fit any more items on this page.
if head == Self::NULL {
test_println!("-> NULL! {:?}", head);
None
} else {
Some(head)
}
}
/// Returns `true` if storage is currently allocated for this page, `false`
/// otherwise.
#[inline]
fn is_unallocated(&self) -> bool {
self.slab.with(|s| unsafe { (*s).is_none() })
}
#[inline]
pub(crate) fn with_slot<'a, U>(
&'a self,
addr: Addr,
f: impl FnOnce(&'a Slot) -> Option,
) -> Option {
let poff = addr.offset() - self.prev_sz;
test_println!("-> offset {:?}", poff);
self.slab.with(|slab| {
let slot = unsafe { &*slab }.as_ref()?.get(poff)?;
f(slot)
})
}
#[inline(always)]
pub(crate) fn free_list(&self) -> &impl FreeList {
&self.remote
}
}
impl<'a, T, C> Shared, C>
where
C: cfg::Config + 'a,
{
pub(crate) fn take(
&self,
addr: Addr,
gen: slot::Generation,
free_list: &F,
) -> Option
where
F: FreeList,
{
let offset = addr.offset() - self.prev_sz;
test_println!("-> take: offset {:?}", offset);
self.slab.with(|slab| {
let slab = unsafe { &*slab }.as_ref()?;
let slot = slab.get(offset)?;
slot.remove_value(gen, offset, free_list)
})
}
pub(crate) fn remove>(
&self,
addr: Addr,
gen: slot::Generation,
free_list: &F,
) -> bool {
let offset = addr.offset() - self.prev_sz;
test_println!("-> offset {:?}", offset);
self.slab.with(|slab| {
let slab = unsafe { &*slab }.as_ref();
if let Some(slot) = slab.and_then(|slab| slab.get(offset)) {
slot.try_remove_value(gen, offset, free_list)
} else {
false
}
})
}
// Need this function separately, as we need to pass a function pointer to `filter_map` and
// `Slot::value` just returns a `&T`, specifically a `&Option` for this impl.
fn make_ref(slot: &'a Slot, C>) -> Option<&'a T> {
slot.value().as_ref()
}
pub(crate) fn iter(&self) -> Option> {
let slab = self.slab.with(|slab| unsafe { (&*slab).as_ref() });
slab.map(|slab| {
slab.iter()
.filter_map(Shared::make_ref as fn(&'a Slot, C>) -> Option<&'a T>)
})
}
}
impl Shared
where
T: Clear + Default,
C: cfg::Config,
{
pub(crate) fn init_with(
&self,
local: &Local,
init: impl FnOnce(usize, &Slot) -> Option,
) -> Option {
let head = self.pop(local)?;
// do we need to allocate storage for this page?
if self.is_unallocated() {
self.allocate();
}
let index = head + self.prev_sz;
let result = self.slab.with(|slab| {
let slab = unsafe { &*(slab) }
.as_ref()
.expect("page must have been allocated to insert!");
let slot = &slab[head];
let result = init(index, slot)?;
local.set_head(slot.next());
Some(result)
})?;
test_println!("-> init_with: insert at offset: {}", index);
Some(result)
}
/// Allocates storage for the page's slots.
#[cold]
fn allocate(&self) {
test_println!("-> alloc new page ({})", self.size);
debug_assert!(self.is_unallocated());
let mut slab = Vec::with_capacity(self.size);
slab.extend((1..self.size).map(Slot::new));
slab.push(Slot::new(Self::NULL));
self.slab.with_mut(|s| {
// safety: this mut access is safe — it only occurs to initially allocate the page,
// which only happens on this thread; if the page has not yet been allocated, other
// threads will not try to access it yet.
unsafe {
*s = Some(slab.into_boxed_slice());
}
});
}
pub(crate) fn mark_clear>(
&self,
addr: Addr,
gen: slot::Generation,
free_list: &F,
) -> bool {
let offset = addr.offset() - self.prev_sz;
test_println!("-> offset {:?}", offset);
self.slab.with(|slab| {
let slab = unsafe { &*slab }.as_ref();
if let Some(slot) = slab.and_then(|slab| slab.get(offset)) {
slot.try_clear_storage(gen, offset, free_list)
} else {
false
}
})
}
pub(crate) fn clear>(
&self,
addr: Addr,
gen: slot::Generation,
free_list: &F,
) -> bool {
let offset = addr.offset() - self.prev_sz;
test_println!("-> offset {:?}", offset);
self.slab.with(|slab| {
let slab = unsafe { &*slab }.as_ref();
if let Some(slot) = slab.and_then(|slab| slab.get(offset)) {
slot.clear_storage(gen, offset, free_list)
} else {
false
}
})
}
}
impl fmt::Debug for Local {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
self.head.with(|head| {
let head = unsafe { *head };
f.debug_struct("Local")
.field("head", &format_args!("{:#0x}", head))
.finish()
})
}
}
impl fmt::Debug for Shared {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.debug_struct("Shared")
.field("remote", &self.remote)
.field("prev_sz", &self.prev_sz)
.field("size", &self.size)
// .field("slab", &self.slab)
.finish()
}
}
impl fmt::Debug for Addr {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.debug_struct("Addr")
.field("addr", &format_args!("{:#0x}", &self.addr))
.field("index", &self.index())
.field("offset", &self.offset())
.finish()
}
}
impl PartialEq for Addr {
fn eq(&self, other: &Self) -> bool {
self.addr == other.addr
}
}
impl Eq for Addr {}
impl PartialOrd for Addr {
fn partial_cmp(&self, other: &Self) -> Option {
self.addr.partial_cmp(&other.addr)
}
}
impl Ord for Addr {
fn cmp(&self, other: &Self) -> std::cmp::Ordering {
self.addr.cmp(&other.addr)
}
}
impl Clone for Addr {
fn clone(&self) -> Self {
Self::from_usize(self.addr)
}
}
impl Copy for Addr {}
#[inline(always)]
pub(crate) fn indices(idx: usize) -> (Addr, usize) {
let addr = C::unpack_addr(idx);
(addr, addr.index())
}
#[cfg(test)]
mod test {
use super::*;
use crate::Pack;
use proptest::prelude::*;
proptest! {
#[test]
fn addr_roundtrips(pidx in 0usize..Addr::::BITS) {
let addr = Addr::::from_usize(pidx);
let packed = addr.pack(0);
assert_eq!(addr, Addr::from_packed(packed));
}
#[test]
fn gen_roundtrips(gen in 0usize..slot::Generation::::BITS) {
let gen = slot::Generation::::from_usize(gen);
let packed = gen.pack(0);
assert_eq!(gen, slot::Generation::from_packed(packed));
}
#[test]
fn page_roundtrips(
gen in 0usize..slot::Generation::::BITS,
addr in 0usize..Addr::::BITS,
) {
let gen = slot::Generation::::from_usize(gen);
let addr = Addr::::from_usize(addr);
let packed = gen.pack(addr.pack(0));
assert_eq!(addr, Addr::from_packed(packed));
assert_eq!(gen, slot::Generation::from_packed(packed));
}
}
}
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������sharded-slab-0.1.4/src/page/slot.rs�����������������������������������������������������������������0000644�0000000�0000000�00000072747�00726746425�0015262�0����������������������������������������������������������������������������������������������������ustar �����������������������������������������������������������������0000000�0000000������������������������������������������������������������������������������������������������������������������������������������������������������������������������use super::FreeList;
use crate::sync::{
atomic::{AtomicUsize, Ordering},
hint, UnsafeCell,
};
use crate::{cfg, clear::Clear, Pack, Tid};
use std::{fmt, marker::PhantomData, mem, ptr, thread};
pub(crate) struct Slot {
lifecycle: AtomicUsize,
/// The offset of the next item on the free list.
next: UnsafeCell,
/// The data stored in the slot.
item: UnsafeCell,
_cfg: PhantomData,
}
#[derive(Debug)]
pub(crate) struct Guard {
slot: ptr::NonNull>,
}
#[derive(Debug)]
pub(crate) struct InitGuard {
slot: ptr::NonNull>,
curr_lifecycle: usize,
released: bool,
}
#[repr(transparent)]
pub(crate) struct Generation {
value: usize,
_cfg: PhantomData,
}
#[repr(transparent)]
pub(crate) struct RefCount {
value: usize,
_cfg: PhantomData,
}
pub(crate) struct Lifecycle {
state: State,
_cfg: PhantomData,
}
struct LifecycleGen(Generation);
#[derive(Debug, Eq, PartialEq, Copy, Clone)]
#[repr(usize)]
enum State {
Present = 0b00,
Marked = 0b01,
Removing = 0b11,
}
impl Pack for Generation {
/// Use all the remaining bits in the word for the generation counter, minus
/// any bits reserved by the user.
const LEN: usize = (cfg::WIDTH - C::RESERVED_BITS) - Self::SHIFT;
type Prev = Tid;
#[inline(always)]
fn from_usize(u: usize) -> Self {
debug_assert!(u <= Self::BITS);
Self::new(u)
}
#[inline(always)]
fn as_usize(&self) -> usize {
self.value
}
}
impl Generation {
fn new(value: usize) -> Self {
Self {
value,
_cfg: PhantomData,
}
}
}
// Slot methods which should work across all trait bounds
impl Slot
where
C: cfg::Config,
{
#[inline(always)]
pub(super) fn next(&self) -> usize {
self.next.with(|next| unsafe { *next })
}
#[inline(always)]
pub(crate) fn value(&self) -> &T {
self.item.with(|item| unsafe { &*item })
}
#[inline(always)]
pub(super) fn set_next(&self, next: usize) {
self.next.with_mut(|n| unsafe {
(*n) = next;
})
}
#[inline(always)]
pub(crate) fn get(&self, gen: Generation) -> Option> {
let mut lifecycle = self.lifecycle.load(Ordering::Acquire);
loop {
// Unpack the current state.
let state = Lifecycle::::from_packed(lifecycle);
let current_gen = LifecycleGen::::from_packed(lifecycle).0;
let refs = RefCount::::from_packed(lifecycle);
test_println!(
"-> get {:?}; current_gen={:?}; lifecycle={:#x}; state={:?}; refs={:?};",
gen,
current_gen,
lifecycle,
state,
refs,
);
// Is it okay to access this slot? The accessed generation must be
// current, and the slot must not be in the process of being
// removed. If we can no longer access the slot at the given
// generation, return `None`.
if gen != current_gen || state != Lifecycle::PRESENT {
test_println!("-> get: no longer exists!");
return None;
}
// Try to increment the slot's ref count by one.
let new_refs = refs.incr()?;
match self.lifecycle.compare_exchange(
lifecycle,
new_refs.pack(current_gen.pack(state.pack(0))),
Ordering::AcqRel,
Ordering::Acquire,
) {
Ok(_) => {
test_println!("-> {:?}", new_refs);
return Some(Guard {
slot: ptr::NonNull::from(self),
});
}
Err(actual) => {
// Another thread modified the slot's state before us! We
// need to retry with the new state.
//
// Since the new state may mean that the accessed generation
// is no longer valid, we'll check again on the next
// iteration of the loop.
test_println!("-> get: retrying; lifecycle={:#x};", actual);
lifecycle = actual;
}
};
}
}
/// Marks this slot to be released, returning `true` if the slot can be
/// mutated *now* and `false` otherwise.
///
/// This method checks if there are any references to this slot. If there _are_ valid
/// references, it just marks them for modification and returns and the next thread calling
/// either `clear_storage` or `remove_value` will try and modify the storage
fn mark_release(&self, gen: Generation) -> Option {
let mut lifecycle = self.lifecycle.load(Ordering::Acquire);
let mut curr_gen;
// Try to advance the slot's state to "MARKED", which indicates that it
// should be removed when it is no longer concurrently accessed.
loop {
curr_gen = LifecycleGen::from_packed(lifecycle).0;
test_println!(
"-> mark_release; gen={:?}; current_gen={:?};",
gen,
curr_gen
);
// Is the slot still at the generation we are trying to remove?
if gen != curr_gen {
return None;
}
let state = Lifecycle::::from_packed(lifecycle).state;
test_println!("-> mark_release; state={:?};", state);
match state {
State::Removing => {
test_println!("--> mark_release; cannot release (already removed!)");
return None;
}
State::Marked => {
test_println!("--> mark_release; already marked;");
break;
}
State::Present => {}
};
// Set the new state to `MARKED`.
let new_lifecycle = Lifecycle::::MARKED.pack(lifecycle);
test_println!(
"-> mark_release; old_lifecycle={:#x}; new_lifecycle={:#x};",
lifecycle,
new_lifecycle
);
match self.lifecycle.compare_exchange(
lifecycle,
new_lifecycle,
Ordering::AcqRel,
Ordering::Acquire,
) {
Ok(_) => break,
Err(actual) => {
test_println!("-> mark_release; retrying");
lifecycle = actual;
}
}
}
// Unpack the current reference count to see if we can remove the slot now.
let refs = RefCount::::from_packed(lifecycle);
test_println!("-> mark_release: marked; refs={:?};", refs);
// Are there currently outstanding references to the slot? If so, it
// will have to be removed when those references are dropped.
Some(refs.value == 0)
}
/// Mutates this slot.
///
/// This method spins until no references to this slot are left, and calls the mutator
fn release_with(&self, gen: Generation, offset: usize, free: &F, mutator: M) -> R
where
F: FreeList,
M: FnOnce(Option<&mut T>) -> R,
{
let mut lifecycle = self.lifecycle.load(Ordering::Acquire);
let mut advanced = false;
// Exponential spin backoff while waiting for the slot to be released.
let mut spin_exp = 0;
let next_gen = gen.advance();
loop {
let current_gen = Generation::from_packed(lifecycle);
test_println!("-> release_with; lifecycle={:#x}; expected_gen={:?}; current_gen={:?}; next_gen={:?};",
lifecycle,
gen,
current_gen,
next_gen
);
// First, make sure we are actually able to remove the value.
// If we're going to remove the value, the generation has to match
// the value that `remove_value` was called with...unless we've
// already stored the new generation.
if (!advanced) && gen != current_gen {
test_println!("-> already removed!");
return mutator(None);
}
match self.lifecycle.compare_exchange(
lifecycle,
next_gen.pack(lifecycle),
Ordering::AcqRel,
Ordering::Acquire,
) {
Ok(actual) => {
// If we're in this state, we have successfully advanced to
// the next generation.
advanced = true;
// Make sure that there are no outstanding references.
let refs = RefCount::::from_packed(actual);
test_println!("-> advanced gen; lifecycle={:#x}; refs={:?};", actual, refs);
if refs.value == 0 {
test_println!("-> ok to remove!");
// safety: we've modified the generation of this slot and any other thread
// calling this method will exit out at the generation check above in the
// next iteraton of the loop.
let value = self
.item
.with_mut(|item| mutator(Some(unsafe { &mut *item })));
free.push(offset, self);
return value;
}
// Otherwise, a reference must be dropped before we can
// remove the value. Spin here until there are no refs remaining...
test_println!("-> refs={:?}; spin...", refs);
// Back off, spinning and possibly yielding.
exponential_backoff(&mut spin_exp);
}
Err(actual) => {
test_println!("-> retrying; lifecycle={:#x};", actual);
lifecycle = actual;
// The state changed; reset the spin backoff.
spin_exp = 0;
}
}
}
}
/// Initialize a slot
///
/// This method initializes and sets up the state for a slot. When being used in `Pool`, we
/// only need to ensure that the `Slot` is in the right `state, while when being used in a
/// `Slab` we want to insert a value into it, as the memory is not initialized
pub(crate) fn init(&self) -> Option> {
// Load the current lifecycle state.
let lifecycle = self.lifecycle.load(Ordering::Acquire);
let gen = LifecycleGen::::from_packed(lifecycle).0;
let refs = RefCount::::from_packed(lifecycle);
test_println!(
"-> initialize_state; state={:?}; gen={:?}; refs={:?};",
Lifecycle::::from_packed(lifecycle),
gen,
refs,
);
if refs.value != 0 {
test_println!("-> initialize while referenced! cancelling");
return None;
}
Some(InitGuard {
slot: ptr::NonNull::from(self),
curr_lifecycle: lifecycle,
released: false,
})
}
}
// Slot impl which _needs_ an `Option` for self.item, this is for `Slab` to use.
impl Slot, C>
where
C: cfg::Config,
{
fn is_empty(&self) -> bool {
self.item.with(|item| unsafe { (*item).is_none() })
}
/// Insert a value into a slot
///
/// We first initialize the state and then insert the pased in value into the slot.
#[inline]
pub(crate) fn insert(&self, value: &mut Option) -> Option